rockset是如何使用rocksdb的
20211210 他们的rocksdb开源了。有时间看看 https://github.com/rockset/rocksdb-cloud
rockset 是一个db服务提供商,他们用rocksdb来实现converged indexing 我也不明白是什么意思,在参考链接2有介绍,大概就是有一个文档,保存成行,成列,成index,他们大量采用的rocksdb
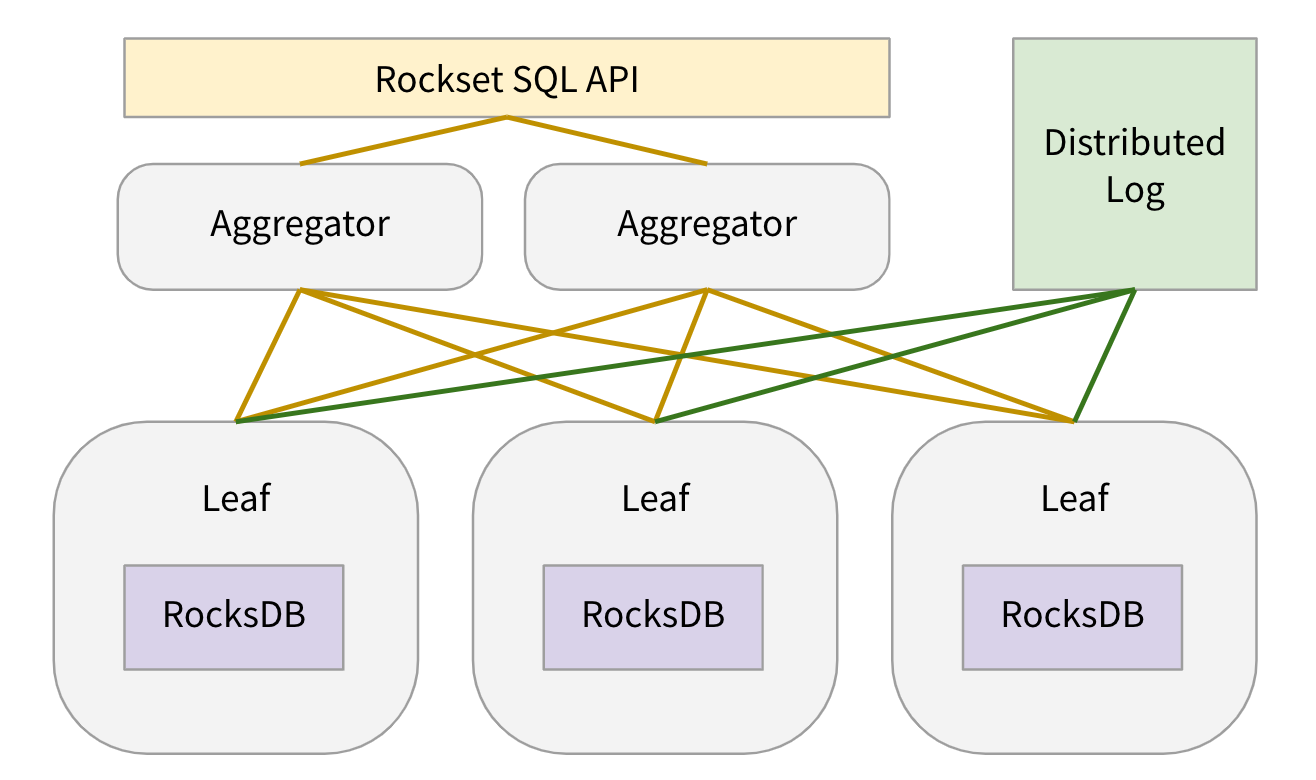
架构图是这样的
用户创建一个表会分成N个分片,每个分片有两个以上副本,每个分片副本放在一个rocksdb 叶节点上,每个叶节点有很多表的众多副本(他们的线上环境有一百多个),一个叶节点的一个分片副本有一个rocksdb实例,更多细节看参考链接34
下面是他们的优化手段
rocksdb-cloud
rocksdb本身是嵌入式数据存储,本身不高可用,Rockset做了rocksdb-cloud,基于S3来实现高可用
禁止WAL
架构本身有分布式日志存储来维护日志,不需要rocksdb本身的wal
Writer Rate Limit 写速率
叶节点接受查询和写,rockset能接受/ 容忍大量写导致查的高延迟,但是,还是想尽可能的让查的能力更平稳一些,所以限制了rocksdb实例的写速率,限制了并发写的线程数,降低写导致的查询延迟
在限制写的同时,也要让LSM 更平衡和以及主动触发rocksdb的stall机制,(?rocksdb原生没有,rockset自己实现的。rockset也要实现从应用到rocksdb端的限流
Sorted Write Batch
如果组提交是排好序的,并发写会更快,应用上层写的时候会自己排序
Dynamic Level Target Sizes
涉及到rocksdb compactiong策略,level compaction,本层文件大小没达到上限是不会做compact的,每层都是十倍放大,空间放大非常恐怖,见参考链接5描述,为了避免这个,上限大小编程动态的了,这样避免空间放大
AdvancedColumnFamilyOptions::level_compaction_dynamic_level_bytes = true
Shared Block Cache
这个是经验了,一个应用内,共用同一个blockcache,这样内存利用更可观
rockset使用25% 的内存来做block cache,故意留给系统page cache一部分,因为page cache保存了压缩的block,block cache保存解压过的block,page cache能降低一点系统读压力
参考链接6的论文也有介绍
L0 L1层不压缩
L0 L1层文件compact带来的优势不大,并且 L0 compact到L1层需要访问L1的文件,范围扫描也利用用不上L0的bloom filter 压缩白白浪费cpu
rocksdb 团队也推荐L0 L1不压缩,剩下的用LZ4压缩
bloom filter on key prefix
这和rockset的设计有关, 每个文档的每个字段都保存了三种方式(行,列,索引),这就是三种范围,所以查询也得三种查法,不用点查,用前缀范围查询,所以 BlockBasedTableOptions::whole_key_filtering to false,这样bloomfilter也会有问题,所以定制了ColumnFamilyOptions::prefix_extractor,针对特定的前缀来构造bloom filter
iterator freepool 迭代器池子
大量的范围查询创建大量的iterator,这是很花费性能的,所以有iterator 池,尽可能复用
综上,配置如下
Options.max_background_flushes: 2
Options.max_background_compactions: 8
Options.avoid_flush_during_shutdown: 1
Options.compaction_readahead_size: 16384
ColumnFamilyOptions.comparator: leveldb.BytewiseComparator
ColumnFamilyOptions.table_factory: BlockBasedTable
BlockBasedTableOptions.checksum: kxxHash
BlockBasedTableOptions.block_size: 16384
BlockBasedTableOptions.filter_policy: rocksdb.BuiltinBloomFilter
BlockBasedTableOptions.whole_key_filtering: 0
BlockBasedTableOptions.format_version: 4
LRUCacheOptionsOptions.capacity : 8589934592
ColumnFamilyOptions.write_buffer_size: 134217728
ColumnFamilyOptions.compression[0]: NoCompression
ColumnFamilyOptions.compression[1]: NoCompression
ColumnFamilyOptions.compression[2]: LZ4
ColumnFamilyOptions.prefix_extractor: CustomPrefixExtractor
ColumnFamilyOptions.compression_opts.max_dict_bytes: 32768
ref
- https://rockset.com/blog/how-we-use-rocksdb-at-rockset/
- https://rockset.com/blog/converged-indexing-the-secret-sauce-behind-rocksets-fast-queries/
- https://rockset.com/blog/aggregator-leaf-tailer-an-architecture-for-live-analytics-on-event-streams/
- https://www.rockset.com/Rockset_Concepts_Design_Architecture.pdf
- https://rocksdb.org/blog/2015/07/23/dynamic-level.html
- http://cidrdb.org/cidr2017/papers/p82-dong-cidr17.pdf
