关注了anna用的也是fbs, smf rpc框架用的也是fbs
anna感觉技术更像是seastar那套
类似protobuf的介绍,先关注一下使用细节
// Example IDL file for our monster's schema.
namespace MyGame.Sample;
enum Color:byte { Red = 0, Green, Blue = 2 }
union Equipment { Weapon } // Optionally add more tables.
struct Vec3 {
x:float;
y:float;
z:float;
}
table Monster {
pos:Vec3; // Struct.
mana:short = 150;
hp:short = 100;
name:string;
friendly:bool = false (deprecated);
inventory:[ubyte]; // Vector of scalars.
color:Color = Blue; // Enum.
weapons:[Weapon]; // Vector of tables.
equipped:Equipment; // Union.
path:[Vec3]; // Vector of structs.
}
table Weapon {
name:string;
damage:short;
}
root_type Monster;
Tables
-
新增字段只能增加在table定义末尾, 比如旧版本schema定义 table { a:int; b:int;},新版本新增一个字段在末尾table { a:int; b:int; c:int; },那么
- 用旧版本schema读取新的数据结构会忽略新字段 c 的存在,因为新增字段在末尾。
- 用新版本schema读取旧的数据结构,将会取到新增字段的默认值。
如果新增字段出现在中间,会导致版本不兼容问题。 table { a:int; c:int; b:int; } - 用旧版本schema读取新的数据结构,读取b字段的时候,会读取到c字段 - 用新版本schema读取旧的数据结构,读取c字段的时候,会读取到b字段
如果不想新增字段到末尾,用id属性可以实现 table { c:int (id: 2); a:int (id: 0); b:int (id: 1); } 引入 id 以后,table 中的字段顺序就无所谓了,新的与旧的 schema 完全兼容,只要我们保留 id 序列即可。
用id的方案和PB一致
-
schema不能删除任何字段,写数据的时候可以不再写废弃字段的值,在schema中把这个字段标记为deprecated,那么生成的代码里就不会出现废弃字段。table { a:int (deprecated); b:int; }
- 用旧版本schema读取新的数据结构,将会取到字段a的默认值,因为不存在。
- 用新版本schema不能读取也不能写入字段a,会导致编译错误
-
可以改变字段类型,在类型大小相同情况下代码随之改动,是ok的。比如 table { a:uint; b:uint; } -> table { a:int = 1; b:int = 2; } 代码必须保证正确性。
Structs
和Table类似,区别是没有字段是optional的,字段不能增加或者废弃deprecation。Structs只接受标量或者其他Structs。使用这个对象的时候,必须是非常确定这个结构将来不会任何改动。Structs比Table内存占用更少,检索速度更快。
Types
build-in标量类型有
- 8 bit: byte (int8), ubyte (uint8), bool
- 16 bit: short (int16), ushort (uint16)
- 32 bit: int (int32), uint (uint32), float (float32)
- 64 bit: long (int64), ulong (uint64), double (float64) 括号内名称可以相互替换,不会影响代码生成。
build-in非标量类型有
- 任何类型的数组。不过不支持嵌套数组,可以用 table 内定义数组的方式来取代嵌套数组。
- UTF-8 和 7-bit ASCII 的字符串。其他格式的编码字符串或者二进制数据,需要用 [byte] 或者 [ubyte] 来替代。
- table、structs、enums、unions
这些字段的类型一旦使用之后就无法再更改,可以用reinterpret_cast强转,比如如果当前数据的最符号位没有值得话,可以将uint强转成int。
Attributes
Attributes 可以附加到字段声明,放在字段后面或者 table/struct/enum/union 的名称之后。这些字段可能有值也有可能没有值。
一些 Attributes 只能被编译器识别,比如 deprecated。用户也可以定义一些 Attributes,但是需要提前进行 Attributes 声明。声明以后可以在运行时解析 schema 的时候进行查询。这个对于开发一个属于自己的代码编译/生成器来说是非常有用的。或者是想添加一些特殊信息(一些帮助信息等等)到自己的 FlatBuffers 工具之中。
目前最新版能识别到的 Attributes 有 11 种。
id:n (on a table field)
id 代表设置某个字段的标识符为 n 。一旦启用了这个 id 标识符,那么所有字段都必须使用 id 标识,并且 id 必须是从 0 开始的连续数字。需要特殊注意的是 Union,由于 Union 是由 2 个字段构成的,并且隐藏字段是排在 union 字段的前面。(假设在 union 前面字段的 id 排到了6,那么 union 将会占据 7 和 8 这两个 id 编号,7 是隐藏字段,8 是 union 字段)添加了 id 标识符以后,字段在 schema 内部的相互顺序就不重要了。新字段用的 id 必须是紧接着的下一个可用的 id(id 不能跳,必须是连续的)。deprecated (on a field)
deprecated 代表不再为此字段生成访问器,代码应停止使用此数据。旧数据可能仍包含此字段,但不能再通过新的代码去访问这个字段。请注意,如果您弃用先前所需的字段,旧代码可能无法验证新数据(使用可选验证器时)。required (on a non-scalar table field)
required 代表该字段不能被省略。默认情况下,所有字段都是可选的,即可以省略。这是可取的,因为它有助于向前/向后兼容性以及数据结构的灵活性。这也是阅读代码的负担,因为对于非标量字段,它要求您检查 NULL 并采取适当的操作。通过指定 required 字段,可以强制构建 FlatBuffers 的代码确保此字段已初始化,因此读取的代码可以直接访问它,而不检查 NULL。如果构造代码没有初始化这个字段,他们将得到一个断言,并提示缺少必要的字段。请注意,如果将此属性添加到现有字段,则只有在现有数据始终包含此字段/现有代码始终写入此字段,这两种情况下才有效。force_align: size (on a struct)
force_align 代表强制这个结构的对齐比它自然对齐的要高。如果 buffer 创建的时候是以 force_align 声明创建的,那么里面的所有 structs 都会被强制对齐。(对于在 FlatBufferBuilder 中直接访问的缓冲区,这种情况并不是一定的)bit_flags (on an enum)
bit_flags 这个字段的值表示比特,这意味着在 schema 中指定的任何值 N 最终将代表1 « N,或者默认不指定值的情况下,将默认得到序列1,2,4,8 ,…nested_flatbuffer: "table_name" (on a field)
nested_flatbuffer 代表该字段(必须是 ubyte 的数组)嵌套包含 flatbuffer 数据,其根类型由 table_name 给出。生成的代码将为嵌套的 FlatBuffer 生成一个方便的访问器。flexbuffer (on a field)
flexbuffer 表示该字段(必须是 ubyte 的数组)包含 flexbuffer 数据。生成的代码将为 FlexBuffer 的 root 创建一个方便的访问器。key (on a field)
key 字段用于当前 table 中,对其所在类型的数组进行排序时用作关键字。可用于就地查找二进制搜索。hash (on a field)
这是一个不带符号的 32/64 位整数字段,因为在 JSON 解析过程中它的值允许为字符串,然后将其存储为其哈希。属性的值是要使用的散列算法,即使用 fnv1_32、fnv1_64、fnv1a_32、fnv1a_64 其中之一。original_order (on a table)
由于表中的元素不需要以任何特定的顺序存储,因此通常为了优化空间,而对它们大小进行排序。而 original_order 阻止了这种情况发生。通常应该没有任何理由使用这个标志。- ‘native_*’
已经添加了几个属性来支持基于 C++ 对象的 API,所有这些属性都以 “native_” 作为前缀。具体可以点链接查看支持的说明,
native_inline、native_default、native_custom_alloc、native_type、native_include: "path"
Enums
enum Color : byte { Red = 1, Green, Blue } 定义一系列命名常量,每个命名常量可以分别给一个定值,也可以默认的从前一个值增加一。默认的第一个值是 0。enum声明的时候可以指定底层的整数类型,只能指定整数类型。 enum只能增加,不能删除或者废弃deprecation,因此代码必须保证兼容性,处理未知的枚举值。
Unions
Unions和Enums有很多类似之处,但是union包含的是table,enum包含的是scalar或者 struct。 可以声明一个 Unions 字段,该字段可以包含对这些类型中的任何一个的引用,即这块内存区域只能由其中一种类型使用。另外还会生成一个带有后缀 _type 的隐藏字段,该字段包含相应的枚举值,从而可以在运行时知道要将哪些类型转换为类型。
Namespaces
C++代码中生成namespace,Java代码中生成package
Includes
包含另一个schama文件,保证每个文件可以不被多次引用,但是只被解析一次。
Root type
声明序列化数据中的根表root table,在解析JSON数据时尤为重要,因为他们不包含对象信息。
设计建议
由于 FlatBuffers 的灵活性和可扩展性,将任何类型的数据表示为字典(如在 JSON 中)是非常普遍的做法。尽管可以在 FlatBuffers(作为具有键和值的表的数组)中模拟这一点,但这对于像 FlatBuffers 这样的强类型系统来说,这样做是一种低效的方式,会导致生成相对较大的二进制文件。在大多数系统中,FlatBuffer table 比 classes/structs 更灵活,因为 table 在处理 field 数量非常多,但是实际使用只有其中少数几个 field 这种情况,效率依旧非常高。因此,组织数据应该尽可能的组织成 table 的形式。
同样,如果可能的话,尽量使用枚举的形式代替字符串。
FlatBuffers 中没有继承的概念,所以想表示一组相关数据结构的方式是 union。但是,union 确实有成本,另外一种高效的做法就是建立一个 table 。如果这些数据结构有很多相似或者可以共享的 field ,那么建议一个 table 是非常高效的。在这个 table 中包含所有数据结构的所有字段即可。高效的原因就是 optional 字段是非常廉价的,消耗少。
FlatBuffers 默认可以支持存放的下所有整数,因此尽量选择所需的最小大小,而不是默认为 int/long。
可以考虑用 buffer 中一个字符串或者 table 来共享一些公共的数据,这样做会提高效率,因此将重复的数据拆成共享数据结构 + 私有数据结构,这样做是非常值得的。
CURD
// 写
flatbuffers::FlatBufferBuilder builder(1024);
// 用builder.createxx创建基本类型
auto weapon_one_name = builder.CreateString("Sword");
short weapon_one_damage = 3;
auto weapon_two_name = builder.CreateString("Axe");
short weapon_two_damage = 5;
// Use the `CreateWeapon` shortcut to create Weapons with all the fields set.
auto sword = CreateWeapon(builder, weapon_one_name, weapon_one_damage);
auto axe = CreateWeapon(builder, weapon_two_name, weapon_two_damage);
// Create the position struct
auto position = Vec3(1.0f, 2.0f, 3.0f);
// Set his hit points to 300 and his mana to 150.
int hp = 300;
int mana = 150;
// Finally, create the monster using the `CreateMonster` helper function
// to set all fields.
auto orc = CreateMonster(builder, &position, mana, hp, name, inventory,
Color_Red, weapons, Equipment_Weapon, axe.Union(),
path);
// You can use this code instead of `CreateMonster()`, to create our orc
// manually.
MonsterBuilder monster_builder(builder);
monster_builder.add_pos(&position);
monster_builder.add_hp(hp);
monster_builder.add_name(name);
monster_builder.add_inventory(inventory);
monster_builder.add_color(Color_Red);
monster_builder.add_weapons(weapons);
monster_builder.add_equipped_type(Equipment_Weapon);
monster_builder.add_equipped(axe.Union());
auto orc = monster_builder.Finish();
builder.Finish(orc);
// This must be called after `Finish()`.
uint8_t *buf = builder.GetBufferPointer();
int size = builder.GetSize(); // Returns the size of the buffer that
// `GetBufferPointer()` points to.
//这一套下来就可以直接拷贝/传range了
// 读
uint8_t *buffer_pointer = /* the data you just read */;
// Get a pointer to the root object inside the buffer.
auto monster = GetMonster(buffer_pointer);
auto hp = monster->hp();
auto mana = monster->mana();
auto name = monster->name()->c_str();
auto pos = monster->pos();
auto x = pos->x();
auto y = pos->y();
auto z = pos->z();
// 原地改,接口类似pb的mutable_xx
auto monster = GetMutableMonster(buffer_pointer); // non-const
monster->mutate_hp(10); // Set the table `hp` field.
monster->mutable_pos()->mutate_z(4); // Set struct field.
monster->mutable_inventory()->Mutate(0, 1); // Set vector element.
参考链接
- 教程 https://google.github.io/flatbuffers/flatbuffers_guide_tutorial.html
- https://halfrost.com/flatbuffers_schema/
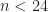 elements, use
elements, use  elements
elements , use
, use