rocksdb 一些堆栈记录
07 Dec 2018
|
|
一个堆栈信息,merge_test
(gdb) bt
#0 CountMergeOperator::Merge (this=0xebe410, key=..., existing_value=0x7fffffffd350, value=..., new_value=0x7fffffffd150, logger=0xebd220)
at db/merge_test.cc:39
#1 0x00000000006123a4 in rocksdb::AssociativeMergeOperator::FullMergeV2 (this=0xebe410, merge_in=..., merge_out=0x7fffffffd1d0)
at db/merge_operator.cc:62
#2 0x000000000060d3e4 in rocksdb::MergeHelper::TimedFullMerge (merge_operator=merge_operator@entry=0xebe410, key=...,
value=value@entry=0x7fffffffd350, operands=..., result=0x7fffffffd9e0, logger=0xebd220, statistics=0x0,
env=0xbc9340 <rocksdb::Env::Default()::default_env>, result_operand=0x0, update_num_ops_stats=true) at db/merge_helper.cc:81
#3 0x0000000000604b7f in rocksdb::SaveValue (arg=0x7fffffffd550, entry=<optimized out>) at db/memtable.cc:735
#4 0x00000000006a81ea in rocksdb::(anonymous namespace)::SkipListRep::Get (this=<optimized out>, k=..., callback_args=0x7fffffffd550,
callback_func=0x604680 <rocksdb::SaveValue(void*, char const*)>) at memtable/skiplistrep.cc:77
#5 0x0000000000603c4f in rocksdb::MemTable::Get (this=0xed7150, key=..., value=0x7fffffffd9e0, s=s@entry=0x7fffffffd9d0,
merge_context=merge_context@entry=0x7fffffffd680, range_del_agg=range_del_agg@entry=0x7fffffffd700, seq=0x7fffffffd670, read_opts=...,
callback=0x0, is_blob_index=0x0) at db/memtable.cc:856
#6 0x0000000000580822 in Get (is_blob_index=0x0, callback=0x0, read_opts=..., range_del_agg=0x7fffffffd700, merge_context=0x7fffffffd680,
s=0x7fffffffd9d0, value=<optimized out>, key=..., this=<optimized out>) at ./db/memtable.h:203
#7 rocksdb::DBImpl::GetImpl (this=0xec3730, read_options=..., column_family=<optimized out>, key=..., pinnable_val=0x7fffffffd920,
value_found=0x0, callback=0x0, is_blob_index=0x0) at db/db_impl.cc:1163
#8 0x0000000000580fb7 in rocksdb::DBImpl::Get (this=<optimized out>, read_options=..., column_family=<optimized out>, key=...,
value=<optimized out>) at db/db_impl.cc:1098
#9 0x0000000000517da5 in rocksdb::DB::Get (this=this@entry=0xec3730, options=..., column_family=0xed0800, key=...,
value=value@entry=0x7fffffffd9e0) at ./include/rocksdb/db.h:335
#10 0x00000000005196bc in Get (value=0x7fffffffd9e0, key=..., options=..., this=0xec3730) at ./include/rocksdb/db.h:345
#11 Counters::get (this=this@entry=0x7fffffffde10, key=..., value=value@entry=0x7fffffffda68) at db/merge_test.cc:172
#12 0x0000000000519a5c in Counters::assert_get (this=this@entry=0x7fffffffde10, key=...) at db/merge_test.cc:209
#13 0x000000000051296f in (anonymous namespace)::testCounters (counters=..., db=0xec3730, test_compaction=test_compaction@entry=false)
at db/merge_test.cc:280
#14 0x0000000000513c62 in (anonymous namespace)::runTest (argc=argc@entry=1, dbname=..., use_ttl=use_ttl@entry=false) at db/merge_test.cc:433
#15 0x000000000040ebe0 in main (argc=1) at db/merge_test.cc:510
#0 rocksdb::AssociativeMergeOperator::FullMergeV2 (this=0xebe410, merge_in=..., merge_out=0x7fffffffd1d0) at db/merge_operator.cc:68
#1 0x000000000060d3e4 in rocksdb::MergeHelper::TimedFullMerge (merge_operator=merge_operator@entry=0xebe410, key=..., value=value@entry=0x0,
operands=..., result=0x7fffffffd9e0, logger=0xebd220, statistics=0x0, env=0xbc9340 <rocksdb::Env::Default()::default_env>,
result_operand=0x0, update_num_ops_stats=true) at db/merge_helper.cc:81
#2 0x0000000000604e2f in rocksdb::SaveValue (arg=0x7fffffffd550, entry=<optimized out>) at db/memtable.cc:757
#3 0x00000000006a81ea in rocksdb::(anonymous namespace)::SkipListRep::Get (this=<optimized out>, k=..., callback_args=0x7fffffffd550,
callback_func=0x604680 <rocksdb::SaveValue(void*, char const*)>) at memtable/skiplistrep.cc:77
#4 0x0000000000603c4f in rocksdb::MemTable::Get (this=0xed7150, key=..., value=0x7fffffffd9e0, s=s@entry=0x7fffffffd9d0,
merge_context=merge_context@entry=0x7fffffffd680, range_del_agg=range_del_agg@entry=0x7fffffffd700, seq=0x7fffffffd670, read_opts=...,
callback=0x0, is_blob_index=0x0) at db/memtable.cc:856
#5 0x0000000000580822 in Get (is_blob_index=0x0, callback=0x0, read_opts=..., range_del_agg=0x7fffffffd700, merge_context=0x7fffffffd680,
s=0x7fffffffd9d0, value=<optimized out>, key=..., this=<optimized out>) at ./db/memtable.h:203
#6 rocksdb::DBImpl::GetImpl (this=0xec3730, read_options=..., column_family=<optimized out>, key=..., pinnable_val=0x7fffffffd920,
value_found=0x0, callback=0x0, is_blob_index=0x0) at db/db_impl.cc:1163
#7 0x0000000000580fb7 in rocksdb::DBImpl::Get (this=<optimized out>, read_options=..., column_family=<optimized out>, key=...,
value=<optimized out>) at db/db_impl.cc:1098
#8 0x0000000000517da5 in rocksdb::DB::Get (this=this@entry=0xec3730, options=..., column_family=0xed0800, key=...,
value=value@entry=0x7fffffffd9e0) at ./include/rocksdb/db.h:335
#9 0x00000000005196bc in Get (value=0x7fffffffd9e0, key=..., options=..., this=0xec3730) at ./include/rocksdb/db.h:345
#10 Counters::get (this=this@entry=0x7fffffffde10, key=..., value=value@entry=0x7fffffffda68) at db/merge_test.cc:172
#11 0x0000000000519a5c in Counters::assert_get (this=this@entry=0x7fffffffde10, key=...) at db/merge_test.cc:209
#12 0x0000000000512a1b in (anonymous namespace)::testCounters (counters=..., db=0xec3730, test_compaction=test_compaction@entry=false)
at db/merge_test.cc:292
#13 0x0000000000513c62 in (anonymous namespace)::runTest (argc=argc@entry=1, dbname=..., use_ttl=use_ttl@entry=false) at db/merge_test.cc:433
#14 0x000000000040ebe0 in main (argc=1) at db/merge_test.cc:510
get内部会调用merge _operator
#0 (anonymous namespace)::UInt64AddOperator::Merge (this=0xec1500, existing_value=0x7fffffffd140, value=..., new_value=0x7fffffffd150,
logger=0xebd220) at utilities/merge_operators/uint64add.cc:27
#1 0x00000000006123a4 in rocksdb::AssociativeMergeOperator::FullMergeV2 (this=0xebe410, merge_in=..., merge_out=0x7fffffffd1d0)
at db/merge_operator.cc:62
#2 0x000000000060d3e4 in rocksdb::MergeHelper::TimedFullMerge (merge_operator=merge_operator@entry=0xebe410, key=..., value=value@entry=0x0,
operands=..., result=0x7fffffffd9e0, logger=0xebd220, statistics=0x0, env=0xbc9340 <rocksdb::Env::Default()::default_env>,
result_operand=0x0, update_num_ops_stats=true) at db/merge_helper.cc:81
#3 0x0000000000604e2f in rocksdb::SaveValue (arg=0x7fffffffd550, entry=<optimized out>) at db/memtable.cc:757
#4 0x00000000006a81ea in rocksdb::(anonymous namespace)::SkipListRep::Get (this=<optimized out>, k=..., callback_args=0x7fffffffd550,
callback_func=0x604680 <rocksdb::SaveValue(void*, char const*)>) at memtable/skiplistrep.cc:77
#5 0x0000000000603c4f in rocksdb::MemTable::Get (this=0xed7150, key=..., value=0x7fffffffd9e0, s=s@entry=0x7fffffffd9d0,
merge_context=merge_context@entry=0x7fffffffd680, range_del_agg=range_del_agg@entry=0x7fffffffd700, seq=0x7fffffffd670, read_opts=...,
callback=0x0, is_blob_index=0x0) at db/memtable.cc:856
#6 0x0000000000580822 in Get (is_blob_index=0x0, callback=0x0, read_opts=..., range_del_agg=0x7fffffffd700, merge_context=0x7fffffffd680,
s=0x7fffffffd9d0, value=<optimized out>, key=..., this=<optimized out>) at ./db/memtable.h:203
#7 rocksdb::DBImpl::GetImpl (this=0xec3730, read_options=..., column_family=<optimized out>, key=..., pinnable_val=0x7fffffffd920,
value_found=0x0, callback=0x0, is_blob_index=0x0) at db/db_impl.cc:1163
#8 0x0000000000580fb7 in rocksdb::DBImpl::Get (this=<optimized out>, read_options=..., column_family=<optimized out>, key=...,
value=<optimized out>) at db/db_impl.cc:1098
#9 0x0000000000517da5 in rocksdb::DB::Get (this=this@entry=0xec3730, options=..., column_family=0xed0800, key=...,
value=value@entry=0x7fffffffd9e0) at ./include/rocksdb/db.h:335
#10 0x00000000005196bc in Get (value=0x7fffffffd9e0, key=..., options=..., this=0xec3730) at ./include/rocksdb/db.h:345
#11 Counters::get (this=this@entry=0x7fffffffde10, key=..., value=value@entry=0x7fffffffda68) at db/merge_test.cc:172
#12 0x0000000000519a5c in Counters::assert_get (this=this@entry=0x7fffffffde10, key=...) at db/merge_test.cc:209
#13 0x0000000000512a1b in (anonymous namespace)::testCounters (counters=..., db=0xec3730, test_compaction=test_compaction@entry=false)
at db/merge_test.cc:292
#14 0x0000000000513c62 in (anonymous namespace)::runTest (argc=argc@entry=1, dbname=..., use_ttl=use_ttl@entry=false) at db/merge_test.cc:433
#15 0x000000000040ebe0 in main (argc=1) at db/merge_test.cc:510
iter
#0 CountMergeOperator::Merge (this=0xd79bc0, key=..., existing_value=0x7fffffffd7d0, value=..., new_value=0x7fffffffd4c0, logger=0xeab050)
at db/merge_test.cc:44
#1 0x000000000060ded4 in rocksdb::AssociativeMergeOperator::FullMergeV2 (this=0xd79bc0, merge_in=..., merge_out=0x7fffffffd540)
at db/merge_operator.cc:62
#2 0x0000000000608f74 in rocksdb::MergeHelper::TimedFullMerge (merge_operator=0xd79bc0, key=..., value=value@entry=0x7fffffffd7d0,
operands=..., result=0x7fffe0000a40, logger=0xeab050, statistics=0x0, env=0xbb8260 <rocksdb::Env::Default()::default_env>,
result_operand=0x7fffe0000a60, update_num_ops_stats=true) at db/merge_helper.cc:81
#3 0x00000000005c7c45 in rocksdb::DBIter::MergeValuesNewToOld (this=this@entry=0x7fffe0000960) at db/db_iter.cc:657
#4 0x00000000005c9070 in rocksdb::DBIter::FindNextUserEntryInternal (this=this@entry=0x7fffe0000960, skipping=skipping@entry=false,
prefix_check=prefix_check@entry=false) at db/db_iter.cc:551
#5 0x00000000005ce37e in rocksdb::DBIter::FindNextUserEntry (this=0x7fffe0000960, skipping=<optimized out>, prefix_check=<optimized out>)
at db/db_iter.cc:410
#6 0x00000000005c9f84 in rocksdb::DBIter::SeekToFirst (this=0x7fffe0000960) at db/db_iter.cc:1366
#7 0x000000000050e9e6 in (anonymous namespace)::dumpDb (db=db@entry=0xea9520) at db/merge_test.cc:250
#8 0x000000000050ed5a in (anonymous namespace)::testCounters (counters=..., db=0xea9520, test_compaction=test_compaction@entry=false)
at db/merge_test.cc:280
#9 0x000000000050fff4 in (anonymous namespace)::runTest (argc=argc@entry=1, dbname=..., use_ttl=use_ttl@entry=false) at db/merge_test.cc:431
#10 0x000000000040ebc0 in main (argc=1) at db/merge_test.cc:508
dumpdb
0 CountMergeOperator::Merge (this=0xd79bc0, key=..., existing_value=0x7fffffffd540, value=..., new_value=0x7fffffffd550, logger=0xeab050)
at db/merge_test.cc:44
#1 0x000000000060ded4 in rocksdb::AssociativeMergeOperator::FullMergeV2 (this=0xd79bc0, merge_in=..., merge_out=0x7fffffffd5d0)
at db/merge_operator.cc:62
#2 0x0000000000608f74 in rocksdb::MergeHelper::TimedFullMerge (merge_operator=0xd79bc0, key=..., value=value@entry=0x0, operands=...,
result=0x7fffe0000a40, logger=0xeab050, statistics=0x0, env=0xbb8260 <rocksdb::Env::Default()::default_env>, result_operand=0x7fffe0000a60,
update_num_ops_stats=true) at db/merge_helper.cc:81
#3 0x00000000005c7ae1 in rocksdb::DBIter::MergeValuesNewToOld (this=this@entry=0x7fffe0000960) at db/db_iter.cc:704
#4 0x00000000005c9070 in rocksdb::DBIter::FindNextUserEntryInternal (this=this@entry=0x7fffe0000960, skipping=skipping@entry=true,
prefix_check=prefix_check@entry=false) at db/db_iter.cc:551
#5 0x00000000005c93b5 in FindNextUserEntry (prefix_check=false, skipping=true, this=0x7fffe0000960) at db/db_iter.cc:410
#6 rocksdb::DBIter::Next (this=0x7fffe0000960) at db/db_iter.cc:384
#7 0x000000000050ea1d in (anonymous namespace)::dumpDb (db=db@entry=0xea9520) at db/merge_test.cc:250
#8 0x000000000050ee14 in (anonymous namespace)::testCounters (counters=..., db=0xea9520, test_compaction=test_compaction@entry=false)
at db/merge_test.cc:293
#9 0x000000000050fff4 in (anonymous namespace)::runTest (argc=argc@entry=1, dbname=..., use_ttl=use_ttl@entry=false) at db/merge_test.cc:431
#10 0x000000000040ebc0 in main (argc=1) at db/merge_test.cc:508
merge
#0 CountMergeOperator::Merge (this=0x7fffe0001320, key=..., existing_value=0x7fffffffc520, value=..., new_value=0x7fffffffc530,
logger=0x7fffe00034b0) at db/merge_test.cc:44
#1 0x000000000060ded4 in rocksdb::AssociativeMergeOperator::FullMergeV2 (this=0x7fffe0001320, merge_in=..., merge_out=0x7fffffffc5b0)
at db/merge_operator.cc:62
#2 0x0000000000608f74 in rocksdb::MergeHelper::TimedFullMerge (merge_operator=0x7fffe0001320, key=..., value=value@entry=0x7fffffffc730,
operands=..., result=0x7fffffffcdb0, logger=0x7fffe00034b0, statistics=0x0, env=0xbb8260 <rocksdb::Env::Default()::default_env>,
result_operand=0x0, update_num_ops_stats=true) at db/merge_helper.cc:81
#3 0x0000000000600877 in rocksdb::SaveValue (arg=0x7fffffffc930, entry=<optimized out>) at db/memtable.cc:709
#4 0x00000000006a369a in rocksdb::(anonymous namespace)::SkipListRep::Get (this=<optimized out>, k=..., callback_args=0x7fffffffc930,
callback_func=0x6000c0 <rocksdb::SaveValue(void*, char const*)>) at memtable/skiplistrep.cc:77
#5 0x00000000005ff6df in rocksdb::MemTable::Get (this=0x7fffe0013a80, key=..., value=0x7fffffffcdb0, s=s@entry=0x7fffffffcd50,
merge_context=merge_context@entry=0x7fffffffca60, range_del_agg=range_del_agg@entry=0x7fffffffcae0, seq=0x7fffffffca50, read_opts=...,
callback=0x0, is_blob_index=0x0) at db/memtable.cc:830
#6 0x000000000057c8fb in Get (is_blob_index=0x0, callback=0x0, read_opts=..., range_del_agg=0x7fffffffcae0, merge_context=0x7fffffffca60,
s=0x7fffffffcd50, value=<optimized out>, key=..., this=<optimized out>) at ./db/memtable.h:203
#7 rocksdb::DBImpl::GetImpl (this=0x7fffe0002510, read_options=..., column_family=<optimized out>, key=..., pinnable_val=0x7fffffffce90,
value_found=0x0, callback=0x0, is_blob_index=0x0) at db/db_impl.cc:1145
#8 0x000000000057d067 in rocksdb::DBImpl::Get (this=<optimized out>, read_options=..., column_family=<optimized out>, key=...,
value=<optimized out>) at db/db_impl.cc:1084
#9 0x00000000006652cd in Get (value=0x7fffffffcdb0, key=..., column_family=0x7fffe000e8b8, options=..., this=0x7fffe0002510)
at ./include/rocksdb/db.h:335
#10 rocksdb::MemTableInserter::MergeCF (this=0x7fffffffd170, column_family_id=0, key=..., value=...) at db/write_batch.cc:1497
#11 0x000000000065e491 in rocksdb::WriteBatch::Iterate (this=0x7fffffffd910, handler=handler@entry=0x7fffffffd170) at db/write_batch.cc:479
#12 0x00000000006623cf in rocksdb::WriteBatchInternal::InsertInto (write_group=..., sequence=sequence@entry=21, memtables=<optimized out>,
flush_scheduler=flush_scheduler@entry=0x7fffe0002e80, ignore_missing_column_families=<optimized out>, recovery_log_number=0,
db=0x7fffe0002510, concurrent_memtable_writes=false, seq_per_batch=false) at db/write_batch.cc:1731
#13 0x00000000005c203c in rocksdb::DBImpl::WriteImpl (this=0x7fffe0002510, write_options=..., my_batch=<optimized out>,
callback=callback@entry=0x0, log_used=log_used@entry=0x0, log_ref=0, disable_memtable=false, seq_used=0x0, batch_cnt=0,
pre_release_callback=0x0) at db/db_impl_write.cc:309
#14 0x00000000005c24c1 in rocksdb::DBImpl::Write (this=<optimized out>, write_options=..., my_batch=<optimized out>) at db/db_impl_write.cc:54
#15 0x00000000005c2972 in rocksdb::DB::Merge (this=this@entry=0x7fffe0002510, opt=..., column_family=column_family@entry=0x7fffe000ebf0,
key=..., value=...) at db/db_impl_write.cc:1501
#16 0x00000000005c2a2f in rocksdb::DBImpl::Merge (this=0x7fffe0002510, o=..., column_family=0x7fffe000ebf0, key=..., val=...)
at db/db_impl_write.cc:33
#17 0x0000000000512ecd in rocksdb::DB::Merge (this=0x7fffe0002510, options=..., key=..., value=...) at ./include/rocksdb/db.h:312
#18 0x00000000005121f8 in MergeBasedCounters::add (this=<optimized out>, key=..., value=<optimized out>) at db/merge_test.cc:236
---Type <return> to continue, or q <return> to quit---
#19 0x000000000050eda0 in assert_add (value=18, key=..., this=0x7fffffffdda0) at db/merge_test.cc:214
#20 (anonymous namespace)::testCounters (counters=..., db=0x7fffe0002510, test_compaction=test_compaction@entry=false) at db/merge_test.cc:287
#21 0x0000000000510119 in (anonymous namespace)::runTest (argc=argc@entry=1, dbname=..., use_ttl=use_ttl@entry=false) at db/merge_test.cc:442
#22 0x000000000040ebc0 in main (argc=1) at db/merge_test.cc:508
reference
- 官方文档 https://github.com/facebook/rocksdb/wiki/Merge-Operator
- 上面的一个翻译https://www.jianshu.com/p/e13338a3f161
或者到博客上提issue 我能收到邮件提醒。







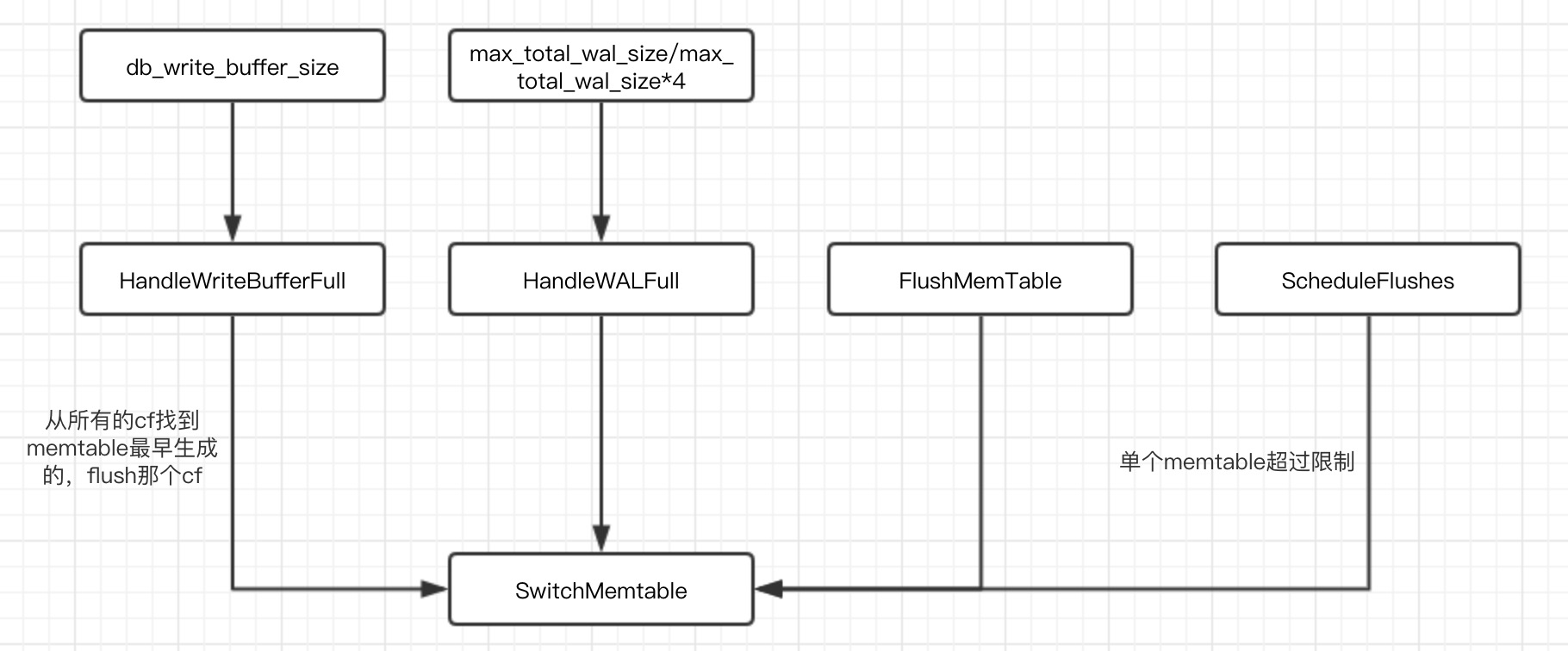 ScheduleFlushes
ScheduleFlushes