[toc]
why
梳理思路,省着忘了
0. trivial
1. 整体架构
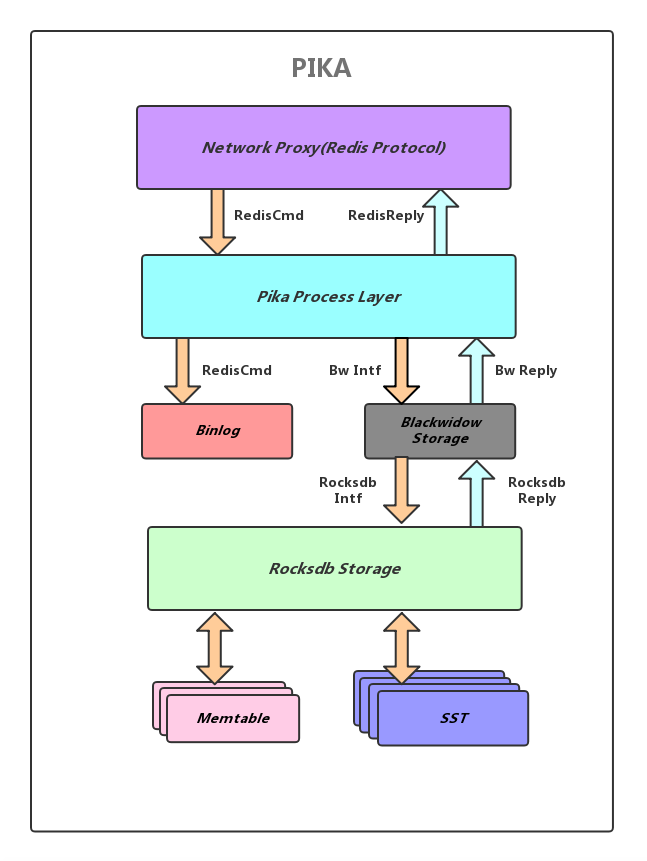
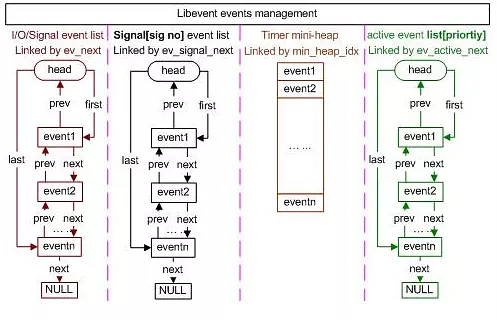
一图胜千言 很多redis over rocksdb的实现都是在编码上有各种异同,比如ssdb ardb之类的,pika怎么做的?上图
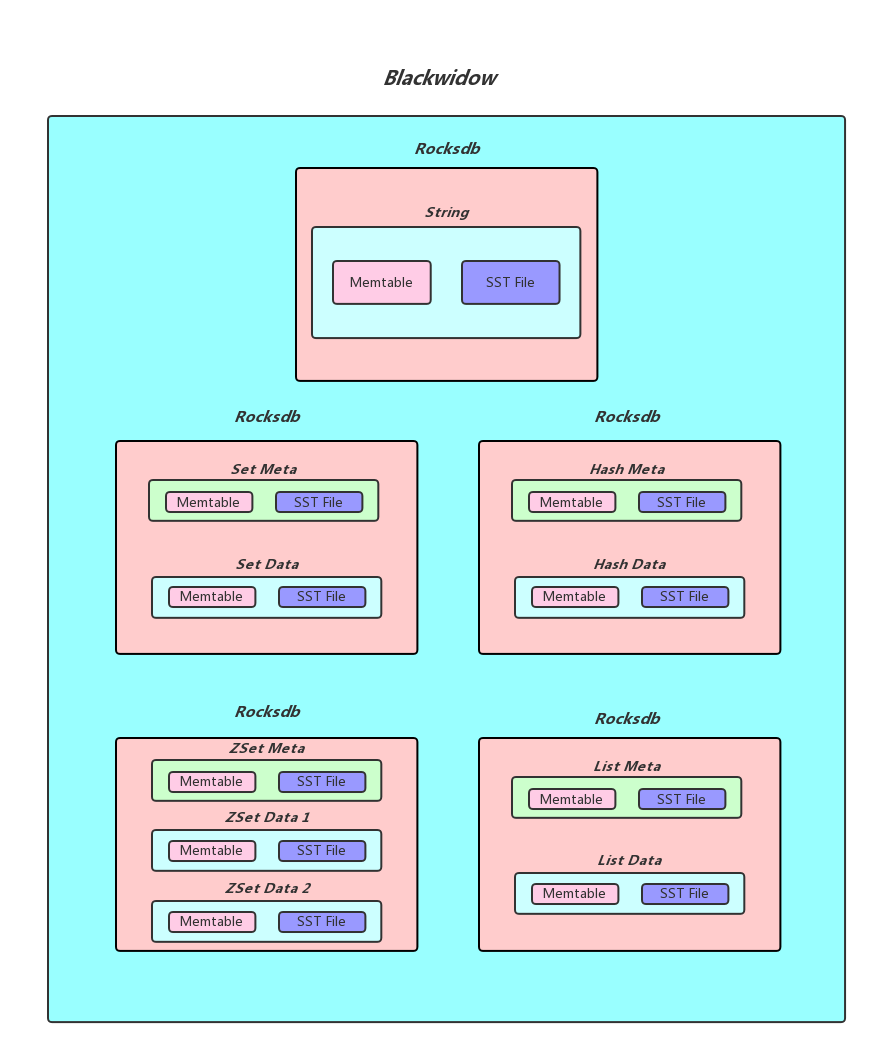
复杂数据结构 set zset hash 是分成元数据和实体数据来做的。(大家都抄linux)
pika编译踩坑
- 运行测试,二进制文件运行几次测试用例就挂了,应该是不支持wait直接崩了
下面是log记录。我个人猜测是运行环境的问题,准备从头编译
bash pikatests.sh wait
ERROR:path : ./tests/tmp/redis.conf.29436.2
-----------Pika server 3.0.5 ----------
-----------Pika config list----------
1 thread-num 1
2 sync-thread-num 6
3 sync-buffer-size 10
4 log-path ./log/
5 loglevel info
6 db-path ./db/
7 write-buffer-size 268435456
8 timeout 60
9 requirepass
10 masterauth
11 userpass
12 userblacklist
13 dump-prefix
14 dump-path ./dump/
15 dump-expire 0
16 pidfile ./pika.pid
17 maxclients 20000
18 target-file-size-base 20971520
19 expire-logs-days 7
20 expire-logs-nums 10
21 root-connection-num 2
22 slowlog-write-errorlog no
23 slowlog-log-slower-than 10000
24 slowlog-max-len 128
25 slave-read-only yes
26 db-sync-path ./dbsync/
27 db-sync-speed -1
28 slave-priority 100
29 server-id 1
30 double-master-ip
31 double-master-port
32 double-master-server-id
33 write-binlog yes
34 binlog-file-size 104857600
35 identify-binlog-type new
36 max-cache-statistic-keys 0
37 small-compaction-threshold 5000
38 compression snappy
39 max-background-flushes 1
40 max-background-compactions 2
41 max-cache-files 5000
42 max-bytes-for-level-multiplier 10
-----------Pika config end----------
WARNING: Logging before InitGoogleLogging() is written to STDERR
W1217 17:22:48.644249 29438 pika.cc:167] your 'limit -n ' of 1024 is not enough for Redis to start. pika have successfully reconfig it to 25000
I1217 17:22:48.644497 29438 pika.cc:184] Server at: ./tests/tmp/redis.conf.29436.2
I1217 17:22:48.644691 29438 pika_server.cc:192] Using Networker Interface: eth0
I1217 17:22:48.644783 29438 pika_server.cc:235] host: 192.168.1.104 port: 0
I1217 17:22:48.644820 29438 pika_server.cc:68] Prepare Blackwidow DB...
I1217 17:22:48.776921 29438 pika_server.cc:73] DB Success
I1217 17:22:48.776942 29438 pika_server.cc:89] Worker queue limit is 20100
I1217 17:22:48.777190 29438 pika_binlog.cc:103] Binlog: Manifest file not exist, we create a new one.
I1217 17:22:48.777328 29438 pika_server.cc:109] double recv info: filenum 0 offset 0
F1217 17:22:48.779913 29438 pika_server.cc:284] Start BinlogReceiver Error: 1: bind port 1000 conflict, Listen on this port to handle the data sent by the Binlog Sender
*** Check failure stack trace: ***
@ 0x83c5aa google::LogMessage::Fail()
@ 0x83e2ff google::LogMessage::SendToLog()
@ 0x83c1f8 google::LogMessage::Flush()
@ 0x83ec2e google::LogMessageFatal::~LogMessageFatal()
@ 0x5f5725 PikaServer::Start()
@ 0x423db4 main
@ 0x7fe733418bb5 __libc_start_main
@ 0x58ac71 (unknown)
[1/1 done]: unit/wait (5 seconds)
The End
Execution time of different units:
5 seconds - unit/wait
\2. 源码编译由于我的服务器限制不能访问外网,自己手动git clone然后导回服务器(这里又有一个坑)(win7没有wsl,只能用服务器搞)
然后需要依赖子模块
git submodule init
git submodule update
重新在windows上更新后传回
分别编译,
子模块编译失败,其中有文件格式不对的问题 手动转dos2unix
然后才发现tortoisegit有个自动添加换行符的选项,默认打勾。所以基本上涉及到的shell文件都得手动dos2unix
我的服务器只有4.8.3,所以编译rocksdb需要c++11 需要修改Makefile(其实是detect脚本没加权限的问题)

编译glog失败
./configure make失败 提示没有什么repo
搜到了类似的问题,https://stackoverflow.com/questions/18839857/deps-po-no-such-file-or-directory-compiler-error
按照提示 (需要安装libtool)
提示
.ibtoolize: AC_CONFIG_MACRO_DIR([m4]) conflicts with ACLOCAL_AMFLAGS=-I m4
结果还是gitwindows加换行符导致的。 That darn “libtoolize: AC_CONFIG_MACRO_DIR([m4]) conflicts with ACLOCAL_AMFLAGS=-I m4” error Is caused by using CRLFs in Makefile.am. “m4" != "m4" and thus the libtoolize script will produce an error. If you're using git, I strongly advise adding a .gitattributes file with the following: *.sh -crlf *.ac -crlf *.am -crlf http://pete.akeo.ie/2010/12/that-darn-libtoolize-acconfigmacrodirm4.html
最终编译过了,运行提示找不到glog 还要手动ldconfig一下
echo "/usr/local/lib" >> /etc/ld.so.conf
ldconfig
还有一种解决方案,export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
总算能运行测试了。
redis 中runtest脚本不能直接用,但是测试用例可以直接拿过来用,support/server.tcl文件改下start_server函数就行(pika已经改过了,直接用那个文件就好了)
测试,类似下面,改改应该就行了
#!/bin/bash
for f in ${PWD}/tests/unit/*;do
filename=${f##*/}
tclsh tests/test_helper.tcl --clients 1 --single unit/${filename%.*}
done
for f in ${PWD}/tests/unit/type/*;do
filename=${f##*/}
tclsh tests/test_helper.tcl --clients 5 --single unit/type/${filename%.*}
#tclsh tests/test_helper.tcl --clients 1 --single unit/type/${filename%.*}
done
附调用图一张。组件太多,确实找不到在哪。

遇到的问题
- valgrind不能attach到daemon进程上
只能停掉daemon从命令行执行
vex amd64->IR: unhandled instruction bytes: 0x62 0xF1 0x7D 0x48 0xEF 0xC0 0x48 0x8D
vex amd64->IR: REX=0 REX.W=0 REX.R=0 REX.X=0 REX.B=0
vex amd64->IR: VEX=0 VEX.L=0 VEX.nVVVV=0x0 ESC=NONE
vex amd64->IR: PFX.66=0 PFX.F2=0 PFX.F3=0
==17407== valgrind: Unrecognised instruction at address 0x815dc7.
==17407== at 0x815DC7: rocksdb::BlockBasedTableFactory::BlockBasedTableFactory(rocksdb::BlockBasedTableOptions const&) (block_based_table_factory.cc:44)
==17407== by 0x7FC64D: rocksdb::ColumnFamilyOptions::ColumnFamilyOptions() (options.cc:99)
==17407== by 0x4762EF: __static_initialization_and_destruction_0(int, int) [clone .constprop.1298] (options_helper.h:387)
==17407== by 0x8E011C: __libc_csu_init (in /home/vdb/pika/output/pika)
==17407== by 0x65F2B44: (below main) (in /usr/lib64/libc-2.17.so)
==17407== Your program just tried to execute an instruction that Valgrind
==17407== did not recognise. There are two possible reasons for this.
==17407== 1. Your program has a bug and erroneously jumped to a non-code
==17407== location. If you are running Memcheck and you just saw a
==17407== warning about a bad jump, it's probably your program's fault.
==17407== 2. The instruction is legitimate but Valgrind doesn't handle it,
==17407== i.e. it's Valgrind's fault. If you think this is the case or
==17407== you are not sure, please let us know and we'll try to fix it.
==17407== Either way, Valgrind will now raise a SIGILL signal which will
==17407== probably kill your program.
==17407==
==17407== Process terminating with default action of signal 4 (SIGILL)
==17407== Illegal opcode at address 0x815DC7
==17407== at 0x815DC7: rocksdb::BlockBasedTableFactory::BlockBasedTableFactory(rocksdb::BlockBasedTableOptions const&) (block_based_table_factory.cc:44)
==17407== by 0x7FC64D: rocksdb::ColumnFamilyOptions::ColumnFamilyOptions() (options.cc:99)
==17407== by 0x4762EF: __static_initialization_and_destruction_0(int, int) [clone .constprop.1298] (options_helper.h:387)
==17407== by 0x8E011C: __libc_csu_init (in /home/vdb/pika/output/pika)
==17407== by 0x65F2B44: (below main) (in /usr/lib64/libc-2.17.so)
==17407==
==17407== Events : Ir
==17407== Collected : 11565385
rocksdb 检测脚本 加上 PORTABLE=1 主要还是-march=native这条导致的
- valgrind执行权限不足?子进程pika 无法修改sockte个数
14:17:17.436130 16158 pika.cc:173] your ‘limit -n ‘ of 1024 is not enough for Redis to start. pika can not reconfig it(Operation not permitted), do it by yourself
ulimit -n 102400
I0527 14:47:45.087769 18132 pika_binlog.cc:87] Binlog: Manifest file not x
exist, we create a new one. x
Could not create logging file: Not a directory x
COULD NOT CREATE A LOGGINGFILE!F0527 14:47:45.087787 18132 pika_binlog.ccx
:92] Binlog: new ./log/log_db0/write2file IO error: ./log/log_db0/write2fx
ile0: Not a directory x
*** Check failure stack trace: *** x
@ 0x7fc9dd5d1b5d google::LogMessage::Fail() x
@ 0x7fc9dd5d37dd google::LogMessage::SendToLog() x
@ 0x7fc9dd5d1773 google::LogMessage::Flush() x
@ 0x7fc9dd5d41fe google::LogMessageFatal::~LogMessageFatal() x
@ 0x6032e6 Binlog::Binlog() x
@ 0x615519 Partition::Partition() x
@ 0x5f5f83 Table::Table() x
@ 0x621525 PikaServer::InitTableStruct() x
@ 0x625d0c PikaServer::Start() x
@ 0x429a54 main x
@ 0x7fc9dbaa9bb5 __libc_start_main x
@ 0x54ea41 (unknown) x
Aborted
测试select命令路径的脚本 需要安装redis-tools
#!/bin/bash
for i in {0..10000}
do
echo select $(expr $i % 8 ) |redis-cli -p 9221
done
spop命令不支持count参数,需要拓展
| zadd命令不支持nx |
xx ch incr 参数,比较复杂 |
pika跑单测
1 #!/bin/bash
2 ./runtest --list-tests |while read line
3 do
4 ./runtest --clients 1 --single $line
5 done
core 目录
cat /proc/sys/kernel/core_pattern
也可以改core格式, 见参考链接
echo "core-%e-%p-%t" > /proc/sys/kernel/core_pattern
这样默认生成在程序所在目录
redis release note
只列举功能相关部分,增强优化点不列出
| redis版本 |
功能点 |
| 2.6 |
Lua脚本支持 |
| 2.6 |
新增PEXIRE、PTTL、PSETEX过期设置命令,key过期时间可以设置为毫秒级 |
| 2.6 |
新增位操作命令:BITCOUNT、BITOP |
| 2.6 |
新增命令:dump、restore,即序列化与反序列化操作 |
| 2.6 |
新增命令:INCRBYFLOAT、HINCRBYFLOAT,用于对值进行浮点数的加减操作 |
| 2.6 |
新增命令:MIGRATE,用于将key原子性地从当前实例传送到目标实例的指定数据库上 |
| 2.6 |
SHUTDOWN命令添加SAVE和NOSAVE两个参数,分别用于指定SHUTDOWN时用不用执行写RDB的操作 |
| 2.6 |
sort命令会拒绝无法转换成数字的数据模型元素进行排序 |
| 2.6 |
不同客户端输出缓冲区分级,比如普通客户端、slave机器、pubsub客户端,可以分别控制对它们的输出缓冲区大小 |
| 2.8 |
引入PSYNC,主从可以增量同步,这样当主从链接短时间中断恢复后,无需做完整的RDB完全同步 |
| 2.8 |
新增命令:SCAN、SSCAN、HSCAN和ZSCAN |
| 2.8 |
crash的时候自动内存检查 |
| 2.8 |
新增键空间通知功能,客户端可以通过订阅/发布机制,接收改动了redis指定数据集的事件 |
| 2.8 |
可通过CONFIGSET设置客户端最大连接数 |
| 2.8 |
新增CONFIGREWRITE命令,可以直接把CONFIGSET的配置修改到redis.conf里 |
| 2.8 |
新增pubsub命令,可查看pub/sub相关状态 |
| 2.8 |
支持引用字符串,如set ‘foo bar’ “hello world\n” |
| 2.8 |
新增redis master-slave集群高可用解决方案(Redis-Sentinel) |
| 2.8 |
当使用SLAVEOF命令时日志会记录下新的主机 |
| 3.0 |
实现了分布式的Redis即Redis Cluster,从而做到了对集群的支持 |
| 3.0 |
大幅优化LRU近似算法的性能 |
| 3.0 |
新增CLIENT PAUSE命令,可以在指定时间内停止处理客户端请求 |
| 3.0 |
新增WAIT命令,可以阻塞当前客户端,直到所有以前的写命令都成功传输并和指定的slaves确认 |
| 3.0 |
AOF重写过程中的”last write”操作降低了AOF child -> parent数据传输的延迟 |
| 3.0 |
实现了对MIGRATE连接缓存的支持,从而大幅提升key迁移的性能 |
| 3.0 |
为MIGRATE命令新增参数:copy和replace,copy不移除源实例上的key,replace替换目标实例上已存在的key |
| 3.2 |
新增对GEO(地理位置)功能的支持 |
| 3.2 |
SPOP命令新增count参数,可控制随机删除元素的个数 |
| 3.2 |
新增HSTRLEN命令,返回hash数据类型的value长度 |
| 3.2 |
提供了一个基于流水线的MIGRATE命令,极大提升了命令执行速度 |
| 4.0 |
加入模块系统,用户可以自己编写代码来扩展和实现redis本身不具备的功能,它与redis内核完全分离,互不干扰 |
| 4.0 |
优化了PSYNC主从复制策略,使之效率更高 |
| 4.0 |
为DEL、FLUSHDB、FLUSHALL命令提供非阻塞选项,可以将这些删除操作放在单独线程中执行,从而尽可能地避免服务器阻塞 |
| 4.0 |
新增SWAPDB命令,可以将同一redis实例指定的两个数据库互换 |
| 4.0 |
新增RDB-AOF持久化格式,开启后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中 RDB格式的内容用于记录已有的数据,而AOF格式的内存则用于记录最近发生了变化的数据 |
| 4.0 |
新增MEMORY内存命令,可以用于查看某个key的内存使用、查看整体内存使用细节、申请释放内存、深入查看内存分配器内部状态等功能 |
| 5.0 |
新的流数据类型(Stream data type) https://redis.io/topics/streams-intro |
| 5.0 |
新的 Redis 模块 API:定时器、集群和字典 API(Timers, Cluster and Dictionary APIs) |
| 5.0 |
RDB 现在可存储 LFU 和 LRU 信息 |
| 5.0 |
新的有序集合(sorted set)命令:ZPOPMIN/MAX 和阻塞变体(blocking variants) |
| 5.0 |
更好的内存统计报告 |
| 5.0 |
许多包含子命令的命令现在都有一个 HELP 子命令 |
| 5.0 |
引入 CLIENT UNBLOCK 和 CLIENT ID |
兼容性对比
| 命令 |
版本 |
复杂度 |
pika |
| string |
|
|
|
| SET |
1.0 |
O1 |
支持 |
| SETNX |
1.0 |
O(1) |
支持 |
| SETEX |
2.0 |
O(1) |
支持 |
| PSETEX |
2.6 |
O(1) |
支持 |
| GET |
1.0 |
O(1) |
支持 |
| GETSET |
1.0 |
O(1) |
支持 |
| STRLEN |
2.2 |
O(1) |
支持 |
| APPEND |
2.0 |
平摊O(1) |
支持 |
| SETRANGE |
2.2 |
如果本身字符串短。平摊O(1),否则为O(len(value)) |
支持 |
| GETRANGE |
2.4 |
O(N)N为返回字符串的长度 |
支持 |
| INCR |
1.0 |
O(1) |
支持 |
| INCRBY |
1.0 |
O(1) |
支持 |
| INCRBYFLOAT |
2.6 |
O(1) |
支持 |
| DECR |
1.0 |
O(1) |
支持 |
| DECRBY |
1.0 |
O(1) |
支持 |
| MSET |
1.0.1 |
O(N) N为键个数 |
支持 |
| MSETNX |
1.0.1 |
O(N) N为键个数 |
支持 |
| MGET |
1.0.0 |
O(N) N为键个数 |
支持 |
| SETBIT |
2.2 |
O(1) |
部分支持 |
| GETBIT |
2.2 |
O(1) |
部分支持 |
| BITCOUNT |
2.6 |
O(N) |
部分支持 |
| BITPOS |
2.8.7 |
O(N) |
支持 |
| BITOP |
2.6 |
O(N) |
部分支持 |
| BITFIELD |
3.2 |
O(1) |
不支持 |
| hash |
|
|
|
| HSET |
2.0 |
O(1) |
支持 |
| HSETNX |
2.0 |
O(1) |
支持 |
| HGET |
2.0 |
O(1) |
支持 |
| HEXISTS |
2.0 |
O(1) |
支持 |
| HDEL |
2.0 |
O(N) N为删除的字段个数 |
支持 |
| HLEN |
2.0 |
O(1) |
支持 |
| HSTRLEN |
3.2 |
O(1) |
支持 |
| HINCRBY |
2.0 |
O(1) |
支持 |
| HINCRBYFLOAT |
2.6 |
O(1)支持 |
支持 |
| HMSET |
2.0 |
O(N) N为filed-value数量 |
支持 |
| HMGET |
2.0 |
O(N) |
支持 |
| HKEYS |
2.0 |
O(N)N为哈希表大小? |
支持 |
| HVALS |
2.0 |
O(N) |
支持 |
| HGETALL |
2.0 |
O(N) |
支持 |
| HSCAN |
2.0 |
O(N)? |
支持 |
| list |
|
|
|
| LPUSH |
1.0 |
O(1) |
支持 |
| LPUSHX |
2.2 |
O(1) |
支持 |
| RPUSH |
1.0 |
O(1) |
支持 |
| RPUSHX |
2.2 |
O(1) |
支持 |
| LPOP |
1.0 |
O(1) |
支持 |
| RPOP |
1.0 |
O(1) |
支持 |
| RPOPLPUSH |
1.2 |
O(1) |
支持 |
| LREM |
1.0 |
O(N) |
支持 |
| LLEN |
1.0 |
O(1) |
支持 |
| LINDEX |
1.0 |
O(N) N为遍历到index经过的数量 |
支持 |
| LINSERT |
2.2 |
O(N) N 为寻找目标值经过的值 |
支持 |
| LSET |
1.0 |
O(N) N为遍历到index处的元素个数 |
支持 |
| LRANGE |
1.0 |
O(S+N) S为start偏移量,N为区间stop-start |
支持 |
| LTRIM |
1.0 |
O(N) N为被移除元素的数量 |
支持 |
| BLPOP |
2.0 |
O(1) |
不支持 |
| BRPOP |
2.0 |
O(1) |
不支持 |
| BRPOPLPUSH |
2.2 |
O(1) |
不支持 |
| set |
|
|
|
| SADD |
1.0 |
O(N) N是元素个数 |
支持 |
| SISMEMBER |
1.0 |
O(1) |
支持 |
| SPOP |
1.0 |
O(1)支持 |
支持 |
| SRANDMEMBER |
1.0 |
O(N) N为返回值的个数 |
支持 行为可能不一致 复杂度ON |
| SREM |
1.0 |
O(N) N为移除的元素个数支持 |
支持 |
| SMOVE |
1.0 |
O(1) |
支持 |
| SCARD |
1.0 |
O(1) |
支持 |
| SMEMBERS |
1.0 |
O(N) N为集合基数 |
支持 |
| SSCAN |
|
|
支持 |
| SINTER |
1.0 |
O(NxM) N是集合最小基数,M是集合个数 |
支持 |
| SINTERSTORE |
1.0 |
O(N*M) |
支持 |
| SUION |
1.0 |
O(N) N是所有给定元素之和 |
支持 |
| SUIONSTORE |
1.0 |
O(N) |
支持 |
| SDIFF |
1.0 |
O(N) |
支持 |
| SDIFFSTORE |
1.0 |
O(N) |
支持 |
| Sorted Set |
|
|
|
| ZADD |
1.2 |
O(M*logN) N 是基数M是添加新成员个数 |
支持 |
| ZSCORE |
1.2 |
O(1) |
支持 |
| ZINCRBY |
1.2 |
O(logN) |
支持 |
| ZCARD |
1.2 |
O(1) |
支持 |
| ZCOUNT |
2.0 |
O(logN) |
支持 |
| ZRANGE |
1.2 |
O(logN+M) M结果集基数 N有序集基数 |
支持 |
| ZREVRANGE |
1.2 |
O(logN+M) M结果集基数 N有序集基数 |
支持 |
| ZRANGEBYSCORE |
1.05 |
O(logN+M) M结果集基数 N有序集基数 |
支持 |
| ZREVRANGEBYSCORE |
1.05 |
O(logN+M) M结果集基数 N有序集基数 |
支持 |
| ZRANK |
2.0 |
O(logN) |
支持 |
| ZREVRANK |
2.0 |
O(logN) |
支持 |
| ZREM |
1.2 |
O(logN*M) N基数M被移除的个数 |
支持 |
| ZREMRANGEBYRANK |
2.0 |
O(logN+M) N基数 M被移除数量 |
支持 |
| ZREMRANGEBYSCORE |
1.2 |
O(logN+M) N基数 M被移除数量 |
支持 |
| ZRANGEBYLEX |
2.8.9 |
O(logN+M) N基数 M返回元素数量 |
支持 |
| ZLEXCOUNT |
2.8.9 |
O(logN) N为元素个数 |
支持 |
| ZREMRANGEBYLEX |
2.8.9 |
O(logN+M) N基数 M被移除数量 |
支持 |
| ZSCAN |
|
|
支持 |
| ZUNIONSTORE |
2.0 |
时间复杂度: O(N)+O(M log(M)), N 为给定有序集基数的总和, M 为结果集的基数。 |
支持 |
| ZINTERSTORE |
2.0 |
O(NK)+O(Mlog(M)), N 为给定 key 中基数最小的有序集, K 为给定有序集的数量, M 为结果集的基数。 |
支持 |
| ZPOPMAX |
5.0 |
O(log(N)*M) M最大值个数 |
不支持 |
| ZPOPMIN |
5.0 |
O(log(N)*M) |
不支持 |
| BZPOPMAX |
5.0 |
O(log(N)) |
不支持 |
| BZPOPMIN |
5.0 |
O(log(N)) |
不支持 |
| HyperLogLog |
|
|
|
| PFADD |
2.8.9 |
O(1) |
支持 |
| PFCOUNT |
2.8.9 |
O(1),多个keyO(N) |
支持 |
| PFMERGE |
2.8.9 |
O(N) |
支持 |
| GEO |
|
|
|
| GEOADD |
3.2 |
O(logN) |
支持 |
| GEOPOS |
3.2 |
O(logN) |
支持 |
| GEODIST |
3.2 |
O(logN) |
支持 |
| GEORADIUS |
3.2 |
O(N+logM)N元素个数M被返回的个数 |
支持 |
| GEORADIUSBYMEMBER |
3.2 |
O(N+logM) |
支持 |
| GEOHASH |
3.2 |
O(logN) |
支持 |
| Stream |
|
|
|
| XADD |
5.0 |
O(1) |
不支持 |
| XACK |
5.0 |
O(1) |
不支持 |
| XCLAIM |
5.0 |
O(log N) |
不支持 |
| XDEL |
5.0 |
O(1) |
不支持 |
| XGROUP |
5.0 |
O(1) |
不支持 |
| XINFO |
5.0 |
O(N) |
不支持 |
| XLEN |
5.0 |
O(1) |
不支持 |
| XPENDING |
5.0 |
O(N) 可以退化为O(1) |
不支持 |
| XRANGE |
5.0 |
O(N) |
不支持 |
| XREAD |
5.0 |
O(N) 可以退化为O(1) |
不支持 |
| XREADGROUP |
5.0 |
O(M) 可以退化为O(1) |
不支持 |
| XREVRANGE |
5.0 |
O(N) 可以退化为O(1) |
不支持 |
| XTRIM |
5.0 |
O(N) |
不支持 |
| Keys |
|
|
|
| EXISTS |
1.0 |
O(1) |
支持 |
| TYPE |
1.0 |
O(1) |
支持 行为不一致但是pika允许重名,有类型输出顺序 |
| RENAME |
1.0 |
O(1) |
不支持 |
| RENAMENX |
1.0 |
O(1) |
不支持 |
| MOVE |
1.0 |
O(1) |
不支持 |
| DEL |
1.0 |
O(N) N为key个数 |
支持 |
| RANDOMKEY |
1.0 |
O(1) |
不支持 |
| DBSIZE |
1.0 |
O(1) |
支持 行为不一致 |
| EXPIRE |
1.0 |
O(1) |
支持 |
| EXPIREAT |
1.2 |
O(1) |
支持 |
| TTL |
1.0 |
O(1) |
支持 |
| PERSIST |
2.2 |
O(1) |
支持 |
| PEXPIRE |
2.6 |
O(1) |
支持 行为不一致,单位秒 |
| PEXPIREAT |
2.6 |
O(1) |
支持 行为不一致,单位秒 |
| PTTL |
2.6 |
O(1) |
支持 |
| MULTI |
1.2 |
O(1) |
不支持 |
| EXEC |
1.2 |
事务块内执行的命令复杂度和 |
不支持 |
| DISCARD |
2.2 |
O(1) |
不支持 |
| WATCH |
2.2 |
O(1) |
不支持 |
| UNWATCH |
2.2 |
O(1) |
不支持 |
| EVAL |
2.6 |
O(1) 找到脚本。其余复杂度取决于脚本本身 |
不支持 |
| EVALSHA |
2.6 |
根据脚本的复杂度而定 |
不支持 |
| SCRIPT LOAD |
2.6 |
O(N) N为脚本长度 |
不支持 |
| SCRIPT EXISTS |
2.6 |
O(N) N为判断的sha个数 |
不支持 |
| SCRIPT FLUSH |
2.6 |
O(N) N为缓存中脚本个数 |
不支持 |
| SCRIPT KILL |
2.6 |
O(1) |
不支持 |
| SAVE |
1.0 |
O(N) N为key个数 |
不支持 |
| BGSAVE |
1.0 |
O(N) |
支持 行为不一致 |
| BGREWRITEAOF |
1.0 |
O(N) N为追加到AOF文件中的数据数量 |
不支持 |
| LASTSAVE |
1.0 |
O(1) |
不支持 |
| Pub/Sub |
|
|
|
| PUBLISH |
2.0 |
O(M+N) channel订阅者数量+模式订阅客户端数量 |
支持 |
| SUBSCRIBE |
2.0 |
O(N) N是channel个数 |
支持 |
| PSUBSCRIBE |
2.0 |
O(N) N是模式的个数 |
支持 |
| UNSUBSCRIBE |
2.0 |
O(N) N是channel个数 |
支持 |
| PUNSUBSCRIBE |
2.0 |
O(N) N是channel个数 |
支持 |
PUBSUB CHANNELS
PUBSUB NUMSUB
PUBSUB NUMPAT |
2.8 |
O(N) N是频道个数 |
支持 |
| 管理命令 |
|
|
|
| SLAVEOF |
1.0 |
O(1) |
支持 |
| ROLE |
2.8.12 |
O(1) |
不支持 |
| AUTH |
1.0 |
O(1) |
支持 |
| QUIT |
1.0 |
O(1) |
支持 |
| INFO |
1.0 |
O(1) |
支持 行为不一致 |
| SHUTDOWN |
1.0 |
O(1) |
支持 |
| TIME |
2.6 |
O(1) |
支持 |
| CLIENT GETNAME CLIENT KILL CLIENT LIST SETNAME PAUSE REPLY ID |
2.6.9
2.4 |
O(1)
O(N
O(N))
O(1) |
部分支持 |
| CONFIG SET CONFIG GET CONFIG RESETSTAT CONFIG REWRITE |
2.0…2.8 |
O(1)O(N)O(1)O(N) |
部分支持 |
| PING |
1.0 |
O(1) |
支持 |
| ECHO |
1.0 |
O(1) |
支持 |
| OBJECT |
2.2.3 |
O(1) |
不支持 |
| SLOWLOG |
2.2.12 |
O(1) |
支持 |
| MONITOR |
1.0 |
O(N) |
支持 |
DEBUG OBJECT
DEBUG SEGFAULT |
1.0 |
O(1) |
不支持 |
| MIGRATE |
2.6 |
O(N) |
不支持 |
| DUMP |
2.6 |
O(1)查找O(N*size)序列化 |
不支持 |
| RESTORE |
2.6 |
O(1)查找O(N*size)反序列化,有序集合还要再乘logN,插入排序的代价 |
不支持 |
| SYNC |
1.0 |
O(N) |
支持,行为不一致 |
| PSYNC |
2.8 |
NA |
支持 行为不一致 |
| SORT |
|
|
不支持 |
| SELECT |
1.0 |
|
支持 实现了一部分 |
ref