Apache Kafka源码剖析笔记
特点
- Kafka具有近乎实时性的消息处理能力,即使面对海量消息也能够高效地存储消息和查询消息。
- Kafka将消息保存在磁盘中,在其设计理念中并不惧怕磁盘操作,它以顺序读写的方式访问磁盘, 从而避免了随机读写磁盘导致的性能瓶颈。
- Kafka支持批量读写消息,并且会对消息进行批量压缩,这样既提高了网络的利用率,也提高了压 缩效率。
- Kafka支持消息分区,每个分区中的消息保证顺序传输,而分区之间则可以并发操作,这样就提高 了Kafka的并发能力。
- Kafka也支持在线增加分区,支持在线水平扩展。
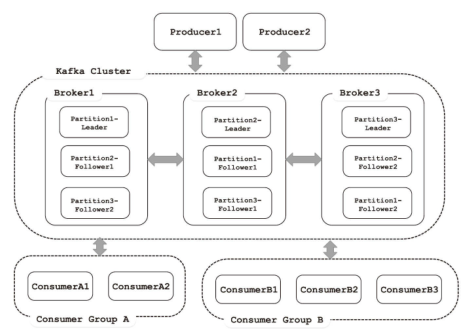
- Kafka支持为每个分区创建多个副本,其中只会有一个Leader副本负责读写,其他副本只负责与 Leader副本进行同步,这种方式提高了数据的容灾能力。Kafka会将Leader副本均匀地分布在集群 中的服务器上,实现性能最大化
为什么引入mq中间件,以及,原有方案的弊端
- 由于子系统之间存在的耦合性,两个存储之间要进行数据交换的话,开发人员就必须了解这两个 存储系统的API,不仅是开发成本,就连维护成本也会很高。一旦其中一个子系统发生变化,就可 能影响其他多个子系统,这简直就是一场灾难。
- 在某些应用场景中,数据的顺序性尤为重要,一旦数据出现乱序,就会影响最终的计算结果,降 低用户体验,这就提高了开发的难度。
- 除了考虑数据顺序性的要求,还要考虑数据重传等提高可靠性的机制,毕竟通过网络进行传输并 不可靠,可能出现丢失数据的情况。
- 进行数据交换的两个子系统,无论哪一方宕机,重新上线之后,都应该恢复到之前的传输位置, 继续传输。尤其是对于非幂等性的操作,恢复到错误的传输位置,就会导致错误的结果。
- 随着业务量的增长,系统之间交换的数据量会不断地增长,水平可扩展的数据传输方式就显得尤 为重要。
应对的解决方案
- 中间件解耦
- 数据持久化
- 扩展与容灾
- topic,partition,replica
- 多个consumer消费,各自记录消费标签信息,由consumer决定cursor
核心概念
- 消息
- topic/partition/log
- partition offset保证顺序性
- partition 用Log表述,大小有限,可以分节,顺序io追加,不会有性能问题
- 索引文件 稀疏索引 内存中定位加速
- 保留策略 顺序写总会写满,设置消息保留时间或者总体大小
- 日志压缩 类似rocksdb compaction
- Broker kafka server概念,接受生产者的消息,分配offset保存到磁盘中
- 副本(并不是实时同步)
- ISR集合,可用的没有lag太多的可升leader的节点的集合
- HighWatermar LEO,描述可消费的属性
- ①Producer向此Partition推送消息。
- ②Leader副本将消息追加到Log中,并递增其LEO。
- ③Follower副本从Leader副本拉取消息进行同步。
- ④Follower副本将拉取到的消息更新到本地Log中,并递增其LEO。
- ⑤当ISR集合中所有副本都完成了对offset=11的消息的同步,Leader副本会递增HW。
- 在①~⑤步完成之后,offset=11的消息就对生产者可见了。
- 消费者,消费组、
细心的读者可能会问,为什么GZIP压缩方式会直接使用new创建,而Snappy则使用反射方式呢?这主要是因为GZIP使用的GZIPOutputStream是JDK自带的包,而Snappy则需要引入额外的依赖包,为了在不使用Snappy压缩方式时,减少依赖包,这里使用反射的方式动态创建。这种设计的小技巧,值得读者积累。在Compressor中还提供了wrapForInput()方法,用于创建解压缩输入流,逻辑与wrapForOutput()类似,不再赘述。
生产者KafkaProducer分析
同步还是异步就差在future本身调用不调用get
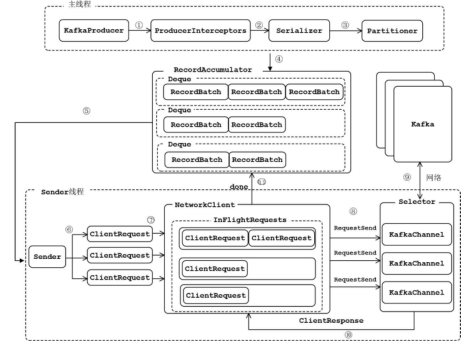
结构很清晰
KafkaProducer
- send()方法:发送消息,实际是将消息放入RecordAccumulator暂存,等待发送。
- flush()方法:刷新操作,等待RecordAccumulator中所有消息发送完成,在刷新完成之前会阻塞调用的线程。
- partitionsFor()方法:在KafkaProducer中维护了一个Metadata对象用于存储Kafka集群的元数据,Metadata中的元数据会定期更新。partitionsFor()方法负责从Metadata中获取指定Topic中的分区信息。
- topic, verison, timestamp….
- close()方法:关闭此Producer对象,主要操作是设置close标志,等待RecordAccumulator中的消息清 空,关闭Sender线程
RecordAccumulator
RecordAccumulator中有一个以TopicPartition为key的ConcurrentMap,每个value是ArrayDeque<RecordBatch>(ArrayDeque并不是线程安全的集合,后面会详细介绍其加锁处理过程),其中缓存了发往对应TopicPartition的消息。每个RecordBatch拥有一个MemoryRecords对象的引用
(1)Deque中有多个RecordBatch或是第一个RecordBatch是否满了。 (2)是否超时了。 (3)是否有其他线程在等待BufferPool释放空间(即BufferPool的空间耗尽了)。 (4)是否有线程正在等待flush操作完成。 (5)Sender线程准备关闭。
BufferPool
- 有锁。全局分配器
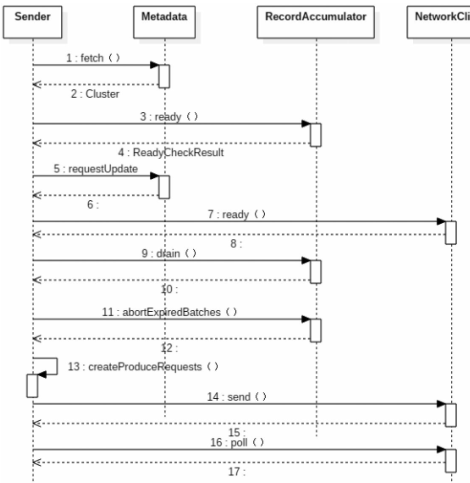
Sender
据RecordAccumulator的缓存情况,筛选出可以向哪些Node节点发送消息,
RecordAccumulator.ready();然后,根据生产者与各个节点的连接情况(由NetworkClient管理),过滤Node节点;之后,生成相应的请求,这里要特别注意的是,每个Node节点只生成一个请求;最后,调用NetWorkClient将请求发送出去
controller
http://www.sirann.cn/blog/kafka-controller-%E6%A8%A1%E5%9D%97%E4%B8%80%E6%A6%82%E8%BF%B0/
删除消息,支持按照offset SO,按照topic来删
支持时间删除和大小删除
痛点
对于单纯运行Kafka的集群而言,首先要注意的就是为Kafka设置合适(不那么大)的JVM堆大小。从上面的分析可知,Kafka的性能与堆内存关系并不大,而对page cache需求巨大。根据经验值,为Kafka分配6~8GB的堆内存就已经足足够用了,将剩下的系统内存都作为page cache空间,可以最大化I/O效率。
另一个需要特别注意的问题是lagging consumer,即那些消费速率慢、明显落后的consumer。它们要读取的数据有较大概率不在broker page cache中,因此会增加很多不必要的读盘操作。比这更坏的是,lagging consumer读取的“冷”数据仍然会进入page cache,污染了多数正常consumer要读取的“热”数据,连带着正常consumer的性能变差。在生产环境中,这个问题尤为重要。
解决方案,调整page cache https://www.jianshu.com/p/92f33aa0ff52
实时消费与延迟消费的作业在 PageCache 层次产生竞争,导致实时消费产生非预期磁盘读。线上存在 20%的延迟消费作业,污染cache
传统 HDD 随着读并发升高性能急剧下降。
解决方案
- 引入SSD 做cache https://www.infoq.cn/article/k6dqfqqihpjfepl3y3hs
- 重新设计kafka cache系统 https://www.jiqizhixin.com/articles/2019-07-23-11
优化细节
减少甚至避免用户空间和内核空间之间的数据拷贝:在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的 Page Cache 和用户进程的缓冲区之间的传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是通过增加新的系统调用来完成的,比如 Linux 中的 mmap(),sendfile() 以及 splice()
这里用的sendfile
