[toc]
数据结构
set
- 实现 intset / hashtable(dict)实际上是一样的,编码不同
| 命令 |
intset 编码的实现方法 |
hashtable 编码的实现方法 |
| SADD |
调用 intsetAdd 函数, 将所有新元素添加到整数集合里面。 |
调用 dictAdd , 以新元素为键, NULL 为值, 将键值对添加到字典里面。 |
| SCARD |
调用 intsetLen 函数, 返回整数集合所包含的元素数量, 这个数量就是集合对象所包含的元素数量。 |
调用 dictSize 函数, 返回字典所包含的键值对数量, 这个数量就是集合对象所包含的元素数量。 |
| SISMEMBER |
调用 intsetFind 函数, 在整数集合中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 |
调用 dictFind 函数, 在字典的键中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 |
| SMEMBERS |
遍历整个整数集合, 使用 intsetGet 函数返回集合元素。 |
遍历整个字典, 使用 dictGetKey 函数返回字典的键作为集合元素。 |
| SRANDMEMBER |
调用 intsetRandom 函数, 从整数集合中随机返回一个元素。 |
调用 dictGetRandomKey 函数, 从字典中随机返回一个字典键。 |
| SPOP |
调用 intsetRandom 函数, 从整数集合中随机取出一个元素, 在将这个随机元素返回给客户端之后, 调用 intsetRemove 函数, 将随机元素从整数集合中删除掉。 |
调用 dictGetRandomKey 函数, 从字典中随机取出一个字典键, 在将这个随机字典键的值返回给客户端之后, 调用 dictDelete 函数, 从字典中删除随机字典键所对应的键值对。 |
| SREM |
调用 intsetRemove 函数, 从整数集合中删除所有给定的元素。 |
调用 dictDelete 函数, 从字典中删除所有键为给定元素的键值对。 |
zset
skiplist

| 命令 |
ziplist 编码的实现方法 |
zset 编码的实现方法 |
| ZADD |
调用 ziplistInsert 函数, 将成员和分值作为两个节点分别插入到压缩列表。 |
先调用 zslInsert 函数, 将新元素添加到跳跃表, 然后调用 dictAdd 函数, 将新元素关联到字典。 |
| ZCARD |
调用 ziplistLen 函数, 获得压缩列表包含节点的数量, 将这个数量除以 2 得出集合元素的数量。 |
访问跳跃表数据结构的 length 属性, 直接返回集合元素的数量。 |
| ZCOUNT |
遍历压缩列表, 统计分值在给定范围内的节点的数量。 |
遍历跳跃表, 统计分值在给定范围内的节点的数量。 |
| ZRANGE |
从表头向表尾遍历压缩列表, 返回给定索引范围内的所有元素。 |
从表头向表尾遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZREVRANGE |
从表尾向表头遍历压缩列表, 返回给定索引范围内的所有元素。 |
从表尾向表头遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZRANK |
从表头向表尾遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
从表头向表尾遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREVRANK |
从表尾向表头遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
从表尾向表头遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREM |
遍历压缩列表, 删除所有包含给定成员的节点, 以及被删除成员节点旁边的分值节点。 |
遍历跳跃表, 删除所有包含了给定成员的跳跃表节点。 并在字典中解除被删除元素的成员和分值的关联。 |
| ZSCORE |
遍历压缩列表, 查找包含了给定成员的节点, 然后取出成员节点旁边的分值节点保存的元素分值。 |
直接从字典中取出给定成员的分值。 |
list
- 内部编码 quicklist,代替linkedlist,两者区别?
-
编码的区别,api完全一致
- 这是3.0版本,新版本就是把api换成quicklist-api,接口完全一致,原来的编码方案废除
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
| 命令 |
ziplist 编码的实现方法 |
linkedlist 编码的实现方法 |
| LPUSH |
调用 ziplistPush 函数, 将新元素推入到压缩列表的表头。 |
调用 listAddNodeHead 函数, 将新元素推入到双端链表的表头。 |
| RPUSH |
调用 ziplistPush 函数, 将新元素推入到压缩列表的表尾。 |
调用 listAddNodeTail 函数, 将新元素推入到双端链表的表尾。 |
| LPOP |
调用 ziplistIndex 函数定位压缩列表的表头节点, 在向用户返回节点所保存的元素之后, 调用 ziplistDelete 函数删除表头节点。 |
调用 listFirst 函数定位双端链表的表头节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表头节点。 |
| RPOP |
调用 ziplistIndex 函数定位压缩列表的表尾节点, 在向用户返回节点所保存的元素之后, 调用 ziplistDelete 函数删除表尾节点。 |
调用 listLast 函数定位双端链表的表尾节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表尾节点。 |
| LINDEX |
调用 ziplistIndex 函数定位压缩列表中的指定节点, 然后返回节点所保存的元素。 |
调用 listIndex 函数定位双端链表中的指定节点, 然后返回节点所保存的元素。 |
| LLEN |
调用 ziplistLen 函数返回压缩列表的长度。 |
调用 listLength 函数返回双端链表的长度。 |
| LINSERT |
插入新节点到压缩列表的表头或者表尾时, 使用 ziplistPush 函数; 插入新节点到压缩列表的其他位置时, 使用 ziplistInsert 函数。 |
调用 listInsertNode 函数, 将新节点插入到双端链表的指定位置。 |
| LREM |
遍历压缩列表节点, 并调用 ziplistDelete 函数删除包含了给定元素的节点。 |
遍历双端链表节点, 并调用 listDelNode 函数删除包含了给定元素的节点。 |
| LTRIM |
调用 ziplistDeleteRange 函数, 删除压缩列表中所有不在指定索引范围内的节点。 |
遍历双端链表节点, 并调用 listDelNode 函数删除链表中所有不在指定索引范围内的节点。 |
| LSET |
调用 ziplistDelete 函数, 先删除压缩列表指定索引上的现有节点, 然后调用 ziplistInsert 函数, 将一个包含给定元素的新节点插入到相同索引上面。 |
调用 listIndex 函数, 定位到双端链表指定索引上的节点, 然后通过赋值操作更新节点的值。 |
string
- kv 存在hashtable(dict), 有不同的编码方式
| 命令 |
int 编码的实现方法 |
embstr 编码的实现方法 |
raw 编码的实现方法 |
| SET |
使用 int 编码保存值。 |
使用 embstr 编码保存值。 |
使用 raw 编码保存值。 |
| GET |
拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后向客户端返回这个字符串值。 |
直接向客户端返回字符串值。 |
直接向客户端返回字符串值。 |
| APPEND |
将对象转换成 raw 编码, 然后按 raw编码的方式执行此操作。 |
将对象转换成 raw 编码, 然后按 raw编码的方式执行此操作。 |
调用 sdscatlen 函数, 将给定字符串追加到现有字符串的末尾。 |
| INCRBYFLOAT |
取出整数值并将其转换成 longdouble 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 |
取出字符串值并尝试将其转换成long double 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 |
取出字符串值并尝试将其转换成 longdouble 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 |
| INCRBY |
对整数值进行加法计算, 得出的计算结果会作为整数被保存起来。 |
embstr 编码不能执行此命令, 向客户端返回一个错误。 |
raw 编码不能执行此命令, 向客户端返回一个错误。 |
| DECRBY |
对整数值进行减法计算, 得出的计算结果会作为整数被保存起来。 |
embstr 编码不能执行此命令, 向客户端返回一个错误。 |
raw 编码不能执行此命令, 向客户端返回一个错误。 |
| STRLEN |
拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 计算并返回这个字符串值的长度。 |
调用 sdslen 函数, 返回字符串的长度。 |
调用 sdslen 函数, 返回字符串的长度。 |
| SETRANGE |
将对象转换成 raw 编码, 然后按 raw编码的方式执行此命令。 |
将对象转换成 raw 编码, 然后按 raw编码的方式执行此命令。 |
将字符串特定索引上的值设置为给定的字符。 |
| GETRANGE |
拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后取出并返回字符串指定索引上的字符。 |
直接取出并返回字符串指定索引上的字符。 |
直接取出并返回字符串指定索引上的字符。 |
tzset
time zone set的意思。初始化全局的时间记录
API文档
如果前面有setenv设置了timezone setenv("TZ", "GMT-8", 1);,这里就会更新。
主要更新
| 全局变量 |
说明 |
缺省值 |
| __daylight |
如果在TZ设置中指定夏令时时区 |
1则为非0值;否则为0 |
| __timezone |
UTC和本地时间之间的时差,单位为秒 |
28800(28800秒等于8小时) |
| __tzname[0] |
TZ环境变量的时区名称的字符串值 |
如果TZ未设置则为空 PST |
| __tzname[1] |
夏令时时区的字符串值; |
如果TZ环境变量中忽略夏令时时区则为空PDT在上表中daylight和tzname数组的缺省值对应于”PST8PDT |
在glibc中代码 time/tzset.c
void
__tzset (void)
{
__libc_lock_lock (tzset_lock);
tzset_internal (1);
if (!__use_tzfile)// 注意这里没有设置过TZ就不会进来。
{
/* Set `tzname'. */
__tzname[0] = (char *) tz_rules[0].name;
__tzname[1] = (char *) tz_rules[1].name;
}
__libc_lock_unlock (tzset_lock);
}
实现在tzset_internal中
static void
tzset_internal (int always)
{
static int is_initialized;
const char *tz;
if (is_initialized && !always)//tzset只会执行一次,初始化过就不会再执行
return;
is_initialized = 1;
/* Examine the TZ environment variable. */
tz = getenv ("TZ");
if (tz && *tz == '\0')
/* User specified the empty string; use UTC explicitly. */
tz = "Universal";
// 处理tz 字符串,过滤掉:...
// 检查tz字符串是不是和上次相同,相同就直接返回...
// 新的tz是NULL 就设定成默认的TZDEFAULT "/etc/localtime"...
//保存到old_tz...
// 去读tzfile ,获取daylight和timezone 这里十分繁琐,也有几处好玩的
// 1. 打开文件校验是硬编码的,We must not allow to read an arbitrary file in a `setuid` program
// 2. FD_CLOSEXEC
/* Note the file is opened with cancellation in the I/O functions
disabled and if available FD_CLOEXEC set. */
//f = fopen (file, "rce"); 具体解释看api文档
//这个mode参数是glibc扩展https://www.gnu.org/software/libc/manual/html_node/Opening-Streams.html
__tzfile_read (tz, 0, NULL);
//后续是没读到文件的默认复制动作...
}
setlocale
getRandomHexChars
getRandomHexChars -> getRandomBytes
生成随机数直接用
FILE *fp = fopen("/dev/urandom","r");
if (fp == NULL || fread(seed,sizeof(seed),1,fp) != 1){
/* Revert to a weaker seed, and in this case reseed again
* at every call.*/
for (unsigned int j = 0; j < sizeof(seed); j++) {
struct timeval tv;
gettimeofday(&tv,NULL);
pid_t pid = getpid();
seed[j] = tv.tv_sec ^ tv.tv_usec ^ pid ^ (long)fp;
}
}
保证安全,如果失败就先用时间戳和pid生成一个,但是还是不安全,还是会用fopen重新生成
有个局部静态counter ,每次hash都不一样
dictType
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
基本上看字段名字就明白啥意思了。就是指针。实现多态用的。
redis所有对外呈现的数据类型,都是dict对象来保存。这个dictType就是用来实例化各个类型对象,具体的类型在通过这个类型对象来初始化。举例,redisdb有个expire,这个dict是用来存有设定过期时间的key,
expire= dictCreate(&expireDictType,NULL);
这样就绑定了类型,内部构造析构都用同一个函数指针就行了。
要让dict发挥多态的效果,就要增加一个类型字段,也就是dictType,通过绑定指针来实现,这就相当于元数据。或者说c++中的构造语义,编译器帮你搞or你自己手动搞,手动搞就要自己设计字段搞定
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
说到这,不如考虑一下hashtable的实现
_redisPanic
void _serverPanic(const char *file, int line, const char *msg, ...) {
...log...
#ifdef HAVE_BACKTRACE
serverLog(LL_WARNING,"(forcing SIGSEGV in order to print the stack trace)");
#endif
serverLog(LL_WARNING,"------------------------------------------------");
*((char*)-1) = 'x';
}
指针访问-1 故意段错误,这里也有讨论
overcommit_memory
int linuxOvercommitMemoryValue(void) {
FILE *fp = fopen("/proc/sys/vm/overcommit_memory","r");
char buf[64];
if (!fp) return -1;
if (fgets(buf,64,fp) == NULL) {
fclose(fp);
return -1;
}
fclose(fp);
return atoi(buf);
}
关于这个参数,见http://linuxperf.com/?p=102
如果/proc/sys/vm/overcommit_memory被设置为0,并且配置了rdb重新功能,如果内存不足,则frok的时候会失败,如果在往redis中塞数据, 会失败,打印 MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk 如果/proc/sys/vm/overcommit_memory被设置为1,则不管内存够不够都会fork失败,这样会引发OOM,最终redis实例会被杀掉。
anetNonBlock(char *err, int fd )
if ((flags = fcntl(fd, F_GETFL)) == -1)
if (fcntl(fd, F_SETFL, flags | O_NONBLOCK) == -1)
就是这个
::fcntl(sock, F_SETFL, O_NONBLOCK | O_RDWR);
ustime
/* Return the UNIX time in microseconds */
long long ustime(void) {
struct timeval tv;
long long ust;
gettimeofday(&tv, NULL);
ust = ((long long)tv.tv_sec)*1000000;
ust += tv.tv_usec;
return ust;
}
/* Return the UNIX time in milliseconds */
mstime_t mstime(void) {
return ustime()/1000;
}
写了个c++里类似的
#include <chrono>
auto [] (){ return std::chrono::duration_cast<std::chrono::microseconds>(
std::chrono::system_clock::now().time_since_epoch()).count();
};
redisObject
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
一个对象就24字节了。注意type和encoding,就是redis数据结构和实际内部编码,构造也是先type对象->encoding对象初始化,析构也是判断type,判断encoding,然后删encoding对象删type对象。c++就是把这个流程隐藏了。
client
这个结构就比较复杂了。思考:阻塞命令是怎么阻塞的,为什么影响不到服务端 ->转移到客户端头上了。
阻塞的pop命令,每个客户端都会存个字典,blocking_keys 记录阻塞的key- >客户端链表
还有很多命令的细节放到命令里面讲比较合适。
client还有很多数据结构 看上去很轻巧,复杂的很。
异步事件框架
ae.c,networking这几个文件把epoll 和select kqueue封了一起。用法没差别。epoll用的是LT模式。
- 从客户端读到大数据怎么处理 ->收到事件触发,注册在creatClient -> readQueryFromClient中 如果读出错,EAGAIN就结束,下次EPOLLIN继续处理
- 写大数据到缓冲写不完怎么处理 -> 事件注册在addReply -> prepareClientToWrite sendReplyToClient 中, 循环写缓冲区,如果写出错 EAGAIN就结束,下次EPOLLOUT继续处理,正式结束后删掉写事件(or异常,踢掉客户端流程中会删所有事件)
仔细顺了一遍ET,LT,感觉这个用法有点像ET,没有修改事件, 仔细发现在add/delevent里。。
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}
static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int delmask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
int mask = eventLoop->events[fd].mask & (~delmask);
ee.events = 0;
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (mask != AE_NONE) {
epoll_ctl(state->epfd,EPOLL_CTL_MOD,fd,&ee);
} else {
/* Note, Kernel < 2.6.9 requires a non null event pointer even for
* EPOLL_CTL_DEL. */
epoll_ctl(state->epfd,EPOLL_CTL_DEL,fd,&ee);
}
}
操作客户端的fd
epoll LT ET 主要区别在于LT针对EPOLLOUT事件的处理,
首先EPOLLOUT, 缓冲区可写 调用异步写 → 写满了,EAGAIN→继续等EPOLLOUT事件,这时需要在addevent中修改,加上(MOD)EPOLLOUT事件(可写)
如果没写满,结束了,修改fd,去掉EPOLLOUT事件 ,这时在delevent中删掉(OR 屏蔽掉,MOD),不然这个EPOLLOUT事件会一直触发,就得加屏蔽措施
在比如写一个echo server,或者长连接传文件 ,针对EPOLLOUT事件,写不完,就得手动epoll_ctl MOD一下,暂时屏蔽掉EPOLLOUT事件,然后如果又有了EPOLLOUT事件需要添加就在家上。针对fd得改来改去。如果是ET就没有这么麻烦设定好就行了,要么使劲读到缓冲区读完, or使劲写到缓冲区写满,事件处理完毕,等下一次事件就行。
ET LT是电子信息 信号处理的概念,触发是电平(一直触发)还是毛刺(触发一次),如果用ET,当前框架会不会丢消息?
看了一天epoll 脑袋快炸了
注意新的版本,回复事件全部放在beforeSleep中注册了,上面的分析是3.0版本。
clientsCron
定时任务,处理客户端相关
freememIfNeeded
| 策略 |
说明 |
| volatile-lru |
从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰 |
| volatile-ttl |
从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 |
| volatile-random |
从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰 |
| allkeys-lru |
从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰 |
| allkeys-random |
从数据集(server.db[i].dict)中任意选择数据淘汰 |
| no-enviction(驱逐) |
禁止驱逐数据 |
server.maxmemory这个字段用来判断,这个字段有没有推荐设定值?
ProcessCommand
前期处理,各种条件限制,提前返回。标记上下文涉及到的flag,处理正常会调用call
call
所有的命令都走它,通过它来执行具体的命令。processCommand ....-> call -> c->cmd->proc(c)
call针对不同的客户端连接,处理不同的flag
命令表
把redis源码注释抄过来了
| 标识 |
意义 |
| w |
write command (may modify the key space). |
| r |
read command (will never modify the key space). |
| m |
may increase memory usage once called. Don’t allow if out of memory. |
| a |
admin command, like SAVE or SHUTDOWN. |
| p |
Pub/Sub related command. |
| f |
force replication of this command, regardless of server.dirty. |
| s |
command not allowed in scripts. |
| R |
R: random command. SPOP |
| l |
Allow command while loading the database. |
| t |
Allow command while a slave has stale data but is not allowed to server this data. Normally no command is accepted in this condition but just a few. |
| S |
Sort command output array if called from script, so that the output is deterministic. |
| M |
Do not automatically propagate the command on MONITOR. |
| k |
Perform an implicit ASKING for this command, so the command will be accepted in cluster mode if the slot is marked as ‘importing’. |
| F |
Fast command: O(1) or O(log(N)) command that should never delay its execution as long as the kernel scheduler is giving us time. Note that commands that may trigger a DEL as a side effect (like SET) are not fast commands. |
initServerConfig
初始化server参数
有几个有意思的点:
-
cachedtime 保存一份时间,优化,因为很多对象用这个,就存一份,比直接调用time要快
-
server.tcp_backlog设置成了521.
-
默认的客户端连接空闲时间是0,无限
-
tcpkeepalive设置成了300
…参数太多
-
server.commands 用hashtable存了起来,在一开始已经用数组存好了。
- 优化点,经常使用的命令单独又存了一遍,也有可能后续读配置文件被改。 /* Fast pointers to often looked up command */
-
检查backlog FILE *fp = fopen(“/proc/sys/net/core/somaxconn”,”r”);
-
daemonize 不说了,很常见的操作,fork +exit父进程退出,setsid 改权限,重定向标准fd,打开垃圾桶open(“/dev/null”, O_RDWR)
- 如果是守护进程得建立个pidfile,这个目录写死,在var/run/redis.pid
-
initServer 忽略SIGHUP SIGPIPE,SIGPIPE比较常见
- catch TERM,INT,kill
- segment fault 信号,会直接死掉,OR,打印堆栈和寄存器,在sigsegvhandler中,这个实现值得一看了解怎么获取堆栈
-
下面就是listen和处理socket ipc了。
-
然后是各种初始化,LRU初始化
adjustOpenFilesLimit()
调整打开文件大小,如果小,就设置成1024
serverCron
一个定时任务,每秒执行server.hz次
里面有run_with_period宏,相当于除,降低次数
clientsCron
- 遍历client链表删除超时的客户端
- 大于BIG_ARG (宏,32k)以及querybuf_peak(远大于,代码写的是二倍)
- 大于1k且不活跃 idletime>2
- 遍历client链表缩小查询缓冲区大小
- 如果缓冲越来越大客户端消费不过来redis就oom了
freeClient(redisClient *c)
- 判断是不是主备要求断开,这里会有同步问题
- querybuf
- blockey watchkey pubsubkey
- delete event, close event fd
- reply buf
- 从client链表删掉,从unblocked_clients 链表删掉
- 再次清理主备
- 释放字段内存,释放自己
整体交互流程

beforeSleep
- 执行一次快速的主动过期检查,检查是否有过期的key
- 当有客户端阻塞时,向所有从库发送ACK请求
- unblock 在同步复制时候被阻塞的客户端
- 尝试执行之前被阻塞客户端的命令
- 将AOF缓冲区的内容写入到AOF文件中
- 如果是集群,将会根据需要执行故障迁移、更新节点状态、保存node.conf 配置文件
Client发起socket连接

server接收socket连接

- 服务器初始化建立socket监听
- 服务器初始化创建相关连接应答处理器,通过epoll_ctl注册事件
- 客户端初始化创建socket connect 请求
- 服务器接受到请求,用epoll_wait方法取出事件
- 服务器执行事件中的方法(acceptTcpHandler/acceptUnixHandler)并接受socket连接
至此客户端和服务器端的socket连接已经建立,但是此时服务器端还继续做了2件事:
- 采用createClient方法在服务器端为客户端创建一个client,因为I/O复用所以需要为每个客户端维持一个状态。这里的client也在内存中分配了一块区域,用于保存它的一些信息,如套接字描述符、默认数据库、查询缓冲区、命令参数、认证状态、回复缓冲区等。这里提醒一下DBA同学关于client-output-buffer-limit设置,设置不恰当将会引起客户端中断。
- 采用aeCreateFileEvent方法在服务器端创建一个文件读事件并且绑定readQueryFromClient方法。可以从图中得知,aeCreateFileEvent 调用aeApiAddEvent方法最终通过epoll_ctl 方法进行注册事件。
server接收写入

服务器端依然在进行事件循环,在客户端发来内容的时候触发,对应的文件读取事件。这就是之前创建socket连接的时候建立的事件,该事件绑定的方法是readQueryFromClient 。
-
在readQueryFromClient方法中从服务器端套接字描述符中读取客户端的内容到服务器端初始化client的查询缓冲中,主要方法如下:
-
交给processInputBuffer处理,processInputBuffer 主要包含两个方法,processInlineBuffer和processCommand。processInlineBuffer方法用于采用redis协议解析客户端内容并生成对应的命令并传给processCommand 方法,processCommand方法则用于执行该命令
- processCommand方法会以下操作:
- 处理是否为quit命令。
- 对命令语法及参数会进行检查。
- 这里如果采取认证也会检查认证信息。
- 如果Redis为集群模式,这里将进行hash计算key所属slot并进行转向操作。
- 如果设置最大内存,那么检查内存是否超过限制,如果超过限制会根据相应的内存策略删除符合条件的键来释放内存
- 如果这是一个主服务器,并且这个服务器之前执行bgsave发生了错误,那么不执行命令
- 如果min-slaves-to-write开启,如果没有足够多的从服务器将不会执行命令
注:所以DBA在此的设置非常重要,建议不是特殊场景不要设置。
- 如果这个服务器是一个只读从库的话,拒绝写入命令。
- 在订阅于发布模式的上下文中,只能执行订阅和退订相关的命令
- 当这个服务器是从库,master_link down 并且slave-serve-stale-data 为 no 只允许info 和slaveof命令
- 如果服务器正在载入数据到数据库,那么只执行带有REDIS_CMD_LOADING标识的命令
- lua脚本超时,只允许执行限定的操作,比如shutdown、script kill 等
-
最后进入call方法, 决定调用具体的命令
-
setCommand方法,setCommand方法会调用setGenericCommand方法,该方法首先会判断该key是否已经过期,最后调用setKey方法。
这里需要说明一点的是,通过以上的分析。redis的key过期包括主动检测以及被动监测
主动监测
- 在beforeSleep方法中执行key快速过期检查,检查模式为ACTIVE_EXPIRE_CYCLE_FAST。周期为每个事件执行完成时间到下一次事件循环开始
- 在serverCron方法中执行key过期检查,这是key过期检查主要的地方,检查模式为ACTIVE_EXPIRE_CYCLE_SLOW,* serverCron方法执行周期为1秒钟执行server.hz 次,hz默认为10,所以约100ms执行一次。hz设置越大过期键删除就越精准,但是cpu使用率会越高,这里我们线上redis采用的默认值。redis主要是在这个方法里删除大部分的过期键。
被动监测
- 使用内存超过最大内存被迫根据相应的内存策略删除符合条件的key。
- 在key写入之前进行被动检查,检查key是否过期,过期就进行删除。
- 还有一种不友好的方式,就是randomkey命令,该命令随机从redis获取键,每次获取到键的时候会检查该键是否过期。
以上主要是让运维的同学更加清楚redis的key过期删除机制。
-
进入setKey方法,setKey方法最终会调用dbAdd方法,其实最终就是将该键值对存入服务器端维护的一个字典中,该字典是在服务器初始化的时候创建,用于存储服务器的相关信息,其中包括各种数据类型的键值存储。完成了写入方法时候,此时服务器端会给客户端返回结果。
-
进入prepareClientToWrite方法然后通过调用_addReplyToBuffer方法将返回结果写入到outbuf中(客户端连接时创建的client)
- 通过aeCreateFileEvent方法注册文件写事件并绑定sendReplyToClient方法
server返回写入结果

checkTcpBacklogSettings
/* Check that server.tcp_backlog can be actually enforced in Linux according to the value of /proc/sys/net/core/somaxconn, or warn about it. */
listenToPort 是直接调用net接口了。后面再说吧
prepareForShutdown
- 通知system fd关机
- 干掉lua debugger
- 干掉rdb子进程。
- 干掉module子进程
- 干掉aof子进程
- unlink pid文件
- 关闭socket
info信息构造
bytesToHuman
/* Convert an amount of bytes into a human readable string in the form
* of 100B, 2G, 100M, 4K, and so forth. */
void bytesToHuman(char *s, unsigned long long n) {
double d;
if (n < 1024) {
/* Bytes */
sprintf(s,"%lluB",n);
} else if (n < (1024*1024)) {
d = (double)n/(1024);
sprintf(s,"%.2fK",d);
} else if (n < (1024LL*1024*1024)) {
d = (double)n/(1024*1024);
sprintf(s,"%.2fM",d);
} else if (n < (1024LL*1024*1024*1024)) {
d = (double)n/(1024LL*1024*1024);
sprintf(s,"%.2fG",d);
} else if (n < (1024LL*1024*1024*1024*1024)) {
d = (double)n/(1024LL*1024*1024*1024);
sprintf(s,"%.2fT",d);
} else if (n < (1024LL*1024*1024*1024*1024*1024)) {
d = (double)n/(1024LL*1024*1024*1024*1024);
sprintf(s,"%.2fP",d);
} else {
/* Let's hope we never need this */
sprintf(s,"%lluB",n);
}
}
rdb文件是内存的一份快照
rdbLoad
代码很短
if ((fp = fopen(filename,"r")) == NULL) return C_ERR;
startLoadingFile(fp, filename,rdbflags);
rioInitWithFile(&rdb,fp);//绑定write read flush 等系统api
retval = rdbLoadRio(&rdb,rdbflags,rsi); //正式读
fclose(fp);
stopLoading(retval==C_OK);
rdbLoadRio 处理一些不同类型的数据,像文件头,selectdb号,moduleID等等,处理完之后会进入真正的读string object。kv都帮到一起了,rdb加载就能直接解出来,主要逻辑
//while(1)
if ((key = rdbLoadStringObject(rdb)) == NULL) goto eoferr;
/* Read value */
if ((val = rdbLoadObject(type,rdb,key)) == NULL) {
decrRefCount(key);
goto eoferr;
}
rdbLoadObject解出来每一个object,拿到value。这个函数会根据每种类型来解。如果是list之类的还要在内部继续遍历继续解。代码500行,不抄了
具体的格式见参考链接,我直接抄过来
----------------------------# RDB文件是二进制的,所以并不存在回车换行来分隔一行一行.
52 45 44 49 53 # 以字符串 "REDIS" 开头
30 30 30 33 # RDB 的版本号,大端存储,比如左边这个表示版本号为0003
----------------------------
FE 00 # FE = FE表示数据库编号,Redis支持多个库,以数字编号,这里00表示第0个数据库
----------------------------# Key-Value 对存储开始了
FD $length-encoding # FD 表示过期时间,过期时间是用 length encoding 编码存储的,后面会讲到
$value-type # 1 个字节用于表示value的类型,比如set,hash,list,zset等
$string-encoded-key # Key 值,通过string encoding 编码,同样后面会讲到
$encoded-value # Value值,根据不同的Value类型采用不同的编码方式
----------------------------
FC $length-encoding # FC 表示毫秒级的过期时间,后面的具体时间用length encoding编码存储
$value-type # 同上,也是一个字节的value类型
$string-encoded-key # 同样是以 string encoding 编码的 Key值
$encoded-value # 同样是以对应的数据类型编码的 Value 值
----------------------------
$value-type # 下面是没有过期时间设置的 Key-Value对,为防止冲突,数据类型不会以 FD, FC, FE, FF 开头
$string-encoded-key
$encoded-value
----------------------------
FE $length-encoding # 下一个库开始,库的编号用 length encoding 编码
----------------------------
... # 继续存储这个数据库的 Key-Value 对
FF ## FF:RDB文件结束的标志
Magic Number
第一行就不用讲了,REDIS字符串用于标识是Redis的RDB文件
版本号
用了4个字节存储版本号,以大端(big endian)方式存储和读取
数据库编号
以一个字节的0xFE开头,后面存储数据库的具体编号,数据库的编号是一个数字,通过 “Length Encoding” 方式编码存储,“Length Encoding” 我们后面会讲到。
Key-Value值对
值对包括下面四个部分 1. Key 过期时间,这一项是可有可无的 2. 一个字节表示value的类型 3. Key的值,Key都是字符串,通过 “Redis String Encoding” 来保存 4. Value的值,通过 “Redis Value Encoding” 来根据不同的数据类型做不同的存储
Key过期时间
过期时间由 0xFD 或 0xFC开头用于标识,分别表示秒级的过期时间和毫秒级的过期时间,后面的具体时间是一个UNIX时间戳,秒级或毫秒级的。具体时间戳的值通过“Redis Length Encoding” 编码存储。在导入RDB文件的过程中,会通过过期时间判断是否已过期并需要忽略。
Value类型
Value类型用一个字节进行存储,目前包括以下一些值:
- 0 = “String Encoding”
- 1 = “List Encoding”
- 2 = “Set Encoding”
- 3 = “Sorted Set Encoding”
- 4 = “Hash Encoding”
- 9 = “Zipmap Encoding”
- 10 = “Ziplist Encoding”
- 11 = “Intset Encoding”
- 12 = “Sorted Set in Ziplist Encoding”
Key
Key值就是简单的 “String Encoding” 编码,具体可以看后面的描述
Value
上面列举了Value的9种类型,实际上可以分为三大类
- type = 0, 简单字符串
- type 为 9, 10, 11 或 12, value字符串在读取出来后需要先解压
- type 为 1, 2, 3 或 4, value是字符串序列,这一系列的字符串用于构建list,set,hash 和 zset 结构
Length Encoding
上面说了很多 Length Encoding ,现在就为大家讲解。可能你会说,长度用一个int存储不就行了吗?但是,通常我们使用到的长度可能都并不大,一个int 4个字节是否有点浪费呢。所以Redis采用了变长编码的方法,将不同大小的数字编码成不同的长度。
- 首先在读取长度时,会读一个字节的数据,其中前两位用于进行变长编码的判断
- 如果前两位是 0 0,那么下面剩下的 6位就表示具体长度
- 如果前两位是 0 1,那么会再读取一个字节的数据,加上前面剩下的6位,共14位用于表示具体长度
- 如果前两位是 1 0,那么剩下的 6位就被废弃了,取而代之的是再读取后面的4 个字节用于表示具体长度
- 如果前两位是 1 1,那么下面的应该是一个特殊编码,剩下的 6位用于标识特殊编码的种类。特殊编码主要用于将数字存成字符串,或者编码后的字符串。具体见 “String Encoding”
这样做有什么好处呢,实际就是节约空间:
- 0 – 63的数字只需要一个字节进行存储
- 而64 – 16383 的数字只需要两个字节进行存储
- 16383 - 2^32 -1 的数字只需要用5个字节(1个字节的标识加4个字节的值)进行存储
String Encoding
Redis的 String Encoding 是二进制安全的,也就是说他没有任何特殊分隔符用于分隔各个值,你可以在里面存储任何东西。它就是一串字节码。 下面是 String Encoding 的三种类型
- 长度编码的字符串
- 数字替代字符串:8位,16位或者32位的数字
- LZF 压缩的字符串
长度编码字符串
长度编码字符串是最简单的一种类型,它由两部分组成,一部分是用 “Length Encoding” 编码的字符串长度,第二部分是具体的字节码。
数字替代字符串
上面说到过 Length Encoding 的特殊编码,就在这里用上了。所以数字替代字符串是以 1 1 开头的,然后读取这个字节剩下的6 位,根据不同的值标识不同的数字类型:
- 0 表示下面是一个8 位的数字
- 1 表示下面是一个16 位的数字
- 2 表示下面是一个32 位的数字
LZF压缩字符串
和数据替代字符串一样,它也是以1 1 开头的,然后剩下的6 位如果值为4,那么就表示它是一个压缩字符串。压缩字符串解析规则如下:
- 首先按 Length Encoding 规则读取压缩长度 clen
- 然后按 Length Encoding 规则读取非压缩长度
- 再读取第二个 clen
- 获取到上面的三个信息后,再通过LZF算法解码后面clen长度的字节码
List Encoding
Redis List 结构在RDB文件中的存储,是依次存储List中的各个元素的。其结构如下:
- 首先按 Length Encoding 读取这个List 的长度 size
- 然后读取 size个 String Encoding的值
- 然后再用这些读到的 size 个值重新构建 List就完成了
Set Encoding
Set结构和List结构一样,也是依次存储各个元素的
Sorted Set Encoding
也是和list类似的,注意double有两种保存方法,做了优化,所以读取也要做区分
Hash Encoding
- 首先按 Length Encoding 读出hash 结构的大小 size
- 然后读取2×size 个 String Encoding的字符串(因为一个hash项包括key和value两项)
- 将上面读取到的2×size 个字符串解析为hash 和key 和 value
- 然后将上面的key value对存储到hash结构中
注意这个整理,现在6.0版本是不准的,多了module和stream。
其中stream的处理方法是类似的,也是遍历
rdbSaveRio
逐个保存,所有的kv对都变成string
核心逻辑
for(all db)
for(each type)
rdbSaveKeyValuePair()
rdb文件整体都是大端的。这也算方便跨平台吧
6.0带来的一大改动就是多线程IO了。
IOThreadMain
多线程IO读。提高并发。核心代码
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
readQueryFromClient
核心代码没什么好说的
nread = connRead(c->conn, c->querybuf+qblen, readlen);
if (nread == -1) {
if (connGetState(conn) == CONN_STATE_CONNECTED) {
return;
} else {
serverLog(LL_VERBOSE, "Reading from client: %s",connGetLastError(c->conn));
freeClientAsync(c);
return;
}
} else if (nread == 0) {
serverLog(LL_VERBOSE, "Client closed connection");
freeClientAsync(c);
return;
} else if (c->flags & CLIENT_MASTER) {
/* Append the query buffer to the pending (not applied) buffer
* of the master. We'll use this buffer later in order to have a
* copy of the string applied by the last command executed. */
c->pending_querybuf = sdscatlen(c->pending_querybuf,
c->querybuf+qblen,nread);
}
这里读完,后面是processInputBufferAndReplicate->processInputBuffer 解析完命令等执行
从客户链接读数据,几个优化点
- 内存预分配,和redis业务相关。不讲
- postponeClientRead 如果IO线程没读完,接着读,别处理
createClient
- 绑定handler等等
- noblock, tcpnodelay, keepalive
- 上线文设定,buf,db,cmd,auth等等
- 对应freeclient
- 各种释放缓存,unwatch unpubsub
- unlinkClient 处理handler,关掉fd,如果有pending,扔掉
prepareClientToWrite
- 如果不能写,需要把client标记成pending_write,等调度
各种accept略过
各种buffer处理总入口,processInputBuffer的一层封装
redis支持两种协议,redis protocol,或者inline,按行读
processInputBuffer在检查各种flag之后,根据字符串开头是不是array来判断是processMultibulkBuffer还是processInlineBuffer
Client相关的帮助函数这里省略
stream
整体架构
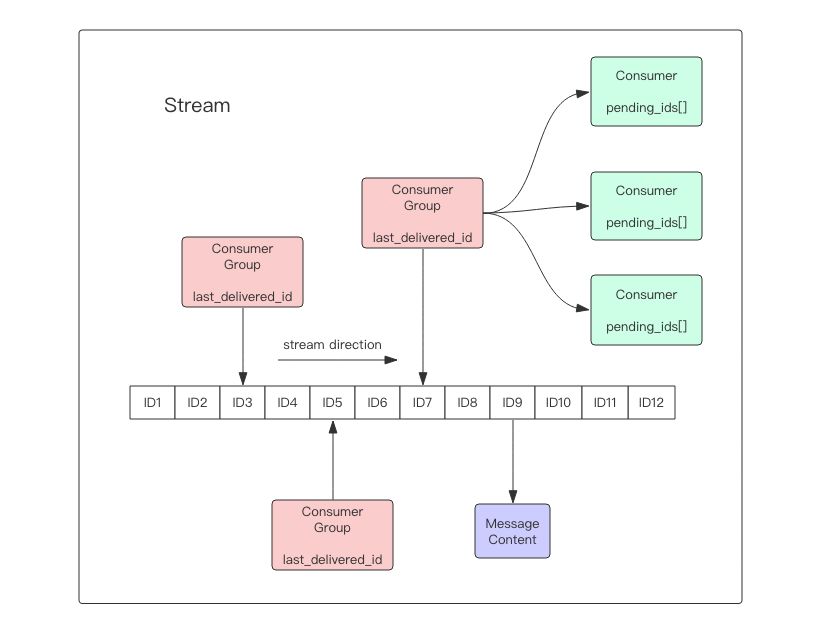
- 每个消息都有一个唯一的ID和对应的内容
-
每个Stream都有唯一的名称,Redis key
-
每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
-
每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。
-
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者者有一个组内唯一名称。
- 消费者(Consumer)内部会有个状态变量
pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
简单说
stream key 每条消息存储并生成streamid-seq,然后id和消费组挂钩,消费组内部有游标和消费者,消费者和消费组挂钩。是串行消费游标信息。
如果把stream编码成kv需要怎么做?
首先,stream key本身维护一组信息,需要知道最后一个streamid,需要知道stream个数,本身就算是一个元数据
其次,stream key需要和子字段,streamid编码,方便区分是谁的key的streamID下的字段
消费组,这也算是一个元数据,需要保存最后一个消费到的id,为了快速定位消费组,可以保存到stream key的value里。
然后就是消费者了,这个就是PEL,消费者应该没有必要单独存一个表 。
ref
- redis设计与实现试读内容,基本上一大半。还有源码注释做的不错。我基本上照着注释写的。http://redisbook.com/ redisbook 讲的太详细了,huangz还给了个阅读建议。我重写主要是落实一下脑海中的概念,便于后续翻阅。redis代码走读的东西太多了,我的方向偏向于改动源码需要了解的东西。
- huangz给的建议,如何阅读redis代码http://blog.huangz.me/diary/2014/how-to-read-redis-source-code.html
- 大部分都抄自这里 http://www.zbdba.com/2018/06/23/深入浅出-redis-client-server交互流程/
- https://ningyu1.github.io/site/post/34-redis-rdb/
- https://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=2653549949&idx=1&sn=7f6c4cf8642478574718ed0f8cf61409&chksm=813a64e5b64dedf357cef4e2894e33a75e3ae51575a4e3211c1da23008ef79173962e9a83c73&mpshare=1&scene=1&srcid=0717FcpVc16q9rNa0yfF78FU#rd
- http://chenzhenianqing.com/articles/1622.html
- http://chenzhenianqing.com/articles/1649.html

