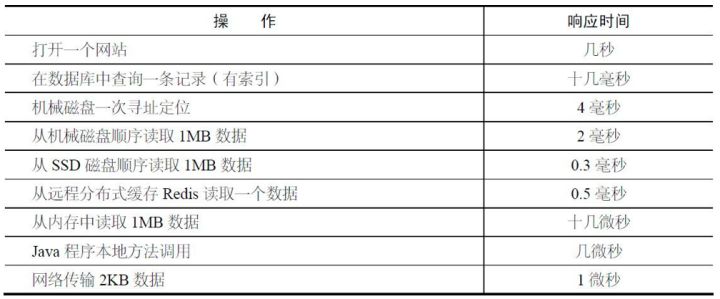
Linux/Unix系统编程手册 整理笔记
只列重点和延伸
基本概念
- 文件I/O模型
- 进程
- 内存布局,文本,数据,堆,栈
- _exit 退出 (实现是调用sys_exit退出,c标准库中的exit比这个函数多了一些清空IO 的动作,遇到过一次和log4cplus挂死的问题)
- 后面的章节会讲这个
- 进程的用户和组标识符,凭证,限定权限
- 特权进程,用户ID为0 的进程,内核权限限制对这种进程无效
- 不同用户的权限有不同的能力,可以赋予进程来执行或者取消特殊的能力 CAP_KILL
- init进程 所有进程之父 创建并监控其他进程
- 守护进程
- 环境列表 export setenv char **environ
- 资源限制 setrlimit()
- 内存映射 mmap
- 共享映射
- 同一文件
- fork继承
- 有标记来确认映射改动是否可见
- 共享映射
- 进程间通信以及同步
- 信号 ctrl c
-
管道 , FIFO, pipe - socket
- 文件锁定 (典型使用举例?)
- 消息队列 (典型使用举例?)
- 信号量
- 共享内存
- 进程组,信号传递 (典型使用举例?)(ctrl c?)
- 会话,控制终端和控制进程 ctrl c
- 伪终端,ssh
- 日期和时间 真实事件和进程时间 time(time有两个,另一个是看更细致的内核动作的)
- /proc文件系统
系统编程概念
- 系统调用
- 调用c wrapper函数,入参复制到寄存器,触发中断,切换到内核态,通过中断向量表找到系统调用
- 中断改成sysenter了
- 内核栈保存寄存器的值,校验系统编号,正式调用sysytemcall
- 可以用strace抓
- 调用c wrapper函数,入参复制到寄存器,触发中断,切换到内核态,通过中断向量表找到系统调用
- 库函数
- 版本号
- errno perror 封装一些错误处理和解析函数
- 可移植性问题,指的是一些宏开关,BSD POSIX GNU_SOURCE之类的
文件IO: 通用的IO模型
- open
- flag 只列有意思的,后面还会讲
- O_CLOEXEC fcntl
- O_NONBLOCK 非阻塞io
- O_ASYNC 信号驱动io, fcntl(file control)
- err
- 无法访问,目录问题,文件描述符上限,文件打开数目上限,文件只读,文件为exe
- flag 只列有意思的,后面还会讲
- read 返回值,错误-1没了0读到多少返回多少
- 内核维护读到那里,aka偏移量 lseek
- write 返回值,写入了多少。可能和指定的count不一致(磁盘满/RLIMIT_FSIZE)
- 偏移量超过文件结尾继续写入 aka文件空洞 eg: coredump
- 文件空洞占不占用?严格说占用,看空洞边界落在哪里,落在文件块内还是会分配空间的 用0填充
- 偏移量超过文件结尾继续写入 aka文件空洞 eg: coredump
-
ioctl (io control)
- 原子操作和竞争条件
- fcntl更改文件状态位
- 文件描述符与打开文件的关系
- 内核维护的数据结构
- 进程及文件描述符表
- fd
- flag
- 系统级打开文件表
- 文件句柄
- 文件偏移量,状态,访问模式,inode引用
- 文件系统inode表
- 文件类型,访问权限,锁指针,文件属性
- 多个文件描述符可以对应同一个句柄,共用同一个偏移量
- 复制文件描述符 dup/dup2 2>&1
- O_CLOSEXEC 描述符私有
- 进程及文件描述符表
- 内核维护的数据结构
- 特定偏移 pread pwrite
- 分散输入和集中输出scatter-gather readv writev
- 阶段文件truncate ftruncate
- 大文件IO
- /dev/fd ?
进程
- pstree
- 内存布局
- 虚拟内存管理
- 空间局部性和时间局部性
- 驻留集 resident set和交换区swap area
- 有效虚拟地址范围发生变化
- 栈增长到之前没到过的地方
- malloc brk sbrk提升program break位置
- 共享内存访问 shmat shmdt
- mmaSp/munmap
- 地址空间隔离的有点
- 进程进程 进程内核间隔离
- 共享内存
- 同一份代码副本
- shmget mmap共享内存
- 内存保护
- 每个进程使用的真实内存少,使得容纳的进程多,CPU利用率高
- 栈和栈帧 不多说
- 环境 env 不多说
- setjmp longjmp 别用
内存分配
- 堆当前边界 program break
- 调整边界brk/sbrk
- malloc free实现,老生常谈了
- 调试malloc
- mtrace muntrace 搭配MALLOC_TRACE mtrace 分析文件写入
- mcheck mprobe 一致性检查分析
- MALLOC_CHECK_ 环境变量,提供上面的功能,动态的,安全原因,设置用户id组id的程序无法设置
- glibc检测 mallopt mallinfo
- 调试malloc
- calloc realloc
- 对齐分配 memalign posix_memalign
- 栈上分配alloca
- 邪门歪道别乱用

页帧分配(Page frame allocation)
页是物理内存或虚拟内存中一组连续的线性地址,Linux内核以页为单位处理内存,页的大小通常是4KB。当一个进程请求一定量的页面时,如果有可用的页面,内核会直接把这些页面分配给这个进程,否则,内核会从其它进程或者页缓存中拿来一部分给这个进程用。内核知道有多少页可用,也知道它们的位置。
伙伴系统(Buddy system)
Linux内核使用名为伙伴系统(Buddy system)的机制维护空闲页,伙伴系统维护空闲页面,并且尝试给发来页面申请的进程分配页面,它还努力保持内存区域是连续的。如果不考虑到零散的小页面可能会导致内存碎片,而且在要分配一个连续的大内存页时将变得很困难,这就可能导致内存使用效率降低和性能下降。下图说明了伙伴系统如何分配内存页。

如果尝试分配内存页失败,就启动回收机制。可以在/proc/buddyinfo文件看到伙伴系统的信息。
页帧回收
如果在进程请求指定数量的内存页时没有可用的内存页,内核就会尝试释放特定的内存页(以前使用过,现在没有使用,并且基于某些原则仍然被标记为活动状态)给新的请求使用。这个过程叫做内存回收。kswapd内核线程和try_to_free_page()内核函数负责页面回收。
kswapd通常在task interruptible状态下休眠,当一个区域中的空闲页低于阈值的时候,它就会被伙伴系统唤醒。它基于最近最少使用原则(LRU,Least Recently Used)在活动页中寻找可回收的页面。最近最少使用的页面被首先释放。它使用活动列表和非活动列表来维护候选页面。kswapd扫描活动列表,检查页面的近期使用情况,近期没有使用的页面被放入非活动列表中。使用vmstat -a命令可以查看有分别有多少内存被认为是活动和非活动状态。
kswapd还要遵循另外一个原则。页面主要有两种用途:页面缓存(page cahe)和进程地址空间(process address space)。页面缓存是指映射到磁盘文件的页面;进程地址空间的页面(又叫做匿名内存,因为不是任何文件的映射,也没有名字)使用来做堆栈使用的,在回收内存时,kswapd更偏向于回收页面缓存。
Page out和swap out:“page out”和“swap out”很容易混淆。“page out”意思是把一些页面(整个地址空间的一部分)交换到swap;”swap out”意味着把所有的地址空间交换到swap。
如果大部分的页面缓存和进程地址空间来自于内存回收,在某些情况下,可能会影响性能。我们可以通过/proc/sys/vm/swappiness文件来控制这个行为
swap
在发生页面回收时,属于进程地址空间的处于非活动列表的候选页面会发生page out。拥有交换空间本身是很正常的事情。在其它操作系统中,swap无非是保证操作系统可以分配超出物理内存大小的空间,但是Linux使用swap的空间的办法更加高效。如图1-12所示,虚拟内存由物理内存和磁盘子系统或者swap分区组成。在Linux中,如果虚拟内存管理器意识到内存页已经分配了,但是已经很久没有使用,它就把内存页移动到swap空间。
像getty这类守护进程随着开机启动,可是却很少使用到,此时,让它腾出宝贵的物理内存,把内存页移动到swap似乎是很有益的,Linux正是这么做的。所以,即使swap空间使用率到了50%也没必要惊慌。因为swap空间不是用来说明内存出现瓶颈,而是体现了Linux的高效性。
ps -o majflt,minflt -p pid
minor fault 在内核中,缺页中断导致的异常叫做page fault。其中,因为filemap映射导致的缺页,或者swap导致的缺页,叫做major fault;匿名映射导致的page fault叫做minor fault。 作者一般这么区分:需要IO加载的是major fault;minor fault则不需要IO加载
用户和组
-
密码与密码文件/etc/shadow
-
/etc/group
跳过了,没啥说的。
进程凭证
讲了一大堆关于用户组,权限之类的东西
时间
- gettimeofday
- time 多余的
- ctime打印用
- 时区TZ
- 地区LC_ALL
- 软件时钟jiffies
- 进程时间
- time命令,有两个
系统限制和选项
- sysconf getconf pathconf
系统和进程信息
-
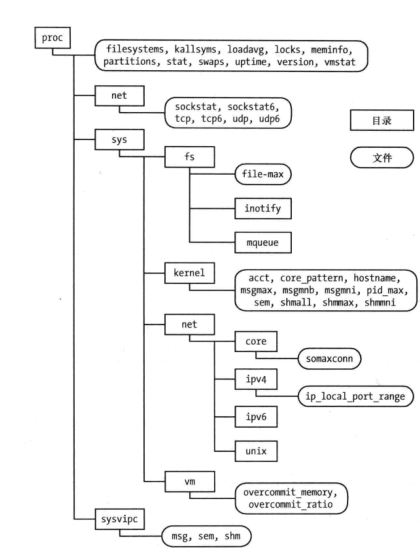
/proc
-
cat /proc/pid/status
-
关注env status cwd fd maps mem mounts task
-
-
uname
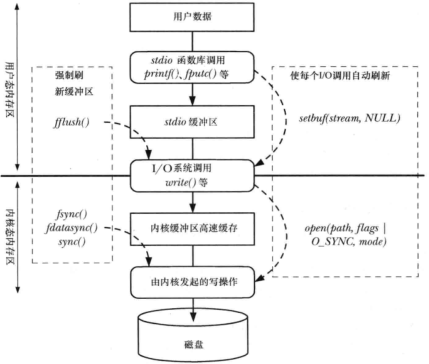
文件IO缓冲
-
用户空间缓冲区和内核空间缓冲区之间的数据复制,不会直接发起磁盘访问
-
系统调用越少越好
-
刷新stdio fflush
-
fsync 刷盘,包括元数据更新 fdatafync可能会减少磁盘操作的次数
- 写入同步O_SYNC
-
绕过缓存 直接IO O_DIRECT
- 必须对齐
系统编程概念
- 设备文件 /dev
- 字符型设备 终端键盘
- 块设备,磁盘,512倍数
- 文件系统
- 引导块,超级块 i节点表 数据块
- inode 文件元数据
- 数据块指针
- lseek,算指针就行了
- 数据块指针
- VFS
- 日志文件系统
- 挂载mount 太复杂了。我还是现搜现用吧
- tmpfs
文件属性 没啥说的
- stat
- chown
-
utime
- 扩展属性setattr
目录与链接
- 软链接硬链接 没啥说的,inode
- unlink
- raname
- nftw遍历目录树? 没发现啥使用场景
监控文件事件
inotify可以和epoll串起来
和内核交互,会耗费内核内存,所以有限制
/proc/sys/fs/inotify
信号
signal handler
kill 发送信号
- raise相当于自己调用kill(getpid(),sig)
- killpg
信号掩码,没用过
可重入要考虑
终止signal handler
- _exit, exit不安全,这是个典型问题了 exit会刷stdio,可能会卡死
- kill
- abort
- setjmp longjmp 有点魔法,没见过谁用
系统调用期间遇到的信号 -EINTR, 可能系统调用体检结束失败了。
利用这个特性,可以为阻塞调用设置一个定时器
也可以手动重启调用
- 对应有个NO_EINTR的宏
#define NO_EINTR(stmt) while((stmt) == -1 && errno = EINTR)
这样循环执行忽略EINTR错误,比较不方便,但我感觉直接屏蔽信号更好一些
- 用sigaction指定SA_RESTART让内核帮助重试调用,但是这只是部分有效,比如poll这些肯定是无效的
高级特性
- core文件
- /proc/sys/kernel/core_pattern
- TASK_INTERRUPTIBLE -> S , TASK_UNINTERRUPTIBLE -> D
- 如果用了信号阻塞,信号恢复后怎么传递?序号升序 ,越小优先级越高
- signal函数用sigaction实现的。
定时器和休眠
settitimer alarm
alarm会让阻塞的系统调用产生EINTR,也就是超时结束了
但这东西可能有竞态问题,还是用select /poll超时特性更好,还能整合到轮训框架内
nanosleep
进程
创建
- 父子进程文件共享
- fd操作文件表项,包含当前文件原信息,修改会互相影响
- 父子进程谁先谁后?
- 2.6.32之后默认父在前,有点点性能优势,但差异很小
- 同步信号规避竞争
终止
- _exit和exit说了好几遍了
- exit会主动调用atexit/on_exit注册函数,清理stdio,然后在调用_exit所以期间可能会锁死
- main函数return n等于exit(n)
- 更多终止细节
- 关闭打开的文件描述符 目录流各种描述符
- 释放各种文件锁
- 分离各种共享内存段
- 如果不是daemon,会向终端发送SIGHUP
- system v信号量 semadj +到信号量值里(没懂这块)
- 关闭各种posix有名信号量sem_close
- 关闭各种posix消息队列 mq_close
- 进程组孤儿 SIGHUP + SIGCONT?
- 溢出各种内存所mlock
- 取消各种内存映射mmap
fork和stdio缓冲区的问题
书中的例子printf是有’\n’的
输出到终端是行缓冲会直接刷新到终端,输出到文件是块缓冲,不会立即刷到文件,这就复制了两份缓冲区
如果printf没有‘\n’还是会有缓冲区的问题
标准输出是行缓冲,所以遇到“\n”的时候会刷出缓冲区,但对于磁盘这个块设备来说,“\n”并不会引起缓冲区刷出的动作,那是全缓冲
看参考链接 1 2能加深理解
解决方法,
- 手动flush
- 手动设置缓冲为0 setvbuf
- 子进程_exit跳过刷新缓冲区
孤儿进程和僵尸进程
- 需要父进程wait,不然占用内核空间
- 主动处理SIGCHLD或者子进程忽略SIGCHLD 直接系统丢弃子进程状态
文件描述符与exec
FD_CLOSEXEC
为什么system实现要阻塞SIGCHLD,忽略SIGINT和SIGQUIT信号?
线程
-
errno一个线程一个
- pthread api返回值
- 链接带上lpthread
- 可重入函数要注意
创建线程
- pthread_create
- pthread_self获取
终止线程
- 线程函数return/exit
- pthread_exit
- pthread_join获取返回值
-
pthread_cancel
- thread_join 类似waitpid
- 特定的tid(waitpid可以任意pid)
- 阻塞的(可以自己用condvar搞非阻塞)
- 对等的(waitpid只能是父等子)
- pthread_detach
- pthread_attr_init 属性设置
更多细节
- 线程栈
- 线程和信号
线程同步
互斥量mutex -> futex虽然慢也比fcntl信号量这种系统调用要快
注意死锁
condvar 经典问题,为啥用while守着signal
线程安全
可重入
一次性初始化 pthread_once std::call_once
一个线程安全的singleton是什么样的
进程组 会话和作业控制
find / 2> /dev/null | wc -l &
find命令和wc命令同进程组
find命令和wc命令和当前bash同会话,bash是会话首进程
一个终端也就只有一个会话
前台进程和后台进程组,前台进程就一个or没有
进程控制 nohup SIGHUP
作业控制 jobs
进程优先级和调度
nice值和分配策略
cpu亲和
使用的资源与资源限制
防范
-
特权?
- chroot jail?
- 缓冲区溢出
- 不可信用户输入
- DDoS
能力
- 用户ID ?root?
daemon
永远不会成为会话组长,也就永远不会成为控制终端
关掉不用的0 1 2,不要浪费文件描述符
共享库
使用共享库的有用工具
- ldd
- readelf/objdump
- nm
版本与命名规则
进程间通信
通信工具
- 数据传输工具
- 字节流 :文件是一个字节序列 读取动作是消耗性质的
- 管道
- FIFO
- 数据报socket
- 消息队列
- system V消息队列
- posix 消息队列
- 数据报socket交换
- 伪终端
- 字节流 :文件是一个字节序列 读取动作是消耗性质的
- 共享内存 速度快但是需要同步 所有进程都可见
- system V共享内存
- posix共享内存
- 内存映射
同步工具
- 信号量
- 文件锁
- mutex condvar
- 通信工具也可以用来同步,pipe eventfd
管道pipe 和FIFO
管道
- 字节流,单向
- 容量有限,写入阻塞
- 进程同步方法
- 管道和缓冲
- 伪终端替换管道
FIFO aka命名管道
屏蔽SIGPIPE
阻塞IO 非阻塞IO设置?
system v ipc
消息队列/信号量/共享内存
ipc key:整数 IPR_PRIVATE/ftok
ipcs ipcrm 类似ls rm
ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
0x00001f4f 0 Ruby 666 0 0
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
获取ipc对象列表
/proc/sysvipc
cat /proc/sysvipc/msg
key msqid perms cbytes qnum lspid lrpid uid gid cuid cgid stime rtime ctime
8015 0 666 0 0 0 0 3000 3000 3000 3000 0 0 1598235273
查看限制
ipcs -l
------ Messages Limits --------
max queues system wide = 963
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 0
max total shared memory (kbytes) = 18014398442373116
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
消息队列
无法结合内核本身的文件描述符系统
标识符引用,键(key)复杂度都省
无连接,涉及到资源管理就会很糟糕
- 什么时候删除?
- 应用怎么保证不用的资源被删除?
避免使用system v ipc消息队列
信号量
进程同步 尤其是共享内存
共享内存
所处位置
全是偏移
内存映射
mmap munmap
支持映射文件
- 省一步写,能快点
虚拟内存操作
mprotect mlock mincore
madvise 内存使用建议
posix ipc
消息队列 信号量 共享内存 用fd管理
信号量和共享内存api和system v的api差不多。都挺复杂
文件加锁
加锁与stdio缓冲问题
flock
fcntl
socket
创建fd(socket) 绑定fd(bind) 监听(listen, backlog含义,系统未accept之前的客户端connect占用的fd最大个数)
接受connect( accept, 返回连接的fd,操作这个fd进行通信)
客户端主动发起connect(失败?)
close没啥说的,得结合时序图才有意思
unix domain socket 本机通信用
tcp/ip
数据链路层隐藏
网络层无连接不可靠
传输层
TCP
- 数据打包成段
- 确认重传以及超时
- 排序
- 流量控制
- 拥塞控制:慢启动和拥塞避免算法
UDP 注意分段
网络相关
- 网络字节序, 大端
- 主机服务转换函数
- gethostbyname废弃,inet_ntop getaddrinfo
服务设计
- 迭代型
- 并发性
- 预先准备好线程/进程 服务池
- 集群
- IO复用怎么没提?
inetd
高级主题
- 部分读部分写
- shutdown关闭一半
- 深入TCP
- 报文格式
- 确认机制
- 状态机
- 建立和终止
- listen被动打开
- connect主动打开
- close主动关闭,另一侧也执行close,被动关闭
- TIME_WAIT
- 可靠的断开,2MSL
netstat -a –inet
tcpdump抓流量
- socke选项
- SO_REUSEADDR
其他IO模型
水平触发和边缘处罚 LT ET
select poll是水平触发,信号驱动IO是边缘触发,epoll都支持
水平触发可以任意时刻查看fd的就绪状态,处理不完继续处理
边缘触发一次就得处理完,采取边缘触发的程序设计规则
- 接收到IO时间尽可能多的执行IO,如果没这么做可能会失去至此那个的机会,数据丢失程序阻塞
- 也就是说这种动作可能会饿到fd,比如上一组动作没处理完,这一组又在等待
- 如果程序采用循环来处理fd尽可能多,而fd优势阻塞的,这样整个IO调用就阻塞住了,所以必须要改成非阻塞模式,有事件就重复执行IO直到失败为止
- 对于epoll而言是这样的
- 所有fd非阻塞
- epoll_ctl管理fd列表
- 循环
- epoll_wait拿到就绪fd
- 不断执行执行IO系统调用(read/write/send/accept/recv)直到EAGAIN到EWOULDBLOCK
- 对于epoll而言是这样的
- 针对其他的fd会饿到的风险场景
- 用一个列表维护一下有过就绪态的fd,把他们的超时时间调小(分给他们的时间片调小)
- 维护的列表中已经出现过的,操作要稍微调度一下,rr之类的,而不是直接处理epoll_wait返回的列表,如果出现了错误,就移除
self-pipe技术。不多数
终端, 伪终端
CR EOF DISCARD
stty命令
ref
-
https://www.veaxen.com/fork%E5%AF%B9%E8%A1%8C%E7%BC%93%E5%86%B2%E5%8C%BA%E7%9A%84%E5%BD%B1%E5%93%8D.html
-
https://coolshell.cn/articles/7965.html
-
mmap实现cp https://stackoverflow.com/questions/27535033/copying-files-using-memory-map