grpc介绍以及原理
介绍ppt,需要了解protobuf的相关概念
整体架构如图
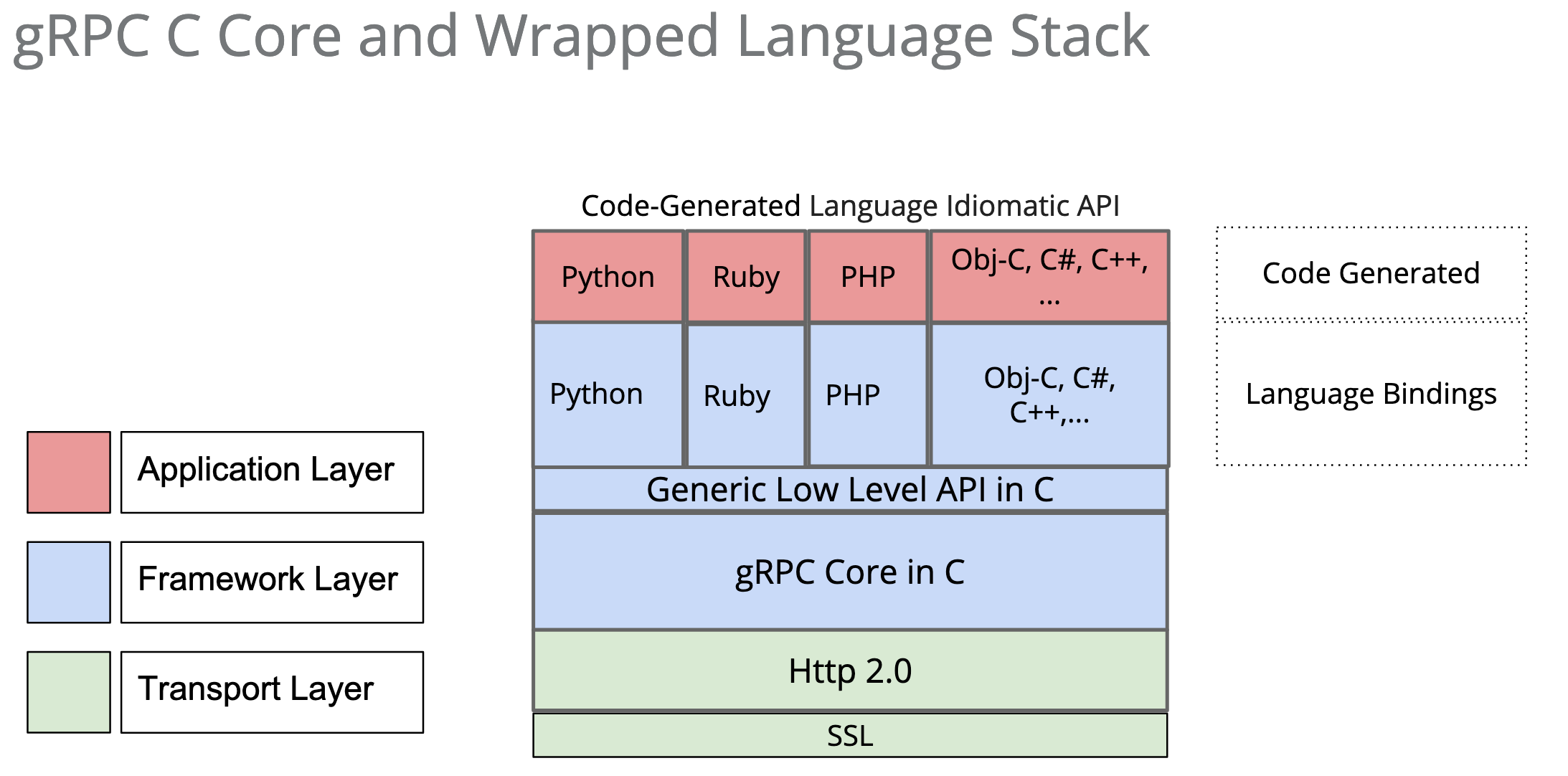
底层通过http2传输,也就带了流式传输功能 单向流双向流,只要proto消息带上 stream修饰符就行了
service Greeter {
rpc SayHello3 (stream HelloRequest) returns (stream HelloReply) {}
}
http2是必要的么?还是google内网服务全体推http2?所有服务全切到http?如果存量服务没有怎么办?http2能带来哪些优点?
- 针对http1 链接共享,数据压缩,流量控制,低延迟,还支持流式
HTTP2 is used for many good reasons: HTTP2 is a standard and HTTP protocol is well known to proxies, firewalls and many software tools. The streaming nature of HTTP2 suits our needs very well, so no need to reinvent the wheel.
感觉还是主推http2, google没有内部各种各样的协议交互的问题
直接基于tcp socket或者websocket一样性能不差,我猜google内部组件对接上都推http就没有考虑这些方案
使用接口
- 同步一元调用 Unary /流式 stream
- 一元调用就是request respons one shot的形式,流式就是一个弱化的tcp流的感觉
- 异步,得用个消费队列来接收消息
// 记录每个 AsyncSayHello 调用的信息
struct AsyncClientCall {
HelloReply reply;
ClientContext context;
Status status;
std::unique_ptr<ClientAsyncResponseReader<HelloReply>> response_reader;
};
class GreeterClient
{
public:
GreeterClient(std::shared_ptr<Channel> channel)
: stub_(Greeter::NewStub(channel)) {}
void SayHello(const std::string& user)
{
HelloRequest request;
request.set_name(user);
AsyncClientCall* call = new AsyncClientCall;
// 异步调用,非阻塞
call->response_reader = stub_->AsyncSayHello(&call->context, request, &cq_);
// 当 RPC 调用结束时,让 gRPC 自动将返回结果填充到 AsyncClientCall 中
// 并将 AsyncClientCall 的地址加入到队列中
call->response_reader->Finish(&call->reply, &call->status, (void*)call);
}
void AsyncCompleteRpc()
{
void* got_tag;
bool ok = false;
// 从队列中取出 AsyncClientCall 的地址,会阻塞
while (cq_.Next(&got_tag, &ok))
{
AsyncClientCall* call = static_cast<AsyncClientCall*>(got_tag);
if (call->status.ok())
std::cout << "Greeter received: " << call->reply.message() << std::endl;
else
std::cout << "RPC failed" << std::endl;
delete call; // 销毁对象
}
}
private:
std::unique_ptr<Greeter::Stub> stub_;
CompletionQueue cq_; // 队列
};
int main()
{
auto channel = grpc::CreateChannel("localhost:5000", grpc::InsecureChannelCredentials());
GreeterClient greeter(channel);
// 启动新线程,从队列中取出结果并处理
std::thread thread_ = std::thread(&GreeterClient::AsyncCompleteRpc, &greeter);
for (int i = 0; i < 100; i++) {
auto user = std::string("hello-world-") + std::to_string(i);
greeter.SayHello(user);
}
return 0;
}
不像trpc会生成异步的客户端代码,future/promise
rpc从简单到复杂
主要做三件事儿
- 服务端如何确定客户端要调用的函数;
- 在远程调用中,客户端和服务端分别维护一个函数名id <-> 函数的对应表, 函数名id在所有进程中都是唯一确定的。客户端在做远程过程调用时,附上这个ID,服务端通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
- 如何进行序列化和反序列化;
- 客户端和服务端交互时将参数或结果转化为字节流在网络中传输,那么数据转化为字节流的或者将字节流转换成能读取的固定格式时就需要进行序列化和反序列化,序列化和反序列化的速度也会影响远程调用的效率。
- 如何进行网络传输(选择何种网络协议)
- 多数RPC框架选择TCP作为传输协议,也有部分选择HTTP。如gRPC使用HTTP2。不同的协议各有利弊。TCP更加高效,而HTTP在实际应用中更加的灵活。
从 服务端注册函数,客户端调用名字对应的函数演化成 定义IDL文件描述接口,服务端实现接口,客户端调用接口 ,名字-函数注册信息全部隐藏在框架背后,并且,接口参数复杂化
protobuf或者thift能提供接口参数的codegen/parse
最简单的rpc ,拿nanorpc举例子
服务端,注册函数名字 函数(存一个map)
auto server = nanorpc::http::easy::make_server("0.0.0.0", "55555", 8, "/api/",
std::pair{"test", [] (std::string const &s) { return "Tested: " + s; } }
);
std::cout << "Press Enter for quit." << std::endl;
std::cin.get();
客户端,调用名字函数
auto client = nanorpc::http::easy::make_client("localhost", "55555", 8, "/api/");
std::string result = client.call("test", std::string{"test"});
std::cout << "Response from server: " << result << std::endl;
中间有个解析组件,把客户端发的函数名和参数拿到,从函数map里拿到函数,调用,结束
grpc这些框架,如何处理这些步骤?
首先,函数表,框架自身保存好,生成接口函数,既然客户端都直接调用接口函数了,这还算rpc么?
框架的客户端调用大多是这个样子的 grpc cpp为例子
Status status = stub_->SayHello(&context, request, &reply);
生成的客户端接口和服务端的实现接口不一样,代码生成会生成一个代理类(stub), 中间框架自身根据注册信息和context调用服务端的实现,只有request response是完全一致的,函数是不一致的
劣势
- grpc没有服务自治的能力,也没有整体插件化,不支持插件注入
现在公司使用框架,各种组件组合使用的场景非常多
比如公司级别统一的日志框架,公司级别统一的名字服务,公司级别统一的指标收集平台,统一的配置文件管理/下发平台
提供统一的访问平台来查阅,而不是傻乎乎的登到机器上,等登到机器上事情就闹大了
假设你要做一个新的rpc框架,你需要
- proto文件要能管理起来
- 生成文件组合到构建脚本之中 smfrpc框架的codegen很有意思,有机会可以研究一下
- 服务治理相关的能力,预留logger接口,预留的指标采集接口
- rpc消息染色怎么做?
- 熔断机制/限流机制
- 要不要做协议无关的rpc?tcp/http2 各有优点,某些场景协议特殊,比如sip,需要自己加seq管理
- rpc的io模型,future/promise?merge? Coroutine?
假设你要做一个使用rpc的服务,你需要
- 灵活的配置文件更新组件,查觉配置文件变动,重新加载 (可能需要公司级别的配置文件下发更新平台)
- 域名名字服务,最好用统一的
- 预留好日志logger,指标采集接口方便注入
- 灰度倒入流量怎么做?tcpcopy?
ref
-
知乎有个专栏,列了很多,可以参考 https://www.zhihu.com/column/c_1099707347118718976
-
https://colobu.com/2017/04/06/dive-into-gRPC-streaming/
-
一篇grpc-go的分析 https://segmentfault.com/a/1190000019608421
-
protobuf指南 https://blog.csdn.net/u011518120/article/details/54604615
-
一个future-promise rpc https://github.com/loveyacper/ananas/blob/master/docs/06_protobuf_rpc.md
-
腾讯的phxrpc https://github.com/Tencent/phxrpc
-
腾讯的tarsrpc 腾讯rpc真多啊 https://github.com/TarsCloud/TarsCpp
-
https://github.com/pfan123/Articles/issues/76 这个介绍了thrift

