arrow parquet ORC
11 Mar 2021
|
|
每种数据库都有自己的结构,每种数据库之间的导入导出都需要convert
解决方案就是用通用的中间模型来表达,省掉转换的代价,也就是arrow的由来
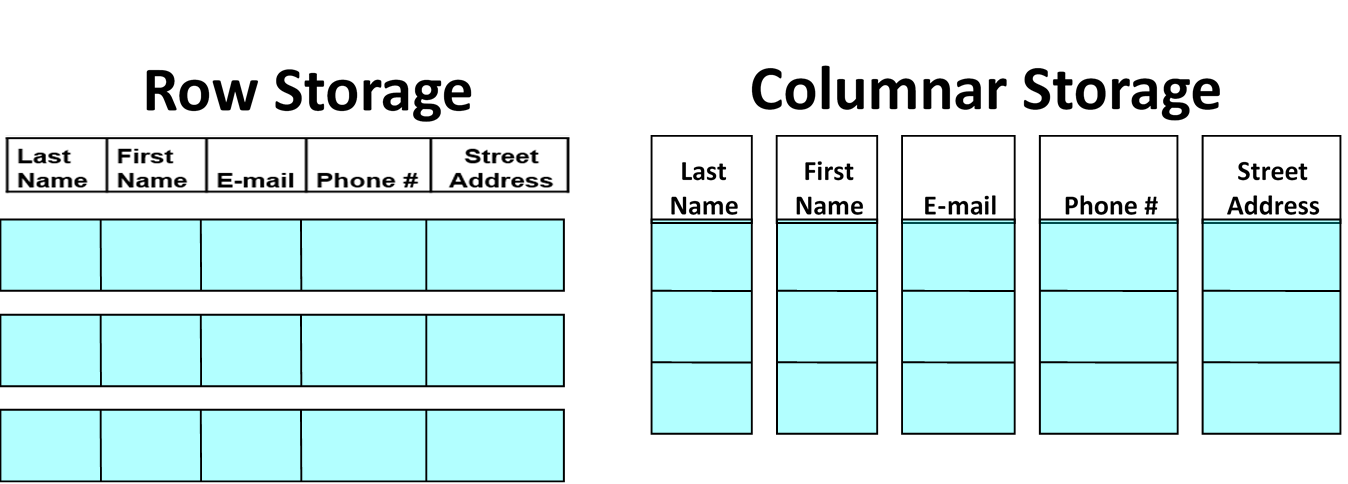
其实背后的实际需求是列存数据库
列存的背景可以看这篇文章,简单概述
- 跳过无关的数据。从行存到列存,就是消除了无关列的扫描;ORC 中通过三层索引信息,能快速跳过无关的数据分片。
- 编码既是压缩,也是索引。Dremel 中用精巧的嵌套编码避免了大量 NULL 的出现;C-Store 对 distinct 值的编码同时也是对 distinct 值的索引;PowerDrill 则将字典编码用到了极致(见下一篇文章)。
- 假设数据不可变。无论 C-Store、Dremel 还是 ORC,它们的编码和压缩方式都完全不考虑数据更新。如果一定要有更新,暂时写到别处、读时合并即可。
- 数据分片。处理大规模数据,既要纵向切分也要横向切分,不必多说。
type FixedColumn struct {
data []byte
length int
nullCount int
nullBitmap []byte // bit 0 is null, 1 is not null
}
type VarColumn struct {
data []byte
offsets []int64
length int
nullCount int
nullBitmap []byte // bit 0 is null, 1 is not null
}
同是列式,Cassandra的格式是类似的https://github.com/facebook/rocksdb/blob/master/utilities/cassandra/format.h
length: 5, nullCount: 1
nullBitmap:
|Byte 0 (null bitmap) | Bytes 1-63 |
|---------------------|-----------------------|
| 00011101 | 0 (padding) |
data:
|Bytes 0-3 | Bytes 4-7 | Bytes 8-11 | Bytes 12-15 | Bytes 16-19 | Bytes 20-63 |
|------------|-------------|-------------|-------------|-------------|-------------|
| 1 | unspecified | 2 | 4 | 8
tidb使用类似的结构
https://zhuanlan.zhihu.com/p/38095421
parquet合入了arrow,ORC和他们差不多,其实适用于批处理,增加吞吐,如果作为内存结构增删查改感觉未必性能优越,主要是整齐通用,方便内部演算。实际落盘还是KV,比如TIDB的chunk的用法
parquet科学计算pandas使用,这里有一个例子 https://dev.l1x.be/posts/2021/03/08/compressing-data-with-parquet/
10g sqlite数据转成400M 非常高效
对于 Apache Arrow 的期望:
- 列式存储:大数据系统几乎都是列式存储的,类似于 Apache Parquet 这样的列式数据存储技术自从诞生起就是大家的期望。
- 内存式:SAP HANA 是第一个利用内存加速分析流程的组件,随着 Apache Spark 的出现,进一步提升了利用内存加速流程的技术可能性落地。
- 复杂数据和动态模式:当我们通过继承和内部数据结构呈现数据的时候,一开始有点麻烦,后来就有了 JSON 和基于文档的数据库。
Arrow 的列式存储有着 O(1) 的随机访问速度,并且可以进行高效的 Cache,同时还允许 SIMD 指令的优化。由于很多大数据系统都是在 JVM 上运行的,Arrow 对于 Python 和 R 的社区来说显得格外重要。
Apache Arrow 是基于 Apache Drill 中的 Value Vector 来实现的,而使用 Value Vector 可以减少运算时重复访问数据带来的成本。
参考
- https://www.infoq.cn/article/1m21n9lzek5qu2jysuue
- https://www.infoq.cn/article/apache-arrow
- ORC 文件存储格式
