(译)dd, bs= and why you should use conv=fsync
整理自这篇文章 https://abbbi.github.io/dd/
简单总结
If one uses dd with a bigger block size (>= 4096), be sure to use either the oflag=direct or conv=fsync option to have proper error reporting while writing data to a device. I would prefer conv=fsync, dd will then fsync() the file handle once and report the error, without having the performance impact which oflag=direct has.
用dd的时候尽可能用conv=fsync提前发现system error
作者用dd来做测试,测试盘有坏块的场景
预备工作
truncate -s 1G /tmp/baddisk
losetup /dev/loop2 /tmp/baddisk
dmsetup create baddisk << EOF
0 6050 linear /dev/loop2 0
6050 155 error
6205 2090947 linear /dev/loop2 6205
EOF
可以看到设置之后的盘的属性
fdisk -l
磁盘 /dev/loop2:1073 MB, 1073741824 字节,2097152 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
可以看到每个扇区是0.5KB
写到错误的位置,也就是6050,需要3M(6050*0.5k)所以,我们调用dd写入4M,肯定就写到错误的地方,就会有报错
但是实际上没有任何报错 算一下 4096*1000就是4M
dd if=/dev/zero of=/dev/mapper/baddisk bs=4096 count=1000
4096000 bytes (4.1 MB, 3.9 MiB) copied, 0.0107267 s, 382 MB/s
如果不指定bs就会报错,一直写
dd if=/dev/zero of=/dev/mapper/baddisk
dd: writing to '/dev/mapper/baddisk': Input/output error
3096576 bytes (3.1 MB, 3.0 MiB) copied, 0.0238947 s, 130 MB/s
抓dmesg的信息,也是有报错的
dmesg
[8807366.717526] Buffer I/O error on device dm-0, logical block 766
[8807366.718560] lost page write due to I/O error on dm-0
为什么dd命令不报错?
strace抓信息
我这里抓的是这样的
open("/dev/mapper/baddisk", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
dup2(3, 1) = 1
close(3) = 0
read(0, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096
write(1, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096
read(0, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096
可见打开文件读写都没遇到报错,如果强制加上O_DIRECT O_SYNC之类的符号,就会报错了
背后的细节问题: Linux内核buffered IO影响,有buffered IO,写入不是立即的
而且,对于buffered IO遇到的硬件异常,api是不能立刻感知到的,只有写回的时候才会感知到,所以才有这个问题
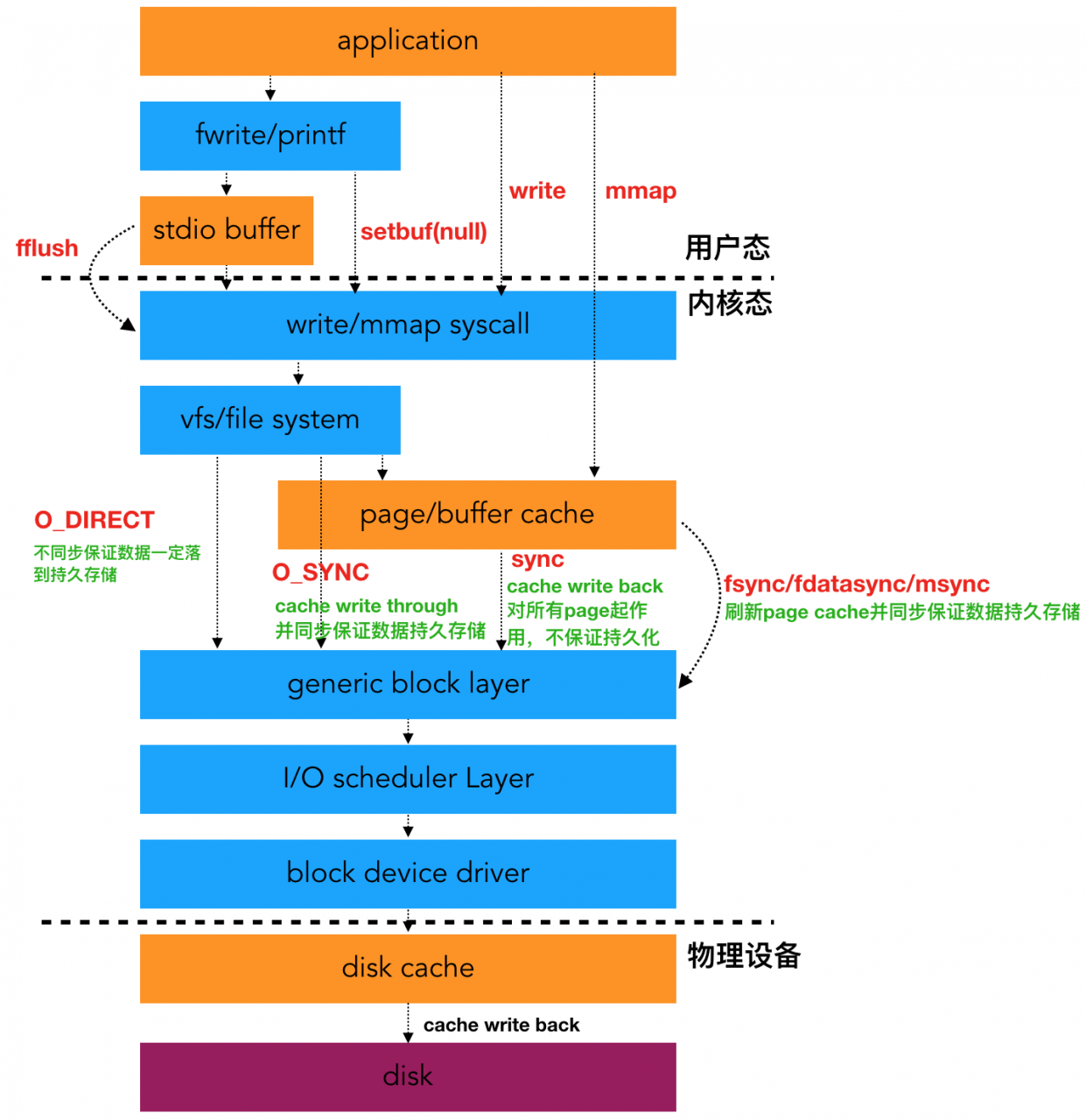
| 指定两个FLAG中的一个就解决了这个问题 ,oflag=direct慢一鞋,相当于O_SYNC | O_DIRECT组合,conv=fsync更好一些 |
buffered-io原理
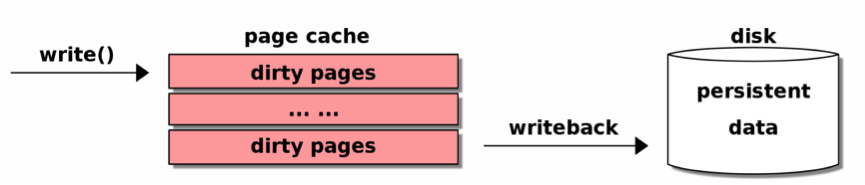
当然面对这个问题,即buffered IO写入遇到硬件层异常,在写回时才出错,如何提前感知错误,也有很多讨论
比如这个SO问题
答主Craig Ringer 也是pg开发人员,遇到了这个问题,解决方案就是用fsync要检查错误
引述一下他的回答:如果以为用fsync(循环调用fsync直到成功)就万事大吉,那就错了
换句话说如果fsync遇到错误,那就是硬件有问题,应该abort退出
which is then detected by
wait_on_page_writeback_range(...)as called bydo_sync_mapping_range(...)as called bysys_sync_file_range(...)as called bysys_sync_file_range2(...)to implement the C library callfsync().But only once!
This comment on
sys_sync_file_range168 * SYNC_FILE_RANGE_WAIT_BEFORE and SYNC_FILE_RANGE_WAIT_AFTER will detect any 169 * I/O errors or ENOSPC conditions and will return those to the caller, after 170 * clearing the EIO and ENOSPC flags in the address_space.suggests that when
fsync()returns-EIOor (undocumented in the manpage)-ENOSPC, it will clear the error state so a subsequentfsync()will report success even though the pages never got written.Sure enough
wait_on_page_writeback_range(...)clears the error bits when it tests them:301 /* Check for outstanding write errors */ 302 if (test_and_clear_bit(AS_ENOSPC, &mapping->flags)) 303 ret = -ENOSPC; 304 if (test_and_clear_bit(AS_EIO, &mapping->flags)) 305 ret = -EIO;So if the application expects it can re-try
fsync()until it succeeds and trust that the data is on-disk, it is terribly wrong.
另外在4.9之后的新内核,直接返回EIO,综上,要判定fsync返回EIO
作者的验证代码在这 https://github.com/ringerc/scrapcode/blob/fd71dffea787847d303e22db95e8b6ca23d06a6d/testcases/fsync-error-clear/standalone/fsync-error-clear.c
作者在PG的讨论串在这里https://www.postgresql.org/message-id/flat/CAMsr%2BYE5Gs9iPqw2mQ6OHt1aC5Qk5EuBFCyG%2BvzHun1EqMxyQg%40mail.gmail.com#CAMsr+YE5Gs9iPqw2mQ6OHt1aC5Qk5EuBFCyG+vzHun1EqMxyQg@mail.gmail.com
另外LWN有两个帖子
https://lwn.net/Articles/724307/
https://lwn.net/Articles/752063/
也介绍了关于这个问题相关的内核应该做的改动,更好的IO错误处理,此处不提
ref
- https://hustcat.github.io/blkcg-buffered-io/ 博客也不错,好像没做seo