std::variant 与 std::visit
15 Aug 2018
|
|
why
因为rust的enum让我回想起union和 variant,决定找找文档仔细说一下这个variant,做个笔记
std::variant是c++17加入的新容器,主要就是safe union。用来和enum比较也算合适,都叫做sum type,类型是线程(求和)的,只表现出线性数目的类别实例,product type是乘积的(比如结构体),这个是函数式概念了,先做个科普
下面是一个std::visit+ std::variant的例子,同比rust中的enum match
std::variant<double, bool, std::string> var;
struct {
void operator()(int) { std::cout << "int!\n"; }
void operator()(std::string const&) { std::cout << "string!\n"; }
} visitor;
std::visit(visitor, var);
#![allow(unused_variables)]
fn main() {
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
}
差距还好。rust也可以直接调用函数 lambda。对比来说,c++需要手动写visitor有点难看。有没有make_visitor呢
overload
下面的链接有make_visitor, 就是这个overload,在cpp reference std::visit的示例中,也有使用overload这个模板,长这个样子
template<class... Ts> struct overloaded : Ts... { using Ts::operator()...; };
template<class... Ts> overloaded(Ts...) -> overloaded<Ts...>;
于是,上面的代码就变成这样
std::variant<double, bool, std::string> var;
std::visit(overloaded {
[](auto arg) { std::cout << arg << ' '; },
[](double arg) { std::cout << std::fixed << arg << ' '; },
[](const std::string& arg) { std::cout << std::quoted(arg) << ' '; },
}, var);
感觉稍微干净了点是不是?手写operator()还是有点难受的?换成lambda只能写一个,也得用overload包装一下
overload原理就是模板推导和转发,变参模板可能看不懂,写成一个继承的就容易明白了
struct overloadInt{
void operator(int arg){
std::cout<<arg<<' ';
}
};
struct overload : overloadInt{
using overloadInt::operator();
};
不用std::visit行不行
行,又要走SFINAE 老路了,enable_if 糊一个,还要判断variant里到底存了什么,基本上和visit差不多?我糊了半天糊出个这么个玩意儿。
#include <iomanip>
#include <iostream>
#include <string>
#include <type_traits>
#include <variant>
#include <vector>
template<typename T, typename VARIANT_T>
struct is_variant_member_type;
template<typename T, typename... Ts>
struct is_variant_member_type<T, std::variant<Ts...>>
: public std::disjunction<std::is_same<T, Ts>...> {};
template <typename V > typename std::enable_if<is_variant_member_type<std::string,V>::value&&
is_variant_member_type<double,V>::value>&&
is_variant_member_type<int,V>::value>::type
match (V v)
{
if (std::holds_alternative<int>(v))
std::cout << std::get<int>(v) << ' ';
if (std::holds_alternative<std::string>(v))
std::cout << std::quoted(std::get<std::string>(v)) << ' ';
if (std::holds_alternative<double>(v))
std::cout<<std::fixed << std::get<double>(v) << ' ';
}
// the variant to visit
using var_t = std::variant<int, double, std::string>;
int main() {
std::vector<var_t> vec = {10, 15l, 1.5, "hello"};
for(auto& v: vec) {
match(v);
}
}
注意,用if-constexpr不可以,虽然std::holds_alternative是constexpr的。。暂时没搞懂
感觉吧match拆一拆,拆成lambda类似形式的,可以结合overload。这个写的用不用enable_if没什么区别。。我以后再写吧。。这里学的不明白。
reference
- std::variant https://en.cppreference.com/w/cpp/utility/variant
- std::visit , 其中这个overlord模板很有意思。https://en.cppreference.com/w/cpp/utility/variant/visit
- 一个variant介绍,其中里面的 make_visitor就是上面这个overloadedhttps://pabloariasal.github.io/2018/06/26/std-variant/
- 对overload的解释 https://dev.to/tmr232/that-overloaded-trick-overloading-lambdas-in-c17
- 对overload的解释和加强,并且有提案。https://arne-mertz.de/2018/05/overload-build-a-variant-visitor-on-the-fly/
- std::visit 和std::variant https://arne-mertz.de/2018/05/modern-c-features-stdvariant-and-stdvisit/
- 讲type的,深入浅出(应该写个笔记记录下)https://github.com/CppCon/CppCon2016/blob/master/Tutorials/Using%20Types%20Effectively/Using%20Types%20Effectively%20-%20Ben%20Deane%20-%20CppCon%202016.pdf
- rust enum+match https://doc.rust-lang.org/beta/book/ch06-02-match.html
- 观点:std::visit很糟糕 https://bitbashing.io/std-visit.html
- visit 实现,里面有几个链接很有意思,https://stackoverflow.com/questions/47956335/how-does-stdvisit-work-with-stdvariant
- https://mpark.github.io/programming/2015/07/07/variant-visitation/
- https://mpark.github.io/programming/2019/01/22/variant-visitation-v2/
- http://talesofcpp.fusionfenix.com/post-17/eggs.variant—part-i
- 上面的链接有两个variant的实现。
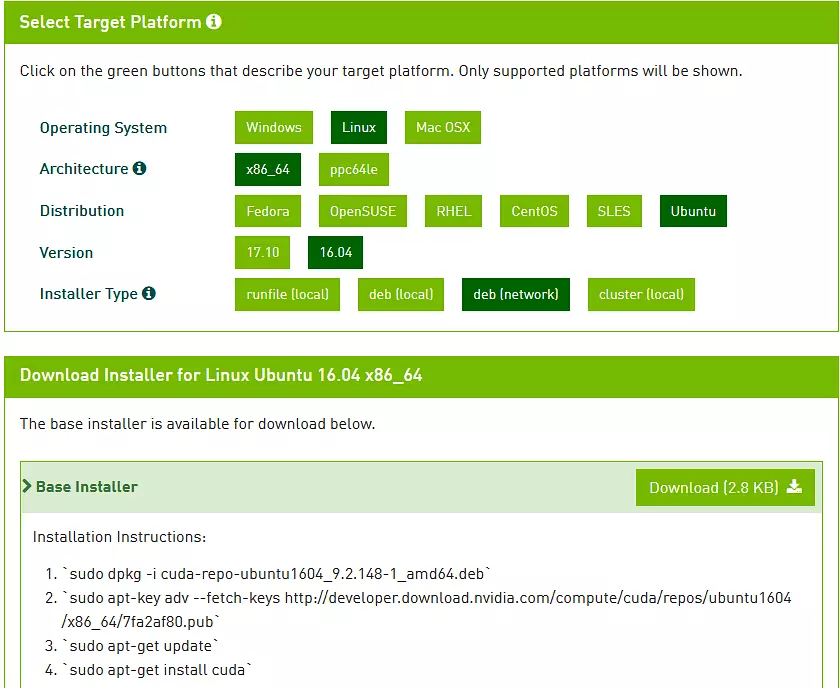

 安装CUDNN
这个没有办法,不能用命令行
安装CUDNN
这个没有办法,不能用命令行