链表以及TAILQ
10 Feb 2019
|
|
#链表以及TAILQ
最近重新看c语言的东西,对数据结构还是不熟悉
从链表说起,一个基本的链表,就是由一个个node组成
typedef struct node{
node *next;
node *prev;
void* data;
}node;
而操作链表表头,引用整个链表,就有很多方法
比如,表头就是node,
typedef struct node linklist;
相关的操作函数比如构造函数就都以node做入参
linklist* createList();
void listAdd(linklist* l, node* v);
虽然写法不同但实际上是同一个类型,这种链表的缺点在于,比如合并两个链表,或者对整个链表排序都是leetcode上的题目
对于头结点,同时也是提领引用整个链表的入口,操作会很麻烦,这时候,就需要一个dummyhead,作为head的前节点。那么如何避免这个问题呢?
对linklist结构进行改造,通常就是封一层,比如
typedef struct linklist {
node *head;
...其他函数指针或者记录信息的字段
}linklist;
这基本上就是c++list封装的办法,也是c中常见的封装方法。就是内存分配需要两次比较麻烦,c++为了避免手动malloc,加上了构造析构的语义。(我好像在Bjarne Stroustrup 那本自传书籍里看到过)
然后说到tailq
typedef struct linklist {
node *head;
node *tail;
} linklist;
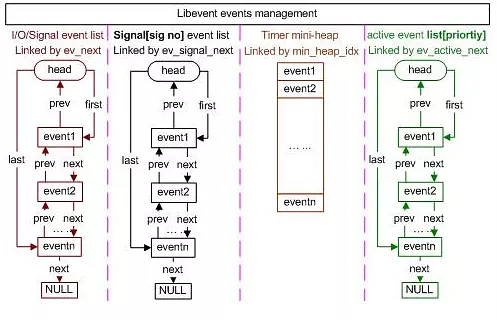
就是这样了。增加一个记录结尾的字段。这个结构在libevent redis中都有(redis基本上把libevent组件抄了一遍,抽出来组装的),最早追述应该是内核中的TAILQ吧。整体就比原来的双端列表多了一个指针的开销,说是队列,实际上双端队列本身也可以实现队列,就是访问最后一个节点需要间接的操作一下,而这可能缓存不友好?不然为啥会有这么个数据结构。
数据结构还是不直观,上个图来说明一下,图用的libevent