rocksdb
不整理就忘了
悲报 调用图网站挂了。只能手动doc gen了。有空再搞
另外,版本是5.x,现在已经8了。应该考虑更新一编
[toc]
rocksdb的整体框架和数据模型,leveldb的整体框架,网上文章遍地都是了。细分到组件,又一大堆分析。看的头都大了。事实上我现在还是分不清的。术语看了一遍又一遍,还是卡壳,看代码,还是会忘记。感觉不用硬看不行啊。还是上图吧。
dbimpl 属性图

column family 属性图

supervision属性图

version 属性图

version set 属性图

概念
Column Family
这个不是Cassandra那个CF,就是键空间。这个用来实现多种需求,比如上层元数据拆分。这涉及到编码的定制。我也不很懂
CRUD
插入就是插入,更新是追加插入,删除也是更新,value空。支持writebatch,原子性
put https://www.jianshu.com/p/daa18eebf6e1
https://glitterisme.github.io/2018/07/03/%E6%89%8B%E6%92%95RocksDB-1/
myrocks put http://mysql.taobao.org/monthly/2017/07/05/
wirte详解? https://blog.csdn.net/wang_xijue/article/details/46521605
http://mysql.taobao.org/monthly/2018/07/04/
并发写?
http://www.pandademo.com/2016/10/parallel-write-rocksdb-source-dissect-3/
https://www.jianshu.com/p/fd7e98fd5ee6
https://youjiali1995.github.io/rocksdb/write-batch/
write stall? 什么时候会write stall?
Gets Iterators Snapshots
iterator 和snapshot是一致的。底层引用计数保证不被删除。但是这个数据是不被持久化的,对比git,这就是拉个分支,然后在分支上修改,但是这个分支信息不记录,不保存就丢,可以在这基础上创建checkpoint然后搞备份
?疑问 checkpoint实现? backupdb实现?是不是基于checkpoint
minifest
这东西就是个一个index 内部实现, 一致性保证
文件具体为
- MANIFEST-xx 内部是相关的一堆version edit
- CURRENT 记录最新的MANIFEST-xx(类似git里的head)
这里要说下version edit version set 和version
version 和versionset version这就是个snapshot snapshot这东西就是版本号啦,或者可以理解成git里的commit,每个commit都能抽出来一个分支,这就是snapshot了,version由version edit组成,version edit可以理解成 modify。git中的相关思想在大多kv中都有。
version是某个状态,version set就是所有状态的集合(一个branch?)
参考3 ,介绍了实现,一个cv队列,versionSet 拥有manifest写,新的mannifest入队列,判断current。另外ldd文件可以导出内容,一个例子
../ldb manifest_dump --path=./MANIFEST-000006
--------------- Column family "default" (ID 0) --------------
log number: 15
comparator: leveldb.BytewiseComparator
--- level 0 --- version# 1 ---
16:31478713['00010' seq:5732151, type:1 .. '0004999995' seq:6766579, type:1]
14:31206213['00011000020' seq:4753765, type:1 .. '00049999990' seq:4266837, type:1]
12:31367971['00011000023' seq:3559804, type:1 .. '00049999988' seq:3516765, type:1]
10:31331378['00011000025' seq:560662, type:1 .. '00049999994' seq:1786954, type:1]
--- level 1 --- version# 1 ---
...省略60行打印
--- level 63 --- version# 1 ---
next_file_number 18 last_sequence 7515368 prev_log_number 0 max_column_family 0 min_log_number_to_keep 15
WAL
这东西就是oplog一种表达,有编码。可以看参考链接3中的实现
什么时候调用NewWritableFile?
- 打开db,肯定要生成对应的log
- 切换memtable,写满了,生成新的memtable,旧的imm等持久化,wal日志的生命周期结束
什么时候清理? FIndObsoleteFiles 和sst manifest文件一起清理。
谁负责写?当然是dbimpl,对于memtable切换时全程感知的
考虑场景,WAL文件已经写满,但是memtable还没写满怎么办?
至于内容编码和配置选项,以及相关优化选项,又是另一个话题
内容一例
../ldb dump_wal --walfile=./000015.log |tail -f
7515329,4,76,495457,NOOP PUT(0) : 0x3030303334383431343337 PUT(0) : 0x3030303431353233363738 PUT(0) : 0x30303032383839343733 PUT(0) : 0x3030303135373830323031
` 事务`
这又是个复杂的话题,见参考链接
memtable
一般为了支持并发写,会使用skiplist
compaction
leveldb的由来,compaction gc
什么时候会compaction?
compaction原则?
compaction中的snapshot?
https://yq.aliyun.com/articles/655902
flush
什么时候会flush?
Get
DBImpl::GetImpl
- db, cfd, sv之间的关系: column family data,cfd就相当于db键空间,cfd 有super version sv,这个就是version的上层抽象,version的集合
- snapshot,lsn 。 get指定快照多是在事务中。快照实现事务。当然建立过快照,指定快照来取也可以。和git拉分支类似。增加引用计数。snapshot实际上就是lsn的一层薄封装,内部是链表。lsn,版本号。可以理解成两者等同
- 如果不指定,就会算出一个,通常是versionSet中有的最后一个发布的lsn。versionSet会维护这个lsn
- rocksdb内部key是有lsn编码的,会有查找构造类lookupkey,需要snapshot参数。
如果read_option没有指定跳过memtable,那就会从memtable开始遍历
sv->mem->Get
- bloomFilter
- Saver
- MemTableRep,
table_->Getmemtable抽象。后面调用具体的实现。 - 会有对Merge的判断。Merge途中就跳过。
sv->imm->Get
- imm实际上是MemTableListVersion 是一系列version的list。不可插入,add就是插入链表。数据本身不变了。
- 调用GetFromList最后内部遍历还是调用mem->Get,lsn做边界条件,同上,会有对Merge的判断
sv->current->Get
- 通过Version中记录的信息遍历Level中的所有SST文件,利用SST文件记录的边界最大,最小key-
smallest_key和largest_key来判断查找的key是否有可能存在 - 如果在该Level中可能存在,调用TableReader的接口来查找SST文件
- 首先通过SST文件中的Filter来初判key是否存在
- 如果存在key存在,进入Data Block中查找
- 在Data Block利用Block的迭代器
BlockIter利用二分查找BinarySeek或者前缀查找PrefixSeek
- 如果查找成功则返回,如果该Level不存在查找的Key,继续利用Version中的信息进行下一个Level的查找,直到最大的一个Level
table_cache_->Get(k)
#4 ./db_test() [0x6ae065] rocksdb::MemTable::KeyComparator::operator()(char const*, rocksdb::Slice const&) const ??:?
#5 ./db_test() [0x7525f2] rocksdb::InlineSkipList<rocksdb::MemTableRep::KeyComparator const&>::FindGreaterOrEqual(char const*) const ??:?
#6 ./db_test() [0x7516d5] rocksdb::(anonymous namespace)::SkipListRep::Get(rocksdb::LookupKey const&, void*, bool (*)(void*, char const*))skiplistrep.cc:?
#7 ./db_test() [0x6af31f] rocksdb::MemTable::Get(rocksdb::LookupKey const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*, rocksdb::Status*, rocksdb::MergeContext*, rocksdb::RangeDelAggregator*, unsigned long*, rocksdb::ReadOptions const&, rocksb::ReadCallback*, bool*) ??:?
#8 ./db_test() [0x62f49b] rocksdb::DBImpl::GetImpl(rocksdb::ReadOptions const&, rocksdb::ColumnFamilyHandle*, rocksdb::Slice const&, rocksdb::PinnableSlice*, bool*, rocksdb::ReadCallback*, bool*) ??:?
#9 ./db_test() [0x62fc07] rocksdb::DBImpl::Get(rocksdb::ReadOptions const&, rocksdb::ColumnFamilyHandle*, rocksdb::Slice const&, rocksdb::PinnableSlice*) ??:?
#10 ./db_test() [0x59c9cd] rocksdb::DB::Get(rocksdb::ReadOptions const&, rocksdb::ColumnFamilyHandle*, rocksdb::Slice const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*) ??:?
#11 ./db_test() [0x58fc9d] rocksdb::DB::Get(rocksdb::ReadOptions const&, rocksdb::Slice const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*) ??:?
#12 ./db_test() [0x51c3a3] rocksdb::DBTest_MockEnvWithTimestamp_Test::TestBody() ??:?
#13 ./db_test() [0x9401c8] void testing::internal::HandleExceptionsInMethodIfSupported<testing::Test, void>(testing::Test*, void (testing::Test::*)(), char const*) ??:?
#14 ./db_test() [0x93799c] testing::Test::Run() [clone .part.476] gtest-all.cc:?
#15 ./db_test() [0x937b6d] testing::TestInfo::Run() [clone .part.477] gtest-all.cc:?
#16 ./db_test() [0x937ce5] testing::TestCase::Run() [clone .part.478] gtest-all.cc:?
#17 ./db_test() [0x93812d] testing::internal::UnitTestImpl::RunAllTests() ??:?
#18 ./db_test() [0x940678] bool testing::internal::HandleExceptionsInMethodIfSupported<testing::internal::UnitTestImpl, bool>(testing::internal::UnitTestImpl*, bool (testing::internal::UnitTestImpl::*)(), char const*) ??:?
#19 ./db_test() [0x93843f] testing::UnitTest::Run() ??:?
#20 ./db_test() [0x40d9bd] main ??:?
#21 /lib64/libc.so.6(__libc_start_main+0xf5) [0x7f3f6c423bb5] ?? ??:0
#22 ./db_test() [0x513761] _start ??:?
OptimizeForPointLookup
ColumnFamilyOptions* ColumnFamilyOptions::OptimizeForPointLookup(
uint64_t block_cache_size_mb) {
prefix_extractor.reset(NewNoopTransform());
BlockBasedTableOptions block_based_options;
block_based_options.index_type = BlockBasedTableOptions::kHashSearch;
block_based_options.filter_policy.reset(NewBloomFilterPolicy(10));
block_based_options.block_cache =
NewLRUCache(static_cast<size_t>(block_cache_size_mb * 1024 * 1024));
table_factory.reset(new BlockBasedTableFactory(block_based_options));
memtable_prefix_bloom_size_ratio = 0.02;
return this;
}
优化点查询,实际上是改变了BlockBasedTable的index_type, 变成hash自然就不可迭代,主要是bloomfilter prefix tranform哪里会有hash查找
bool const may_contain =
nullptr == prefix_bloom_
? false
: prefix_bloom_->MayContain(prefix_extractor_->Transform(user_key));
write

主要流程1中写的也很详细。我重新复述一下,加深印象
WriteBatch, WriteBatchInternal, WriteBatch::handler, WriteAheadLog
db调用的put等操作,最终调用的都是WriteBatch内部的put,然后调用WriteBatchInternal内部的动作,WriteBatch是一组操作,一起写要比一条条写要高效,并且每一组WriteBatch拥有同一个lsn。
由于WriteBatch是一组动作,putputdelget等等,每一条WriteBatch内部就是个string字节流,第一个字节记录动作类型。内部进行遍历iterate时,调用Handler实现的相关接口,判断是什么动作,最后由memtable执行,putCF等。
另外一个疑问,如何具体区分每一个动作和相关的kv呢,Slice。也就是string_view,每个kv都会有size,这个size提前编码到type的后面,相当于 type+(cfid)+ size+ sv+size+ sv 作为一个单元。del没有第二个size+sv
所以WriteBatch就是 lsn-count-header+{type size sv}…, 多条WriteBatch字节流组合,就是Write Ahead Log
WriteBatch::Handler是个接口类,memtable最终插入数据,memtableinserter要继承handler。
WriteBatchInternal内部工具类。当然是WriteBatch的友元类啦。可以操作WriteBatch的字节流string
编解码是一套很麻烦的动作,rocksdb util/coding.cc/h有很多小函数。可以看看抄一抄。由于string_view是不拥有值的,view嘛,所以复杂的编码动作都需要搞回到string在搞回来。直接搞到string上就append了。如果sv和sv连接,免不了string做交换,有机会找找解决办法。
Writer, WriteGroup, WriteBatch, 并发写
每个Writer是持有WriteBatch的。调用db put接口后就写到WriteBatch中,WriteBatch相当于缓存,这种异步和事件触发的异步不太一样,是同步造出一个二阶段缓存搞的异步。WriteBatch越大吞吐量越大,但是写到memtable越多则会影响后面的flush造成write stall,是个负反馈过程。
WriteBatch+WriteGroup 主要是为了写WAL,WAL是没办法并发写的,Leader Writer负责写,写完唤醒其他Writer,大家一起写memtable,无锁队列+condvar。无锁队列是用原子量实现的。主要逻辑在LinkOne
Write Stall, Write Controller
dbformat
internalkey setinternalkey parsedinternalkey userkey
简单来说 userkey就是internalkey 因为一个key会把lsn和类型编码进去(PackSequenceAndType),去掉这八个字节就是userkey,在rocksdb代码中,有些地方就直接是硬编码,-8了,有些地方转换回来还要+8, Jesus
Slice MemTableRep::UserKey(const char* key) const {
Slice slice = GetLengthPrefixedSlice(key);
return Slice(slice.data(), slice.size() - 8);
}
其实应该有个更小的封装,因为-8可能变(对于想要用rocksdb来修改的人来说)
memtable inserter, memtable, iterate
最终并发写入会调用memtableInserter, 也会生成memtable对象(就那么一个new入口),memtable inserter实现了memtable::handler,内部接口,操作memtable,调用add。
inserter会遍历当前的WriteBatch,解析出每个kv头的tag,然后分别调用putcf,deletecf 等等,内部都是memtable->add
merge
options.merge_operator = MergeOperators::CreatePutOperator();
merge有时候语义上就是put
iterator
iteration
- ArenaWrappedDBIter是暴露给用户的Iterator,它包含DBIter,DBIter则包含InternalIterator,InternalIterator顾名思义,是内部定义,MergeIterator、TwoLevelIterator、BlockIter、MemTableIter、LevelFileNumIterator等都是继承自InternalIterator
- 图中绿色实体框对应的是各个Iterator,按包含顺序颜色由深至浅
- 图中虚线框对应的是创建各个Iterator的方法
- 图中蓝色框对应的则是创建过程中需要的类的对象及它的方法
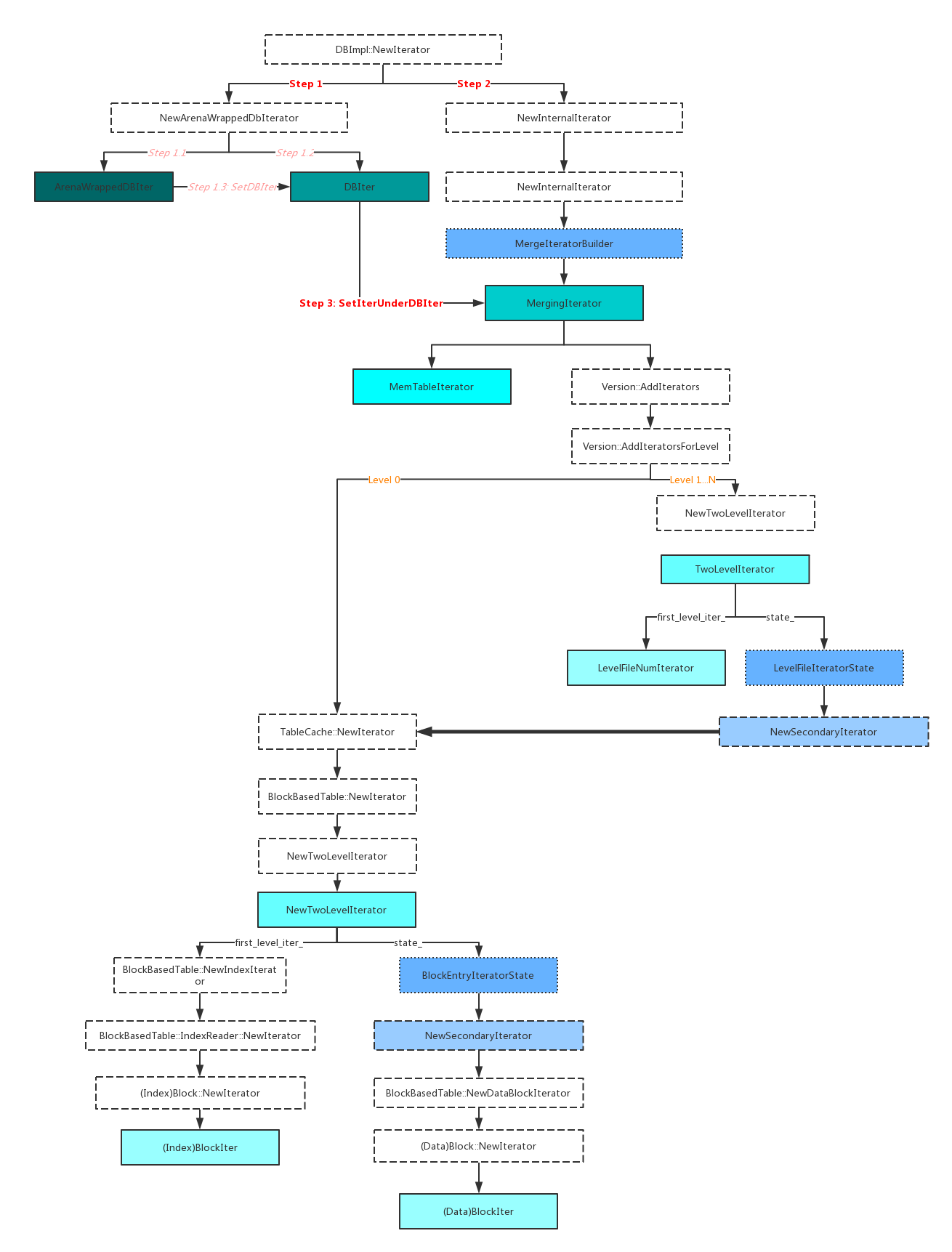
注意到第二步,构造DBIter, 其中的Seek有IsVisiable的判断,也就是实现快照的关键。
每层iterator都会实现iterator头文件中定义好的接口,Seek Next等等,迭代过程中也是逐层调用
另外要注意Seek的语义(SeekForPrev正好相反),不同于Get,查不到不一定返回无效, 会返回所查找的元素的下一个存在于db中的数据
// Position at the first key in the source that at or past target.
// The iterator is Valid() after this call iff the source contains
// an entry that comes at or past target.
// All Seek*() methods clear any error status() that the iterator had prior to
// the call; after the seek, status() indicates only the error (if any) that
// happened during the seek, not any past errors.
virtual void Seek(const Slice& target) = 0;
iterator 牵连的引用以及生命周期, reseek
iterator迭代是依赖快照的,所以创建的迭代器是无法获得新加入的数据的。
iterator不释放 ->versionSet析构->cf set析构-> cfd析构,内部会持有引用。debug模式会assert挂掉
根据上面的结论, 如果版本skip设定比较小,是很容易发生reseek的,设定在Options中
// An iteration->Next() sequentially skips over keys with the same
// user-key unless this option is set. This number specifies the number
// of keys (with the same userkey) that will be sequentially
// skipped before a reseek is issued.
//
// Default: 8
//
// Dynamically changeable through SetOptions() API
uint64_t max_sequential_skip_in_iterations = 8;
比如这个没有flush的场景, option中设定skip=3
Put("a","v1");
Put("a","v2");
Put("b","v1");
Put("a","v3");
iter = NewIterator(RO, CF);
iter->SeekToFirst();//iter指向v4 ,这是最新的数据
int num_reseek = options.statistics->getTickerCount(NUMBER_OF_RESEEKS_IN_ITERATION);
iter->Next();// Seek本身是逆序搜最新的,按理说应该访问下一个,b在a后面,但是没击中,步进大于3,所以就需要重新Seek
assert(options.statistics->getTickerCount(NUMBER_OF_RESEEKS_IN_ITERATION)==num_reseek+1);
由于没有合并key a的所有版本都在memtable中,所以就需要找最旧的a,重新seek,下一个就是b
反过来,如果插入了新的b,先找b后找a,也会出现同样的场景
Put("b","v2");
// 现在是 a3 a2 a1 b2 b1 假设这个iter不指定snapshot
iter = NewIterator(RO, CF);
iter->SeekToLast();// iter指向b v2
iter->Prev();//正常来说是a,但是版本不确定,迭代大于3,就得reseek
iterate_lower_bound, iterate_upper_bound
ReadOption中带有的这两个选项,限定iterator的有效与否
// `iterate_lower_bound` defines the smallest key at which the backward
// iterator can return an entry. Once the bound is passed, Valid() will be
// false. `iterate_lower_bound` is inclusive ie the bound value is a valid
// entry.
//
// If prefix_extractor is not null, the Seek target and `iterate_lower_bound`
// need to have the same prefix. This is because ordering is not guaranteed
// outside of prefix domain.
//
// Default: nullptr
const Slice* iterate_lower_bound;
// "iterate_upper_bound" defines the extent upto which the forward iterator
// can returns entries. Once the bound is reached, Valid() will be false.
// "iterate_upper_bound" is exclusive ie the bound value is
// not a valid entry. If iterator_extractor is not null, the Seek target
// and iterator_upper_bound need to have the same prefix.
// This is because ordering is not guaranteed outside of prefix domain.
//
// Default: nullptr
const Slice* iterate_upper_bound;
如果有key a b y z,设定upper_bound x,seek c,这个场景下iter是invalid的,过了x也没找到c,那就是无效的,同理lower_bound
tombstones, Next
看SeekAfterHittingManyInternalKeys这个测试用例
这里实际上是涉及到一个prefix bloom filter的,参考链接2给出了很详细的介绍和使用说明,我就直接抄过来了
[toc]
Prefix Seek
Prefix seek是RocksDB的一种模式,主要影响Iterator的行为。 在这种模式下,RocksDB的Iterator并不保证所有key是有序的,而只保证具有相同前缀的key是有序的。这样可以保证具有相同特征的key(例如具有相同前缀的key)尽量地被聚合在一起。
使用方法
prefix seek模式的使用如下,
int main() {
DB* db;
Options options;
options.IncreaseParallelism();
options.OptimizeLevelStyleCompaction();
options.create_if_missing = true;
options.prefix_extractor.reset(rocksdb::NewFixedPrefixTransform(3));
Status s = DB::Open(options, kDBPath, &db);
assert(s.ok());
s = db->Put(WriteOptions(), "key1", "value1");
assert(s.ok());
s = db->Put(WriteOptions(), "key2", "value2");
assert(s.ok());
s = db->Put(WriteOptions(), "key3", "value3");
assert(s.ok());
s = db->Put(WriteOptions(), "key4", "value4");
assert(s.ok());
s = db->Put(WriteOptions(), "otherPrefix1", "otherValue1");
assert(s.ok());
s = db->Put(WriteOptions(), "abc", "abcvalue1");
assert(s.ok());
auto iter = db->NewIterator(ReadOptions());
for (iter->Seek("key2"); iter->Valid(); iter->Next())
{
std::cout << iter->key().ToString() << ": " << iter->value().ToString() << std::endl;
}
delete db;
return 0;
}
输出如下
key2: value2
key3: value3
key4: value4
otherPrefix1: otherValue1
从上面的输出,我们可以看到prefix seek模式下iterator的几个特性
- 首先seek(targetKey)方法会将iterator定位到具有相同前缀的区间,并且大于或等于targetKey的位置.
- Next()方法是会跨prefix的,就像例子中,当以”key”为前缀的key都遍历完之后,跨到了下一个prefix “oth”上继续遍历,直到遍历完所有的key,Valid()方法返回false.
- 在遍历的时候,如果只想遍历相同前缀的key,需要在每一次Next之后,判断一次key是前缀是否符合预期.
auto iter = db->NewIterator(ReadOptions());
Slice prefix = options.prefix_extractor->Transform("key0");
for (iter->Seek("key0"); iter->Valid() && iter->key().starts_with(prefix); iter->Next())
{
std::cout << iter->key().ToString() << ": " << iter->value().ToString() << std::endl;
}
输出如下:
key1: value1
key2: value2
key3: value3
key4: value4
Prefix Seek相关的一些优化
为了更快地定位指定prefix的key,或者排除不存在的key,RocksDB做了一些优化,包括:
- prefix bloom filter for block based table
- prefix bloom for memtable
- memtable底层使用hash skiplist
- 使用plain table
一个典型的优化设置见下例
Options options;
// Enable prefix bloom for mem tables
options.prefix_extractor.reset(NewFixedPrefixTransform(3));
options.memtable_prefix_bloom_bits = 100000000;
options.memtable_prefix_bloom_probes = 6;
// Enable prefix bloom for SST files
BlockBasedTableOptions table_options;
table_options.filter_policy.reset(NewBloomFilterPolicy(10, true));
options.table_factory.reset(NewBlockBasedTableFactory(table_options));
DB* db;
Status s = DB::Open(options, "/tmp/rocksdb", &db);
......
auto iter = db->NewIterator(ReadOptions());
iter->Seek("foobar"); // Seek inside prefix "foo"
Prefix Seek相关类图

prefix seek相关的iterator类图
说是Prefix Seek相关的类图,其实就是rocksdb的Iterator类图。这里列出了几个主要的类。
- InternalIterator 接口类,定义了iterator的接口,包括Seek、Next、Prev等接口。
- MergingIterator 返回给用户的实际Iterator类型,之所以叫”Merging”,是因为它持有memtable和sst文件的iterater,对外提供了统一的iterator接口。
- MemTableIterator 用于遍历memtable的iterator。主要的分析对象。
- TwoLevelIterator 用于遍历sst文件的iterator。
Prefix Seek工作流程
Iterator简单分析
通过Iterator的相关接口,来逐层分析,持有PrefixTransform对象的option.prefix_extractor选项是如何工作的。 DB的Iterator由三部分组成
- 当前memtable的iterator
- 所有不可修改的memtable的iterator
- 所有level上的sst文件的iterator(TwoLevelIterator)
这些iterator统一由MergeIterator来管理。MergeIterator持有一个vector成员,上面三类iterator都会添加到该成员中。
autovector<IteratorWrapper, kNumIterReserve> children_;
autovector是对std::vector的完全模板特化版本
class autovector : public std::vector<T> {
using std::vector<T>::vector;
};
autovector主要针对在栈上分配的数组,保存数量较少的item这种使用场景做了优化。 IteratorWrapper是对InternalIterator*类型的对象的一个简单封装,主要cache了iter)->Valid()和iter_->key()的结果,提供更好的局部性访问性能。其他接口和InternalIterator一样,只是转发请求给iter_。
DB的Iterator添加当前使用的memtable的iterator的代码如下
InternalIterator* DBImpl::NewInternalIterator(
const ReadOptions& read_options, ColumnFamilyData* cfd,
SuperVersion* super_version, Arena* arena,
RangeDelAggregator* range_del_agg) {
...
merge_iter_builder.AddIterator(
super_version->mem->NewIterator(read_options, arena));
...
arena是为所有iterator已经分配的一块内存。 向MergeIterator添加Iterator的实现:
- 先将要添加的iter加入到vector成员children_中
- 如果iter是有效的iterator,将该iter添加到一个最小堆成员中。
virtual void AddIterator(InternalIterator* iter) {
assert(direction_ == kForward);
children_.emplace_back(iter);
if (pinned_iters_mgr_) {
iter->SetPinnedItersMgr(pinned_iters_mgr_);
}
auto new_wrapper = children_.back();
if (new_wrapper.Valid()) {
minHeap_.push(&new_wrapper);
current_ = CurrentForward();
}
}
这里的最小堆minHeap_用于维护上面所有合法iterator的访问顺序,指向key较小的iter,越靠近堆顶,这样,当连续多次调用Next接口时,都在同一个child iterator上,可以直接通过堆顶的iterator来获取Next,而不用遍历所有children。 如果堆顶iterator的下一个元素的不是合法的,则将该iterator从堆中pop出去,调整堆之后,拿到新的堆顶元素。 DB的Iterator MergingIterator的Next接口主要实现如下
virtual void Next() override {
assert(Valid());
...
// For the heap modifications below to be correct, current_ must be the
// current top of the heap.
assert(current_ == CurrentForward());
// as the current points to the current record. move the iterator forward.
current_->Next();
if (current_->Valid()) {
// current is still valid after the Next() call above. Call
// replace_top() to restore the heap property. When the same child
// iterator yields a sequence of keys, this is cheap.
minHeap_.replace_top(current_);
} else {
// current stopped being valid, remove it from the heap.
minHeap_.pop();
}
current_ = CurrentForward();
Seek接口的实现
Seek一个target的实现,通过遍历每个child iterator,然后将合法的iterator插入到最小堆minHeap中,将current_成员指向minHeap的堆顶。
virtual void Seek(const Slice& target) override {
ClearHeaps();
for (auto& child : children_) {
{
PERF_TIMER_GUARD(seek_child_seek_time);
child.Seek(target);
}
PERF_COUNTER_ADD(seek_child_seek_count, 1);
if (child.Valid()) {
PERF_TIMER_GUARD(seek_min_heap_time);
minHeap_.push(&child);
}
}
direction_ = kForward;
{
PERF_TIMER_GUARD(seek_min_heap_time);
current_ = CurrentForward();
}
}
以当前可写的memtable的iterator为例,当用户调用Seek接口时,如何定位到memtable中的目标key。
MemTableIterator的Seek
在memtable中持有一个MemTableRep::Iterator*类型的iterator指针iter_,iter_指向的对象的实际类型由MemTableRep的子类中分别定义。以SkipListRep为例, 在MemTableIterator的构造函数中,当设置了prefix_seek模式时,调用MemTableRep的GetDynamicPrefixIterator接口来获取具体的iterator对象。
MemTableIterator(const MemTable& mem, const ReadOptions& read_options,
Arena* arena, bool use_range_del_table = false)
: bloom_(nullptr),
prefix_extractor_(mem.prefix_extractor_),
comparator_(mem.comparator_),
valid_(false),
arena_mode_(arena != nullptr),
value_pinned_(!mem.GetMemTableOptions()->inplace_update_support) {
if (use_range_del_table) {
iter_ = mem.range_del_table_->GetIterator(arena);
} else if (prefix_extractor_ != nullptr && !read_options.total_order_seek) {
bloom_ = mem.prefix_bloom_.get();
iter_ = mem.table_->GetDynamicPrefixIterator(arena);
} else {
iter_ = mem.table_->GetIterator(arena);
}
}
对于SkipList来说,GetDynamicPrefixIterator也是调用GetIterator,只有对HashLinkListRep和HashSkipListRe,这个方法才有不同的实现。
virtual MemTableRep::Iterator* GetIterator(Arena* arena = nullptr) override {
if (lookahead_ > 0) {
void *mem =
arena ? arena->AllocateAligned(sizeof(SkipListRep::LookaheadIterator))
: operator new(sizeof(SkipListRep::LookaheadIterator));
return new (mem) SkipListRep::LookaheadIterator(*this);
} else {
void *mem =
arena ? arena->AllocateAligned(sizeof(SkipListRep::Iterator))
: operator new(sizeof(SkipListRep::Iterator));
return new (mem) SkipListRep::Iterator(&skip_list_);
}
}
这样就创建了MemTableIterator。
当调用到MemTableIterator的Seek接口时:
- 首先在DynamicBloom成员bloom_中查找目标key的prefix是否可能在当前的memtable中存在。
- 如果不存在,则一定不存在,可以直接返回。
- 如果可能存在,则调用MemTableRep的iterator进行Seek。
virtual void Seek(const Slice& k) override {
PERF_TIMER_GUARD(seek_on_memtable_time);
PERF_COUNTER_ADD(seek_on_memtable_count, 1);
if (bloom_ != nullptr) {
if (!bloom_->MayContain(
prefix_extractor_->Transform(ExtractUserKey(k)))) {
PERF_COUNTER_ADD(bloom_memtable_miss_count, 1);
valid_ = false;
return;
} else {
PERF_COUNTER_ADD(bloom_memtable_hit_count, 1);
}
}
iter_->Seek(k, nullptr);
valid_ = iter_->Valid();
}
当调用MemTableRep的iterator进行Seek时,则是通过调用实际使用的数据结构的Seek接口,找到第一个大于或等于key的目标。
// Advance to the first entry with a key >= target virtual void Seek(const Slice& user_key, const char* memtable_key) override { if (memtable_key != nullptr) { iter_.Seek(memtable_key); } else { iter_.Seek(EncodeKey(&tmp_, user_key)); } }
第一个分支主要用于确定在memtable中的key,做update类的操作.
MemTable Prefix Bloom的构建
prefix bloom作为memtable的一个成员,当向memtable插入一个key value时,会截取key的prefix,插入到prefix bloom中。
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, /* user key */ const Slice& value, bool allow_concurrent, MemTablePostProcessInfo* post_process_info) { ... if (!allow_concurrent) { ... if (prefix_bloom_) { assert(prefix_extractor_); prefix_bloom_->Add(prefix_extractor_->Transform(key)); } ... else { ... if (prefix_bloom_) { assert(prefix_extractor_); prefix_bloom_->AddConcurrently(prefix_extractor_->Transform(key)); } ... } ...}
关于bloom filter的原理和实现可以参考前文。传送门 因为再BlockBasedTable中,对bloom filter的用法不同,所以使用了不同实现的bloom filter。基本原理是相同的。
WAL
对RocksDB的每一次update都会写入两个位置:1) 内存表(内存数据结构,后续会flush到SST file) 2)磁盘中的write ahead log(WAL)。在故障发生时,WAL可以用来恢复内存表中的数据。默认情况下,RocksDB通过在每次用户写时调用fflush WAL文件来保证一致性。
Life Cycle of a WAL
举个例子,RocksDB实例创建了两个column families,分别是 new_cf和default。一旦db被open,就会在磁盘上创建一个WAL来持久化所有的写操作。
DB* db;
std::vector<ColumnFamilyDescriptor> column_families;
column_families.push_back(ColumnFamilyDescriptor(
kDefaultColumnFamilyName, ColumnFamilyOptions()));
column_families.push_back(ColumnFamilyDescriptor(
"new_cf", ColumnFamilyOptions()));
std::vector<ColumnFamilyHandle*> handles;
s = DB::Open(DBOptions(), kDBPath, column_families, &handles, &db);
添加一些kv对数据
db->Put(WriteOptions(), handles[1], Slice("key1"), Slice("value1"));
db->Put(WriteOptions(), handles[0], Slice("key2"), Slice("value2"));
db->Put(WriteOptions(), handles[1], Slice("key3"), Slice("value3"));
db->Put(WriteOptions(), handles[0], Slice("key4"), Slice("value4"));
此时,WAL已经记录了所有的写操作。WAL文件会保持打开状态,一直记录后续所有的写,直到WAL 大小达到DBOptions::max_total_wal_size为止。 如果用户决定要flush new_cf中的数据时,会有以下操作:1) new_cf的数据 key1和key3会flush到一个新的SST file。 2)新建一个WAL,后续对所有列族的写都通过新的WAL记录。3)老的WAL不再记录新的写
db->Flush(FlushOptions(), handles[1]);
// key5 and key6 will appear in a new WAL
db->Put(WriteOptions(), handles[1], Slice("key5"), Slice("value5"));
db->Put(WriteOptions(), handles[0], Slice("key6"), Slice("value6"));
此时,会有两个WAL文件,老的WAL会包含key1、key2、key3和key4,新的WAL文件包含key5和key6。因为老的WAL仍然含有default 列族的数据,所以还没有被删除。只有当用户决定flush default列族的数据之后,老的WAL 才会被归档然后从磁盘中删除。
db->Flush(FlushOptions(), handles[0]);
// The older WAL will be archived and purged separetely
总之,在以下情况下会创建一个WAL:
- 新打开一个DB
- flush了一个column family。一个WAL文件只有当所有的列族数据都已经flush到SST file之后才会被删除,或者说,所有的WAL中数据都持久化到SST file之后,才会被删除。归档的WAL文件会move到一个单独的目录,后续从磁盘中删除。
WAL Configurations
- DBOptions::wal_dir : RocksDB保存WAL file的目录,可以将目录与数据目录配置在不同的路径下。
- DBOptions::WAL_ttl_seconds, DBOptions::WAL_size_limit_MB:这两个选项影响归档WAL被删除的快慢。
- DBOptions::max_total_wal_size : 为了限制WALs的大小,RocksDB使用该配置来触发 column family flush到SST file。一旦,WALs超过了这个大小,RocksDB会强制将所有列族的数据flush到SST file,之后就可以删除最老的WALs。
- DBOptions::avoid_flush_during_recovery
- DBOptions::manual_wal_flush: 这个参数决定了WAL flush是否在每次写之后自动执行,或者是纯手动执行(用户调用FlushWAL来触发)。
- DBOptions::wal_filter:在恢复数据时可以过滤掉WAL中某些记录
- WriteOptions::disableWAL: 打开或者关闭WAL支持
WAL LOG File Format
OverView
WAL将内存表的操作记录序列化后持久化存储到日志文件。当DB故障时可以使用WAL 文件恢复到DB故障前的一致性状态。当内存表的数据安全地flush到持久化存储文件中后,对应的WAL log(s)被归档,然后在某个时刻被删除。
WAL Manager
在WAL目录中,WAL文件按照序列号递增命名。为了重建数据库故障之前的一致性状态,必须按照序号号递增的顺序读取WAL文件。WAL manager封装了读WAL文件的操作。WAL manager内部使用Reader or Writer abstraction 来读取WAL file。
Reader/Writer
Writer提供了将log记录append到log 文件的操作接口(内部使用WriteableFile接口)。Reader提供了从log文件中顺序读日志记录的操作接口(内部使用SequentialFile接口)。
Log File Format
日志文件保安了一系列不停长度的记录。Record按照kBlockSize分配。如果一个特定的记录不能完全适配剩余的空间,那么就会将剩余的空间补零。writer按照kBlockSize去写一个数据库,reader按照kBlockSIze去读一个数据库。
+-----+-------------+--+----+----------+------+-- ... ----+
File | r0 | r1 |P | r2 | r3 | r4 | |
+-----+-------------+--+----+----------+------+-- ... ----+
<--- kBlockSize ------>|<-- kBlockSize ------>|
rn = variable size records
P = Padding
Record Format
+---------+-----------+-----------+--- ... ---+
|CRC (4B) | Size (2B) | Type (1B) | Payload |
+---------+-----------+-----------+--- ... ---+
CRC = 32bit hash computed over the payload using CRC
Size = Length of the payload data
Type = Type of record
(kZeroType, kFullType, kFirstType, kLastType, kMiddleType )
The type is used to group a bunch of records together to represent
blocks that are larger than kBlockSize
Payload = Byte stream as long as specified by the payload size
日志文件由连续的32KB大小的block组成。唯一的例外是文件尾部数据包含一个不是完整的block。 每一个block包含连续的Records:
block := record* trailer?
record :=
checksum: uint32 // crc32c of type and data[]
length: uint16
type: uint8 // One of FULL, FIRST, MIDDLE, LAST
data: uint8[length]
record type
FULL == 1
FIRST == 2
MIDDLE == 3
LAST == 4
FULL 表示包含了全部用户record记录 FIRST、MIDDLE、LAST用户表示一个record太大然后拆分为多个数据片。FIRST表示是用户record的第一块数据,LAST表示最后一个,MID是用户Record中间部分的数据。 Example
A: length 1000
B: length 97270
C: length 8000
A会在第一个block中存储一个完整的Record。 B会被拆分为3个分片,第一个分片占用了第一个block的剩余全部空间,第二个分片占用第二个block的全部空间,第三个分片占用第三个block的前面部分空间。会在第三个block中预留6个字节,置为空来表示结束。 C将会完整存储在第四个block。FULL Record
WAL Recovery Modes
每个应用都是唯一的,都需要RocksDB保证特定状态的一致性。RocksDB中每一个提交的记录都是持久化的。没有提交的记录保存在WAL file中。当DB正常退出时,在退出之前会提交所有没有提交的数据,所以总是能够保证一致性。当RocksDB进程被kill或者服务器重启时,RocksDB需要恢复到一个一致性状态。最重要的恢复操作之一就是replay所有WAL中没有提交的记录。不同的WAL recovery 模式定义了不同的replay WAL的行为。
kTolerateCorruptedTailRecords
在这种模式下,WAL replay 会忽视日志文件末尾的任何error。这些error主要来源于不安全的进程退出后产生的不完全的写错误日志。这是一种启发式的或者探索式的模式,系统并不能区分是日志文件tail的data corruption还是不完全写操作。任何其他的IO error,都会被视作data corruption。
这种模式被大部分应用使用,这是因为该模式提供了一种比较合理的tradeoff between 不安全退出后重启和数据一致性。
kAbsoluteConsistency
在这种模式下,在replay WAL过程中任何IO 错误都被视为data corruption。这种模式适用于以下场景:应用不能接受丢失任何记录,而且有方法恢复未提交的数据。
kPointInTimeConsistency
在这种模式下,当发生IO errror时,WAL replay会stop,系统恢复到一个满足一致性的时间点上。这种模式适用于有副本的集群,来自另外一个副本的数据可以用来恢复当前的实例。
kSkipAnyCorruptedRecord
在这种模式下,WAL replay会忽视日志文件中的任何错误。系统尝试恢复尽可能多的数据。适用于灾后重建的场景。
MISC
Write Buffer Manager
其实rocksdb整体很多这种插件接口语义,比如Write Buffer Manager, 比如Merge Operator,比如Rate Limiter,sst_file_maniger,eventlistener,用户创建,传进指针(有默认的,也可以继承重写接口)
Write Buffer Manager正如名字,就是控制写入buffer的,这个正是memtable的总大小上限,没有设置的话会有个默认的设定比如两个memtable大小
什么时候会切换memtable?
- Memtable的大小在一次写入后超过write_buffer_size。
- 所有列族中的memtable大小超过db_write_buffer_size了,或者write_buffer_manager要求落盘。在这种场景,最大的memtable会被落盘
- WAL文件的总大小超过max_total_wal_size。在这个场景,有着最老数据的memtable会被落盘,这样才允许携带有跟这个memtable相关数据的WAL文件被删除。
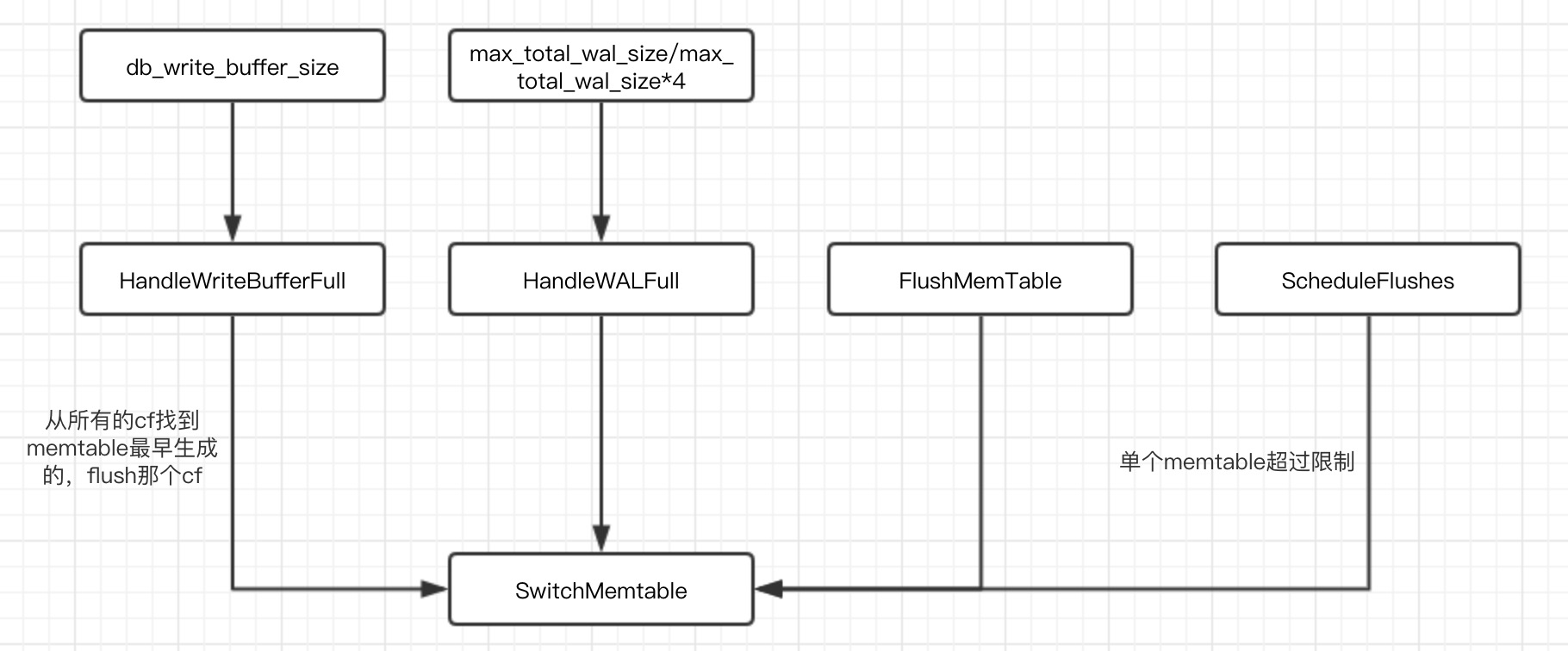 ScheduleFlushes ScheduleFlushes |
HandleWALFull | HandleWriteBufferFull | FlushMemTable |
条件
-
当前线程持有db的大锁
-
当前线程是写wal文件的leader
-
如果开启了enable_pipelined_write选项(写wal和写memtable分开), 那么同时要等到成为写memtable的leader
- 判断当前wal文件是否为空,如果不为空就创建新的wal文件(recycle_log_file_num选项开启就复用),然后构建新memtable。刷盘当前wal文件
-
把之前的memtable变成immutable,然后切到新memtable
- 调用InstallSuperVersionAndScheduleWork函数,这个函数会更新super_version_
-
memtable
影响memtable的几个选项
影响memtable的最重要的几个选项是:
- memtable_factory: memtable对象的工厂。通过声明一个工厂对象,用户可以改变底层memtable的实现,并提供事先声明的选项。
- write_buffer_size:一个memtable的大小
- db_write_buffer_size:多个列族的memtable的大小总和。这可以用来管理memtable使用的总内存数。
- write_buffer_manager:除了声明memtable的总大小,用户还可以提供他们自己的写缓冲区管理器,用来控制总体的memtable使用量。这个选项会覆盖db_write_buffer_size
- max_write_buffer_number:内存中可以拥有刷盘到SST文件前的最大memtable数。
| Memtable类型 | SkipList | HashSkipList | HashLinkList | Vector |
|---|---|---|---|---|
| 最佳使用场景 | 通用 | 带特殊key前缀的范围查询 | 带特殊key前缀,并且每个前缀都只有很小数量的行 | 大量随机写压力 |
| 索引类型 | 二分搜索 | 哈希+二分搜索 | 哈希+线性搜索 | 线性搜索 |
| 是否支持全量db有序扫描? | 天然支持 | 非常耗费资源(拷贝以及排序一生成一个临时视图) | 同HashSkipList | 同HashSkipList |
| 额外内存 | 平均(每个节点有多个指针) | 高(哈希桶+非空桶的skiplist元数据+每个节点多个指针) | 稍低(哈希桶+每个节点的指针) | 低(vector尾部预分配的内存) |
| Memtable落盘 | 快速,以及固定数量的额外内存 | 慢,并且大量临时内存使用 | 同HashSkipList | 同HashSkipList |
| 并发插入 | 支持 | 不支持 | 不支持 | 不支持 |
| 带Hint插入 | 支持(在没有并发插入的时候) | 不支持 | 不支持 | 不支持 |
Direct IO
关于buffered IO和DirectIO可以看参考链接3, 这个图不错,偷过来

rocksdb属于自缓存应用,有memtable+blockcache来保证了一定的局部性。本身已经实现了缓存算法(LRU,clock)可以不使用系统的页缓存,使用DirectIO,在options中有配置
// Use O_DIRECT for user reads
// Default: false
// Not supported in ROCKSDB_LITE mode!
bool use_direct_reads = false;
// Use O_DIRECT for both reads and writes in background flush and compactions
// When true, we also force new_table_reader_for_compaction_inputs to true.
// Default: false
// Not supported in ROCKSDB_LITE mode!
bool use_direct_io_for_flush_and_compaction = false;
对于use_direct_io_for_flush_and_compaction, compaction有个compaction block cache 不建议用,具体可以参考链接4
Rate Limiter限流器
Rocksdb内置控制写入速率降低延迟的,当然包括compaction速率。如果compaction导致了较多毛刺,考虑一下是不是没使用limiter
通过调用NewGenericRateLimiter创建一个RateLimiter对象,可以对每个RocksDB实例分别创建,或者在RocksDB实例之间共享,以此控制落盘和压缩的写速率总量。
RateLimiter* rate_limiter = NewGenericRateLimiter(
rate_bytes_per_sec /* int64_t */,
refill_period_us /* int64_t */,
fairness /* int32_t */);
参数:
- rate_bytes_per_sec:通常这是唯一一个你需要关心的参数。他控制压缩和落盘的总速率,单位为bytes/秒。现在,RocksDB并不强制限制除了落盘和压缩以外的操作(如写WAL)
- refill_period_us:这个控制令牌被填充的频率。例如,当rate_bytes_per_sec被设置为10MB/s然后refill_period_us被设置为100ms,那么就每100ms会从新填充1MB的限量。更大的数值会导致突发写,而更小的数值会导致CPU过载。默认数值100,000应该在大多数场景都能很好工作了
- fairness:RateLimiter接受高优先级请求和低优先级请求。一个低优先级任务会被高优先级任务挡住。现在,RocksDB把来自压缩的请求认为是低优先级的,把来自落盘的任务认为是高优先级的。如果落盘请求不断地过来,低优先级请求会被拦截。这个fairness参数保证低优先级请求,在即使有高优先级任务的时候,也会有1/fairness的机会被执行,以避免低优先级任务的饿死。默认是10通常是可以的。
尽管令牌会以refill_period_us设定的时间按照间隔来填充,我们仍然需要保证一次写爆发中的最大字节数,因为我们不希望看到令牌堆积了很久,然后在一次写爆发中一次性消耗光,这显然不符合我们的需求。GetSingleBurstBytes会返回这个令牌数量的上限。
这样,每次写请求前,都需要申请令牌。如果这个请求无法被满足,请求会被阻塞,直到令牌被填充到足够完成请求。比如:
// block if tokens are not enough
rate_limiter->Request(1024 /* bytes */, rocksdb::Env::IO_HIGH);
Status s = db->Flush();
如果有需要,用户还可以通过SetBytesPerSecond动态修改限流器每秒流量。参考include/rocksdb/rate_limiter.h 了解更多细节
对那些RocksDB提供的原生限流器无法满足需求的用户,他们可以通过继承include/rocksdb/rate_limiter.h 来实现自己的限流器。
memory
主要几大块, blockcache,memtable,index & filter block, pinned by iterator
memtable也可以被write buffer manager来控制
table_options.block_cache->GetPinnedUsage()获得第四个
文件的快速导入rocksdb::SstFileWriter/ IngestExternalFile
具体可以看这篇文档https://github.com/facebook/rocksdb/wiki/Creating-and-Ingesting-SST-files
经常用于文件导入,快速导入,调用write接口还是太慢,直接生成L0sst更快。但是存在问题,L0文件过多,触发compaction,所以要先停掉compaction,这点在rockset使用该功能的时候分享过。这里标记备忘
Arena
分配器需要做什么
- 状态,这里的分配器不需要实时的回收,也就仅仅是分配器,不管回收,生命周期内析构就可以了
- 分配,尽可能的分配成功
看看arena的api什么样的
class Arena {
public:
Arena();
~Arena();
// Return a pointer to a newly allocated memory block of "bytes" bytes.
char* Allocate(size_t bytes);
// Allocate memory with the normal alignment guarantees provided by malloc
char* AllocateAligned(size_t bytes);
// Returns an estimate of the total memory usage of data allocated
// by the arena.
size_t MemoryUsage() const {
return reinterpret_cast<uintptr_t>(memory_usage_.NoBarrier_Load());
}
private:
char* AllocateFallback(size_t bytes);
char* AllocateNewBlock(size_t block_bytes);
// Allocation state
char* alloc_ptr_;
size_t alloc_bytes_remaining_;
// Array of new[] allocated memory blocks
std::vector<char*> blocks_;
// Total memory usage of the arena.
port::AtomicPointer memory_usage_;
Arena(const Arena&);
void operator=(const Arena&);
};
能看出来就是个二维动态数组,vector<char*>,每次分一个数组,也就是block,如果不够用了在分配一个新的block
Allocate会调用AllocateFallBack和AllocateNewBlock 完全取决于剩余内存和新分配内存的关系
- 如果需求的内存小于剩余的内存,那么直接在剩余的内存分配就可以了;
- 如果需求的内存大于剩余的内存,而且大于4096/4,则给这内存单独分配一块bytes(函数参数)大小的内存。
- 如果需求的内存大于剩余的内存,而且小于4096/4,则重新分配一个内存块,默认大小4096,用于存储数据。
rocksdb的优化做了哪些工作
抽象出allocator api,以及支持hugepage
char* Arena::AllocateFromHugePage(size_t bytes)
###
reference
-
官方文档 https://github.com/facebook/rocksdb/wiki
-
一个Rocksdb简要分析 http://alexstocks.github.io/html/rocksdb.html
-
rocksdb 各种图,点击即可 https://wipple.devnull.network/research/rippled/api.docs/structrocksdb_1_1SuperVersion.html
-
翻译的中文文档 https://rocksdb.org.cn/doc.html
-
dbio 这个分类很有意思。https://dbdb.io/db/rocksdb
-
leveldb 介绍,感觉skiplist要被说烂了 http://taobaofed.org/blog/2017/07/05/leveldb-analysis/
-
arangodb 用的rocksdb ,怎么做的? https://dzone.com/articles/rocksdb-integration-in-arangodb
-
cockroachdb 用的rocksdb, 怎么做的? https://www.cockroachlabs.com/blog/cockroachdb-on-rocksd/
- myrocks 分析,参数很有参考价值。https://www.percona.com/blog/2018/04/30/a-look-at-myrocks-performance/
- 一个cpu指标数据分析,http://www.cs.unca.edu/brock/classes/Spring2013/csci331/notes/paper-1130.pdf
- 术语 英语https://github.com/facebook/rocksdb/wiki/Terminology
- manifest 介绍 和实现http://mysql.taobao.org/monthly/2018/05/08/
- manifest 相关的一个bug pr 介绍https://www.jianshu.com/p/d1b38ce0d966
- WAL 实现http://mysql.taobao.org/monthly/2018/04/09/
- WAL 刷盘机制 http://kernelmaker.github.io/Rocksdb_WAL
- WAL恢复 https://blog.csdn.net/dongfengxueli/article/details/66975838
- WAL生命周期 https://www.jianshu.com/p/40a4f2521e0a
- WAL调研,这哥们写了一半 https://youjiali1995.github.io/rocksdb/wal/
- 事务 https://github.com/facebook/rocksdb/wiki/Transactions
- rocksdb 事务实现分析 https://yq.aliyun.com/articles/257424
- 更进一步 https://github.com/facebook/rocksdb/wiki/WritePrepared-Transactions
- myrocks 事务http://mysql.taobao.org/monthly/2016/11/02/?spm=a2c4e.11153940.blogcont627737.14.d47c5ce5SNWg8r
- mysql xa事务http://mysql.taobao.org/monthly/2017/09/05/
- binlog xa https://blog.51cto.com/wangwei007/2323844
-
level compactionhttp://mysql.taobao.org/monthly/2018/10/08/
-
https://www.pagefault.info/2018/11/13/mysql-rocksdb.-data-reading-(i).html
-
https://www.pagefault.info/2018/12/19/mysql-rocksdb.-data-reading-(ii).html
-
点查询优化,不可迭代 https://stackoverflow.com/questions/52139349/iterating-when-using-optimizeforpointlookup
-
优化点查询,介绍https://rocksdb.org/blog/2018/08/23/data-block-hash-index.html
-
skiplist http://www.pandademo.com/2016/03/memtable-and-skiplist-leveldb-source-dissect-3/
-
看图了解rocksdb https://yq.aliyun.com/articles/669316?utm_content=m_1000024335
-
memtable写入 http://mysql.taobao.org/monthly/2018/08/08/
-
hashskiplist http://mysql.taobao.org/monthly/2017/05/08/
-
https://github.com/Terark/terarkdb/wiki/%E9%87%8D%E6%96%B0%E5%AE%9E%E7%8E%B0-RocksDB-MemTable
-
官方文档 https://github.com/facebook/rocksdb/wiki/Write-Buffer-Manager
-
上面的一个翻译https://github.com/johnzeng/rocksdb-doc-cn/blob/master/doc/Write-Buffer-Manager.md
-
https://www.ibm.com/developerworks/cn/linux/l-cn-directio/index.html
-
Direct IO官方文档https://github.com/facebook/rocksdb/wiki/Direct-IO>
-
Rate Limiter https://github.com/johnzeng/rocksdb-doc-cn/blob/master/doc/Rate-Limiter.md
-
rate limiter实现 https://blog.csdn.net/Z_Stand/article/details/109558042
- memtable原理,看WriteBufferManager部分https://bravoboy.github.io/2018/12/07/rocksdb-Memtable/
-
官方文档翻译https://github.com/johnzeng/rocksdb-doc-cn/blob/master/doc/MemTable.md
-
源码https://github.com/google/leveldb/blob/master/util/arena.h
-
http://www.pandademo.com/2016/09/arena-rocksdb-source-dissect-0/
-
一个应用,作者是tikv的 https://www.jianshu.com/p/26214e45fd4a
- 源码分析 https://www.jianshu.com/p/9848a376d41d
