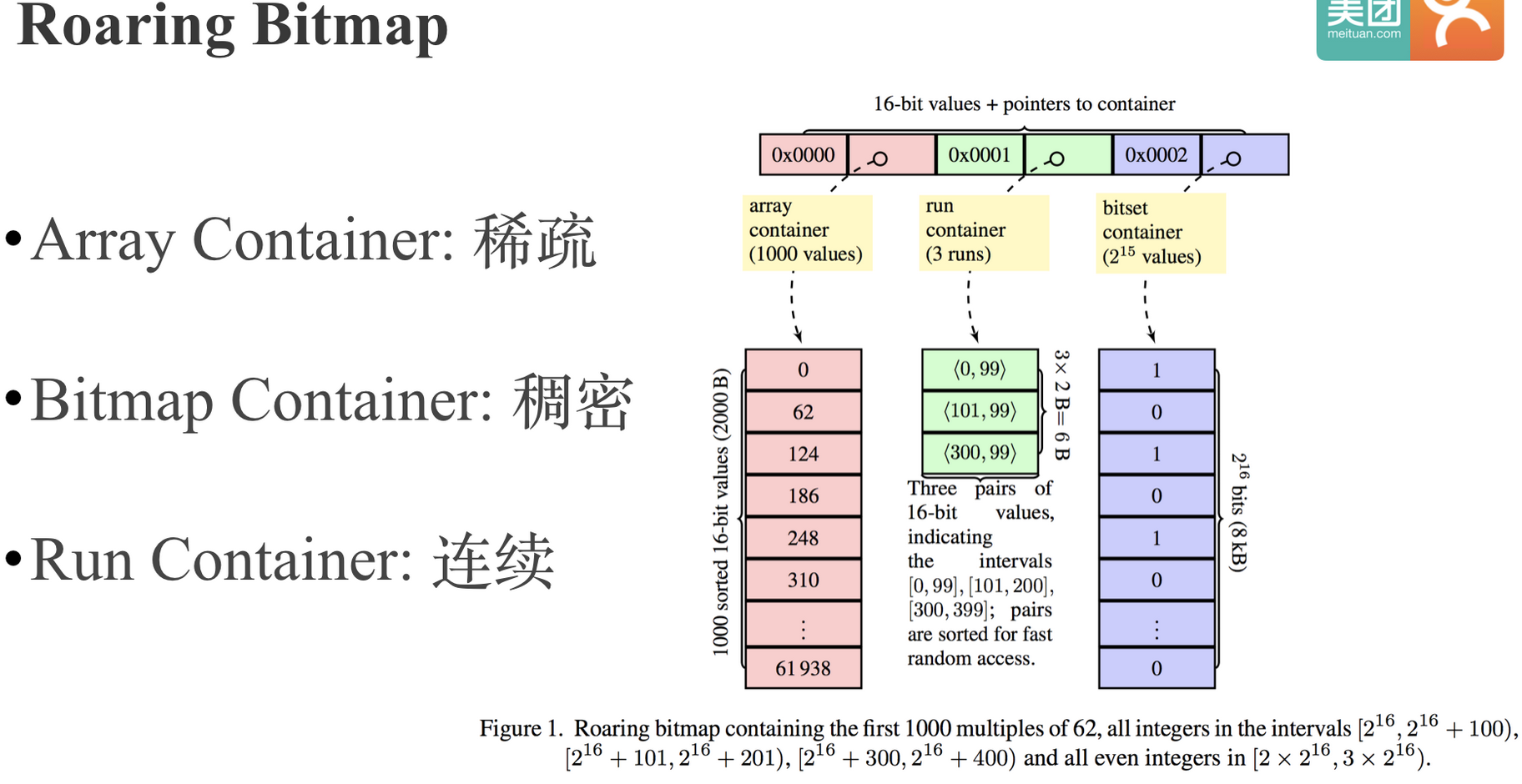
这是翻译整理
一张图概括改动点

Scan Resistant Cache
这个概念我不知道怎么翻译,总之就是一个能够抗住Scan动作污染的cache
yugabytedb针对rocksdb lru cache的缺陷,做了个优化 https://github.com/YugaByte/yugabyte-db/commit/0c6a3f018ac90724ac1106ff248c051afbdd6979
作者也说了,这个实现和mysql/hbase类似,是2Q
我的疑问
- 为啥rocksdb不加上?找到了一个commit,没看出来加在哪里了 https://github.com/facebook/rocksdb/commit/6e78fe3c8d35fa1c0836af4501e0f272bc363bab
- 实现Scan Resistant cache需要做什么?2Q ARC都是怎么抵消影响的?
Block-based Splitting of Bloom/Index Data
rocksdb的sst文件包含元数据,比如index和bloom filter。作者观点这个数据是没有必要的,可以砍掉了,毕竟都在内存里 修改在这里https://github.com/YugaByte/yugabyte-db/commit/147312863b104d2d4b2f267cbb6b4fc95f35f3a8
Multiple Instances of RocksDB Per Node
多rocksdb实例。这个很常见,作者列出来几个设计优势
- 集群节点的负载均衡 节点failover 添加节点都变的非常简单,可以直接搬迁sst文件。
- 删掉表直接删掉rocksdb实例
- 可以对一个表做不同的存储策略,压缩开关?压缩算法自定义?编码自定义(前缀etc)
- 可以对一个表做不通的布隆过滤侧率,不同主键,不同桶数etc
- 。。。还有一个和yogabyte db业务相关,没看懂,没翻译 Allows DocDB to track min/max values for each clustered column in the primary key of a table (another enhancement to RocksDB) and store that in the corresponding SSTable file as metadata. This enables YugabyteDB to optimize range predicate queries like by minimizing the number of SSTable files that need to be looked up:
但是这种用法工程实践上的坑需要注意
全局block cache
writebuffer memtable wal大小限制
过大重启重放日志会很痛苦,这里yugabyte db做了改进,尽可能的刷数据 https://github.com/YugaByte/yugabyte-db/commit/faed8f0cd55e25f2e72c39fffa72c27c5f84fca3
针对不同规模的compaction做分类,不同的队列来做
改进在这里https://github.com/YugaByte/yugabyte-db/commit/dde2ecd5ddf4b01879e32f033e0a80e37e18341a
- 事实上有观点认为应该把linux调度算法搬到这里。rocksdb的compaction策略粗糙,而两个队列算是个粗糙调度
Smart Load Balancing Across Multiple Disks 这个没看懂
DocDB supports a just-a-bunch-of-disks (JBOD) setup of multiple SSDs and doesn’t require a hardware or software RAID. The RocksDB instances for various tablets are balanced across the available SSDs uniformly, on a per-table basis to ensure that each SSD has a similar number of tablets from each table and is taking uniform type of load. Other types of load balancing in DocDB are also done on a per-table basis, be it:
- Balancing of tablet replicas across nodes
- Balancing of leader/followers of Raft groups across nodes
- Balancing of Raft logs across SSDs on a node
附加改动
用raft替代rocksdb的wal
mvcc
用的混合逻辑时钟
Hybrid Logical Clock (HLC), the hybrid timestamp assignment algorithm, is a way to assign timestamps in a distributed system such that every pair of “causally connected” events results in an increase of the timestamp value. Please refer to these reports (#1 or #2) for more details.
参考
- 原文 https://blog.yugabyte.com/enhancing-rocksdb-for-speed-scale/
- 这个是arc介绍,效果优于lru http://hcoona.github.io/Paper-Note/arc-one-up-on-lru/
- 论文原文https://www.usenix.org/conference/fast-03/arc-self-tuning-low-overhead-replacement-cache
- 据说zfs也用。
- 搜到的一个issue,建议kudu替换他们的cache系统,换成arc或者hbase 2Q,https://issues.apache.org/jira/browse/KUDU-613
- scan resistant cache貌似是个热点问题?搜关键字蹦出好几个论文。不列举了。
- 这里有个2Q的介绍 https://flak.tedunangst.com/post/2Q-buffer-cache-algorithm 值得翻译一下