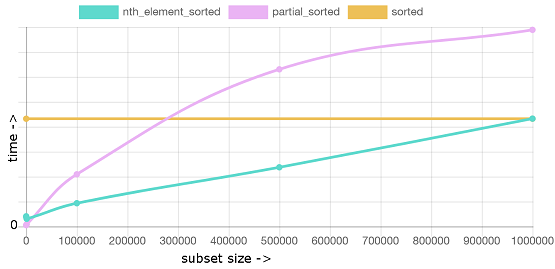
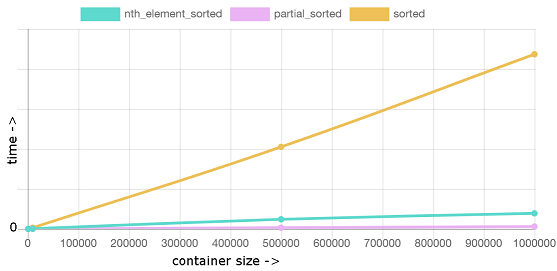
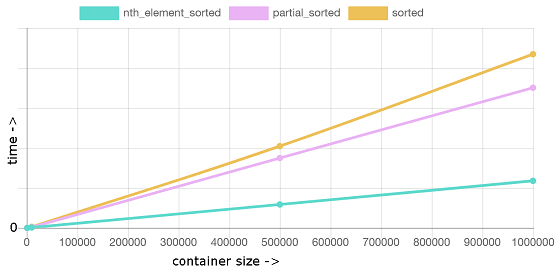
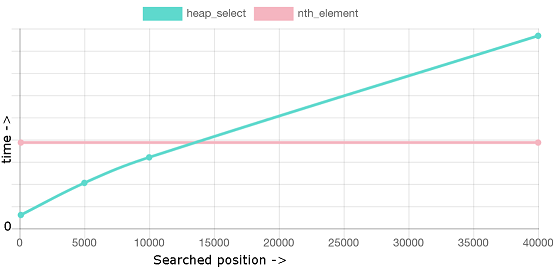
occ,2pl 以及其他概念
why
补课
数据库并发控制(Concurrency Control)实现,锁和时间序
基于锁,也就是 Two Phrase Locking,2PL
2PL
- Growing Phrase 获取锁 事务内修改,而不会导致冲突
- Shrinking Phrase 释放锁
缺陷,业务依赖性死锁,无法避免。
基于时间戳,可以实现乐观并发控制(OCC,Optimistic Concurrency Control)和MVCC
时间序,默认事务不冲突,检查时间超前,事务失败。
- Read Phase,或者叫execute phase更合适,读,Read Set,写 写入临时副本,放到Write Set
- Validation Phase,重扫 Read Set, Write Set, 验证隔离级别,满足commit,否则abort
- Write Phase,叫Commit Phase更合适, 提交
而MVCC有多种实现,通常都是多快照+时间戳维护可见性,两种实现
- MV-2PC mysql
- MV-TO, postgresql (SSI)
主要操作
- Update 创建一个version
- Delete,更新End timestamp
- Read,通过Begin End timestamp判断可见性
快照保证读写不阻塞,为了串行化还是要限制读写顺序
隔离程度以及影响
影响 :脏读 不可重复读 幻读 更新丢失
隔离程度
| 串行化 | 可重复读RR | 提交读RC | 未提交度RU |
|---|---|---|---|
| 幻读 | 不可重复读,幻读 | 脏读,不可重复读,幻读 |
快照隔离(SI) 串行化
Snapshot Isolation 在 Snapshot Isolation 下,不会出现脏读、不可重复度和幻读三种读异常。并且读操作不会被阻塞,对于读多写少的应用 Snapshot Isolation 是非常好的选择。并且,在很多应用场景下,Snapshot Isolation 下的并发事务并不会导致数据异常。所以,主流数据库都实现了 Snapshot Isolation,比如 Oracle、SQL Server、PostgreSQL、TiDB、CockroachDB
虽然大部分应用场景下,Snapshot Isolation 可以很好地运行,但是 Snapshot Isolation 依然没有达到可串行化的隔离级别,因为它会出现写偏序(write skew)。Write skew 本质上是并发事务之间出现了读写冲突(读写冲突不一定会导致 write skew,但是发生 write skew 时肯定有读写冲突),但是 Snapshot Isolation 在事务提交时只检查了写写冲突。
为了避免 write skew,应用程序必须根据具体的情况去做适配,比如使用SELECT … FOR UPDATE,或者在应用层引入写写冲突。这样做相当于把数据库事务的一份工作扔给了应用层。 Serializable Snapshot Isolation 后来,又有人提出了基于 Snapshot Isolation 的可串行化 —— Serializable Snapshot Isolation,简称 SSI(PostgreSQL 和 CockroachDB 已经支持 SSI)。 为了分析 Snapshot Isolation 下的事务调度可串行化问题,有论文提出了一种叫做 Dependency Serialization Graph (DSG) 的方法(可以参考下面提到的论文,没有深究原始出处)。通过分析事务之间的 rw、wr、ww 依赖关系,可以形成一个有向图。如果图中无环,说明这种情况下的事务调度顺序是可串行化的。这个算法理论上很完美,但是有一个很致命的缺点,就是复杂度比较高,难以用于工业生产环境。
Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions 证明在 Snapshot Isolation 下, DSG 形成的环肯定有两条 rw-dependency 的边。 Making snapshot isolation serializable 再进一步证明,这两条 rw-dependency 的边是“连续”的(一进一出)。 后来,Serializable Isolation for snapshot database 在 Berkeley DB 的 Snapshot Isolation 之上,增加对事务 rw-dependency 的检测,当发现有两条“连续”的 rw-dependency 时,终止其中一个事务,以此避免出现不可串行化的可能。但是这个算法会有误判——不可以串行化的事务调用会出现两条“连续”的 rw-dependency 的边,但是出现两条“连续”的 rw-dependency 不一定会导致不可串行化。
Serializable Snapshot Isolation in PostgreSQL 描述了上述算法在 PostgreSQL 中的实现。 上面提到的 Berkeley DB 和 PostgreSQL 的 SSI 实现都是单机的存储。A Critique of Snapshot Isolation 描述了如何在分布式存储系统上实现 SSI,基本思想就是通过一个中心化的控制节点,对所有 rw-dependency 进行检查,有兴趣的可以参考论文。
读写冲突,写写冲突,写偏序,黑白球,串行化,以及SSI
参考链接19
occ silo见参考链接12,有很多细节,epoch,memory fence,masstree,occ等
或者到博客上提issue 我能收到邮件提醒。
reference
- 隔离级别,SI,SSI https://www.jianshu.com/p/c348f68fecde
- mysql 各种读 https://www.jianshu.com/p/69fd2ca17cfd
- occ mvcc区别 https://www.zhihu.com/question/60278698
- 并发控制的前世今生? http://www.vldb.org/pvldb/vol8/p209-yu.pdf
- 数据库管理系统,并发控制简介 https://zhuanlan.zhihu.com/p/20550159
- myrocks 事务实现 http://mysql.taobao.org/monthly/2016/11/02/
- myrocks ddl https://www.cnblogs.com/cchust/p/6716823.html
- rocksdb transactiondb分析https://yq.aliyun.com/articles/257424
- cockroachdb 用rocksdb(后半段)https://blog.csdn.net/qq_38125183/article/details/81591285
- cockroachdb 用rocksdb http://www.cockroachchina.cn/?p=1242
- rocksdb 上锁机制 上面的文章也提到了相关的死锁检测https://www.cnblogs.com/cchust/p/7107392.html
- occ-silo 讲occ高性能https://www.tuicool.com/articles/VZVFnaR
- 分布式事务,文章不错http://www.zenlife.tk/distributed-transaction.md
- 再谈事务隔离性 https://cloud.tencent.com/developer/news/233615
- 事务隔离级别SI到RC http://www.zenlife.tk/si-rc.md
- mvcc事务机制,SI http://www.nosqlnotes.com/technotes/mvcc-snapshot-isolation/
- mvcc事务机制,逻辑时钟 http://www.nosqlnotes.com/technotes/mvcc-logicalclock/
- mvcc 混合逻辑时钟http://www.nosqlnotes.com/technotes/mvcc-hybridclock/
- cockroach mvcc http://www.nosqlnotes.com/technotes/cockroach-mvcc/