lmdb boltdb原理介绍
29 Mar 2021
|
|
lmdb是基于mmap的。还好是嵌入式的小kv,选择mmap可以理解,不过不推荐
boltdb是借鉴lmdb的思想用go重写的,boltdb的资料非常多。
lmdb是基于mmap的。还好是嵌入式的小kv,选择mmap可以理解,不过不推荐
boltdb是借鉴lmdb的思想用go重写的,boltdb的资料非常多。
看tag知内容
MVCC 的技术要点,包括:
通过预先计算顺序的方式来控制并发;事务的读操作返回最新的没有被写锁锁定数据的版本;事务的写操作过程如下:
在 MVOCC 中,事务被分成三个阶段,分别是:
顾名思义,MV2PL 是传统的两阶段锁在多版本并发控制中的应用;事务读写或者创建数据版本都需要获得对应的锁。
可串行化快照隔离(serializable snapshot isolation或SSI)是在快照隔离级别之上,支持串行化。PosgtreSQL 中实现了这种隔离级别,数据库通过维护一个串行的图移除事务并发造成的危险结构。

数据库通过无锁指针链表维护多个版本,使得事务可以方便的读取特定版本的数据。

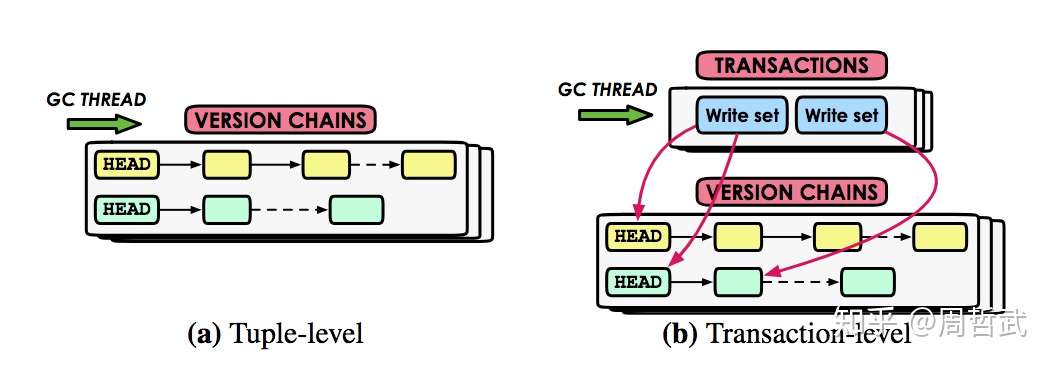
MVCC 在事务过程中不可避免的会产生很多的旧版本,这些旧版本会在下列情况下被回收
通过检查数据来判断是否需要回收旧版本,有两种做法:
事务自己追踪旧版本,数据库管理系统不需要通过扫描数据行的方式来判断数据是否需要回收。
数据有多个版本,而索引只有一份,更新和维护多个版本的时候如何同步索引?
主键一般指向多版本链表头
有两种做法,逻辑指针和物理地址;前者通过增加一个中间层的方式实现,缩影指向该中间层,中间层指向数据的物理地址,避免应为多版本的物理地址改变引起的索引树的更新;后者索引直接指向数据物理地址。
##
实现
mongo mvcc
https://segmentfault.com/a/1190000023333915
pg mvcc
https://zhuanlan.zhihu.com/p/56108935
Cockroach事务机制中的几个概念:
事务运行流程中的几个关键状态:
Key的格式:
key + intend + candidate commit timestamp
key + latest read timestamp
持久化后,每个key/values 按照事务提交时间记录了多个版本格式:
key + version1( timestamp)* key+ version2( timestamp) Cockroach 事务实现原理 如果每个事务串行执行,事务的处理就会变的极为简单:加全局锁,执行事务。但是这种的方式效率过于底下,甚至导致不相干的事务都只能串行处理。为了提升性能,需要尽可能提升事务处理的并发度,同时又能满足事务的隔离级别要求。事务并发处理会碰到如下三种场景:
读写冲突 读写冲突顾名思义,对某一行或者某几行进行读取时,存在另外一个事务同时对这一行或者这几行执行写操作。 在数据读时,内存的Key会记录一个latest read timestamp,这是最后一次读操作对应事务的initial timestamp(事务的开始时间),该事务每执行一个读操作,都会使用initial timestamp 与Key值中的latest read timestamp 进行比较,把该Key值latest read timestamp 更新为max(initial timestamp, original latest read timestamp)。 在存在读写冲突时,需要关心如下几点:
写写冲突 写写冲突顾名思义,当前事务A对某一行或者某几行执行写操作时,存在另外一个事务B同时对这一行或者这几行执行写操作。 那么在事务运行的过程中,需要关心的几点有:
写读冲突 写读冲突顾名思义,当前事务A对某一行或者某几行进行写操作时,存在另外一个事务B同时对这一行或者这几行执行读操作。 相对于读写冲突和写写冲突,写读冲突处理起来要简单很多,那么在事务运行的过程中,需要关心的几点有:
理论分析 开篇讲到Serial Snapshot Isolation是在事务提交阶段做冲突检测,而Cockroach是在事务执行阶段做冲突检测。我们还需要从理论上分析上面的冲突处理流程是否符合MVCC的基础规则。 再回顾一下MVCC事务机制: Snapshot Isolation 中描述的write snapshot isolation涉及两个规则:
Similarity to snapshot isolation ,write-snapshot isolation assigns unique start and commit timestamp to transactions and ensures that txni reads the latest version of data with commit timestamp phi < Ts(txni) write snapshot isolation 为每个事务分配一个开始的时间戳,一个事务提交时间戳,保证每一个(读写)事务读到一行版本的提交时间戳要小于事务的开始时间 在上面冲突处理流程中可以看到Cockroach写到Transaction Table里面的事务提交时间并不是事务运行的结束的时间,而是把事务的提交时间提前。当 Ts(txni) == Tc(txni)的时候,没有任何一个事务txnj满足Ts(txni) < Tc(txnj) <Tc(txni),假设一个事务开始时,initial timestamp 与candidate commit timestamp 都是2,如果这个事务正常提交(不发生冲突),假设这个事务结束的绝对时间为4,Cockroach在Transaction Table写入的事务在timestamp = 2的这个时间点提交的。也就是Cockroach里面记录事务提交时间要比事务真实运行时提交的时间要早。这样就可以满足上面的规则要求。 但是什么场景下允许这样做而不影响数据的一致性呢?关键在于数据库运行期间,没有其他事务关心这个事务在什么时间提交。或者说在事务运行的时间区间内,该事务修改的行没有被处在这个时间区间内的snapshot 读到过,如果出现这样的事务,SSI事务要么把自己abort掉,要么把对方的事务abort掉。 简单描述就是:一个SSI事务如果提交成功,那么它的Ts与Tc是相等的(Ts相当于它的initial timestamp ,Tc是它的final commit timestamp)。在Cockroach的SSI的事务是不允许自己的candidate commit time 往后推,如果SSI事务能够提交成功,那么它的candidate commit time 是跟initial commit time相等的,write snapshot isolation规则二中就不可能有一个事务txnj 满足 Ts(txni) < Tc(txnj) <Tc(txni)。也就是说一个cockroach的SSI事务提交的时候,不可能有其它事务修改了SSI事务读取的行
brpc作为一个基础框架,在很多项目中采用,也设计了很多数据结构,这里根据资料总结一下
首先brpc本身的资料就够多了。这里复读一下,总结概念
[toc]
看tag知内容
这些cpp会议录像都是讲 优化/性能的
准备把blog阅读和paper阅读都归一,而不是看一篇翻译一篇,效率太低了
后面写博客按照 paper review,blog review,cppcon review之类的集合形式来写,不一篇一片写了。太水了
rocksdb范围查询性能差主要原因在于排序信息是用到再查的,这里的解决方案就是高效处理这个信息
回想一下bitcask的设计,hashkv,但是重启需要整个加载一遍,很慢,为了避免这个问题引入索引文件hint
这里的remix就是把sst的排序给保存了下来,方便范围查询,但肯定会影响写性能,因为你修改的同时也要维护这个索引文件
我感觉就像个bitcask加强版
而且是内存丢失版,不保证落盘的
fasterkv只是简单的kv 点读点写以及RMW
fishstore使用了faster同样的设计,为了处理json做了subset index
前面讲fasterkv,后面讲fishstore
这个记录是笔记式的,随时都可能变化
线上使用的是离线写在线读的模式,有增量场景,这种用法其实和完美hash构造差不多。唯一区别,能捡个现成的用
每种数据库都有自己的结构,每种数据库之间的导入导出都需要convert
解决方案就是用通用的中间模型来表达,省掉转换的代价,也就是arrow的由来