(译)现代存储硬件足够快啦就是老api不太好用
这里存储设备指的optane这种原文简单整理,用deepl翻译的
作者是老工程师了,列出了常见的几种对存储的误解
- IO比复制更重,所以复制数据代替直接读是合理的,因为省了一次IO
- “我们设计的系统要非常快,所以全放在内存里是必须的”
- 文件拆分成多个反而会慢,因为会产生随机IO 不如直接从一个文件里读,顺序的
- Direct IO非常慢,只适用于特殊的设备,如果没有对应的cache支持,会很糟糕
作者的观点是,现在设备非常牛逼,以前的api有很多设计不合理的地方,各种拷贝,分配 ,read ahead等等操作过于昂贵
即:传统api的设计是因为IO昂贵,所以做了些昂贵的动作来弥补
- 读没读到 cache-miss -> 产生page-fault 加载数据到内存 -> 读好了,产生中断
- 如果是普通用户态进程,再拷贝一份给进程
- 如果用了mmap,要更新虚拟页
在以前,IO很慢,对比来说这些更新拷贝要慢一百倍,所以这些也无足轻重,但是现在IO延迟非常低,可以看三星nvme ssd指标,基本上耗时数量级持平
简单计算,最坏情况,设备耗时也没占上一半,时间都浪费在哪里了?这就涉及到第二个问题 读放大
操作系统读数据是按照页来读,每次最低4k,如果你读一个1k的数据,这个文件分成了两个,那也就是说,你要用8k的页读1k的数据,浪费87%,实际上,系统也预读(read ahead) 每次默认预读128k,方便后面继续读,那也就是说相当于用256k来读1k,非常恐怖的浪费
那么 用direct IO直接读怎么样,不会有页浪费了吧
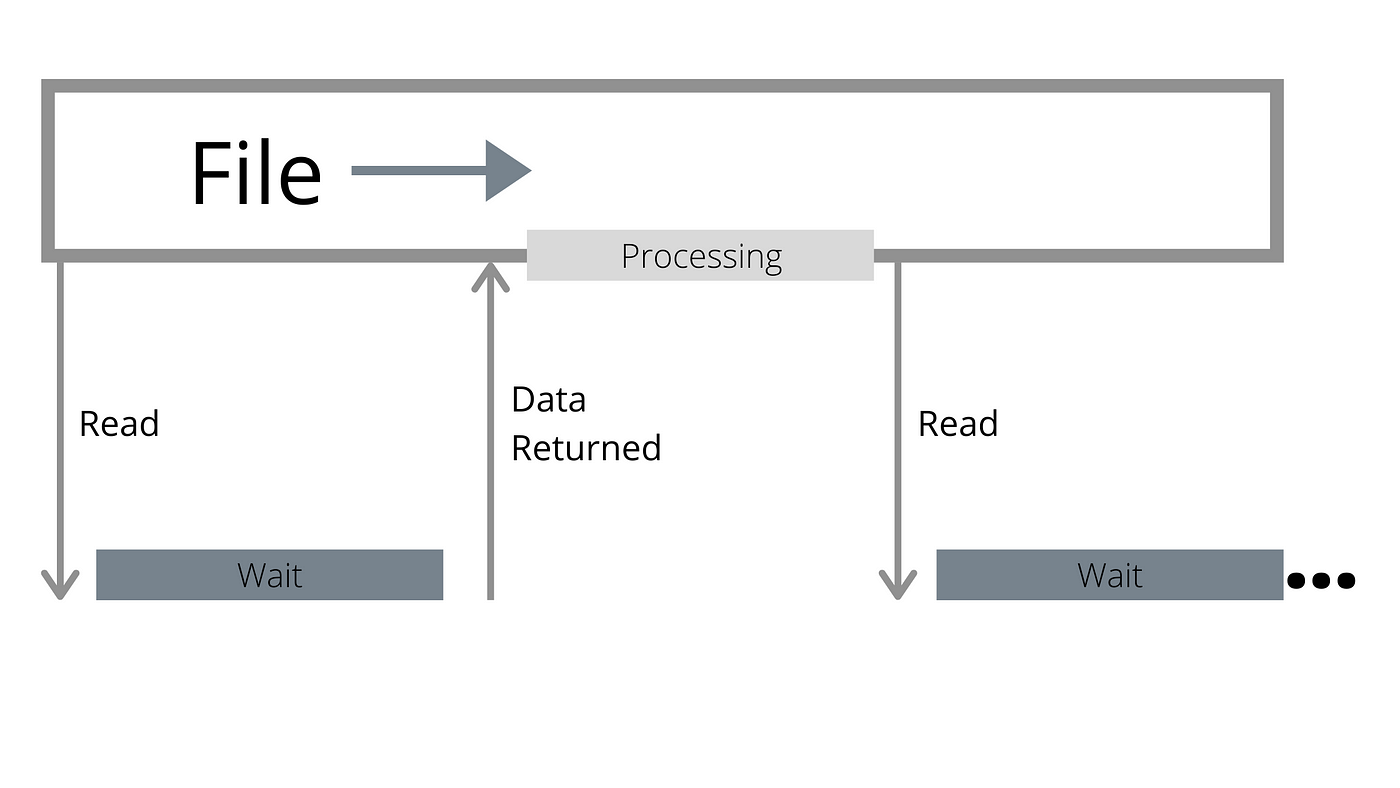
问题还在,老api并不是并发读,尽管读的快但是比cpu还是慢,阻塞,还是要等待
所以又变成多文件,提高吞吐,但是
- 多文件又有多的read ahead浪费,
- 而且多文件可能就要多线程,还是放大,如果你并没有那么多文件,这个优化点也用不上
新的api
io_uring是革命性的,但还是低级的api:
- io_uring的IO调度还是会收到之前提到的各种缓存问题影响
- Direct IO有很多隐藏的条件(caveats 注释事项) 比如只能内存对齐读,io_uring作为新api对于类似的问题没有任何改进
为了使用io_uring你需要分批积累和调度,这就需要一个何时做的策略,以及某种事件循环
为此,作者设计了一个io框架glommio Direct IO,基于轮训,无中断 register-buffer
Glommio处理两种文件类型
- 随机访问文件
- 不需要缓冲区,直接用io_uring注册好的缓冲区拿过来用,没有拷贝,没有内存映射,用户拿到一个引用计数指针
- 因为指导这是随机IO,要多少读多少
- 流文件
- 设计的和rust的asyncread一样,多一层拷贝,也有不用拷贝的api
作者列出了他的库做的抽象拿到的数据,和bufferred io做比较
| bufferred IO | DirectIO(glommed) | +开启预读 read ahead 提高并发度 | +使用避免拷贝的api | + 增大buffer | |
|---|---|---|---|---|---|
| 53G 2x内存 顺序读sequential | 56s, 945.14 MB/s | 115s, 463.23 MB/s | 22s, 2.35 GB/s | 21s, 2.45 GB/s | 7s, 7.29 GB/s |
注意,随机读+ scan对内存page cache污染比较严重
在小的数据集下
Buffered I/O: size span of 1.65 GB, for 20s, 693870 IOPS
Direct I/O: size span of 1.65 GB, for 20s, 551547 IOPS
虽然慢了一点,但是内存占用上有优势
对于大的数据,优势还是比较明显的,快三倍
Buffered I/O: size span of 53.69 GB, for 20s, 237858 IOPS
Direct I/O: size span of 53.69 GB, for 20s, 547479 IOPS
作者的结论是 新时代新硬件direct IO还是非常可观的,建议相关的知识复习一下
ref/ps
- https://github.com/DataDog/glommio 有时间仔细看看 这个作者之前是做seastar的,seastar是DirectIO+Future/Promise
- 详细介绍的文档 https://www.datadoghq.com/blog/engineering/introducing-glommio/
- 代码文档 https://docs.rs/glommio/0.2.0-alpha/glommio/
