blog review 第二十八期
最近了解了一下数据库创业的情况
另外公众号广告收入达到新高,80块
还有广告商对接!头一回啊
和白总聊天涨了很多见识
10x速度 就可以创业了,redpanda,各种pg竞品,kafka竞品
redis社区有些功能不接受PR更多是商业角度考虑
keydb也做redis on flash了。最近看到携程也做了一个。其实就是rocksdb降冷
如果能降rocksdb,那我为什么不直接一点降到对象存储,redis本身内存大户,没法给rocksdb cache空间
根本用不出rocksdb优势
去O 一体机化,整机优化,算力卸载硬件,数据压缩可读 极致省空间
文件存储不可能放大二倍,小文件更多选择,meta和小文件混合存储 小文件甚至可以rocksdb存储
之前在哪里看到的多个小文件合成一个,文件空洞岂不是很恐怖
AI创业方向,语料的小文件问题更严重,99%都是小文件,怎么做到小雨二倍冗余?很难想象
对于点查要求的极高性能要怎么做
业界有用rocksdb存meta的方案。最后都改成自定义了。自建hashtable(raftengine那种?点查收益更高
找老同事吃饭,也聊了一些收益问题。做云kv感觉死路一条啊
也面试了很多公司。感觉创业真是艰难啊。我可能最后还是放弃走创业公司的想法了
OSDI'22 ListDB
贡献:
- (i) 字节寻址的 IndexUnified Logging,它增量地将预写日志转换为 SkipList;
- (ii) Braided SkipList,一个简单的 NUMA-aware SkipList,它有效地减少了 NVMM 的 NUMA 影响;
- (iii) Zipper Compaction,它不复制键值对象向下移动 LSM 树 levels,但是通过就地合并 SkipList 而不阻塞并发读取。
通过使用这三种技术,ListDB 使后台压缩足够快,解决写停顿问题
得看代码
架构图 http://timd.cn/distributed-system-disaster-recovery-architecture/
50 years later, is Two-Phase Locking the best we can do?
给2pl加了个wait-free转移,叫2plsf 代码 https://github.com/pramalhe/2PLSF/blob/main/stms/2PLSF.hpp
这哥们博客有点东西
Paper Reading: TRIAD, a Key-Value Store
日志频繁写,膨胀,需要感知到
- TRIAD-MEM 移动冷数据,热数据pin住
- TRIAD-DISK 使用HLL判定重叠程度, uniquekey/sumkey
- TRIAD-LOG 直接转sst文件
git@github.com:epfl-labos/TRIAD.git
A shallow survey of OLAP and HTAP query engines
直接看15721得了
Minimizing S3 API Costs with Distributed mmap
mmap + s3
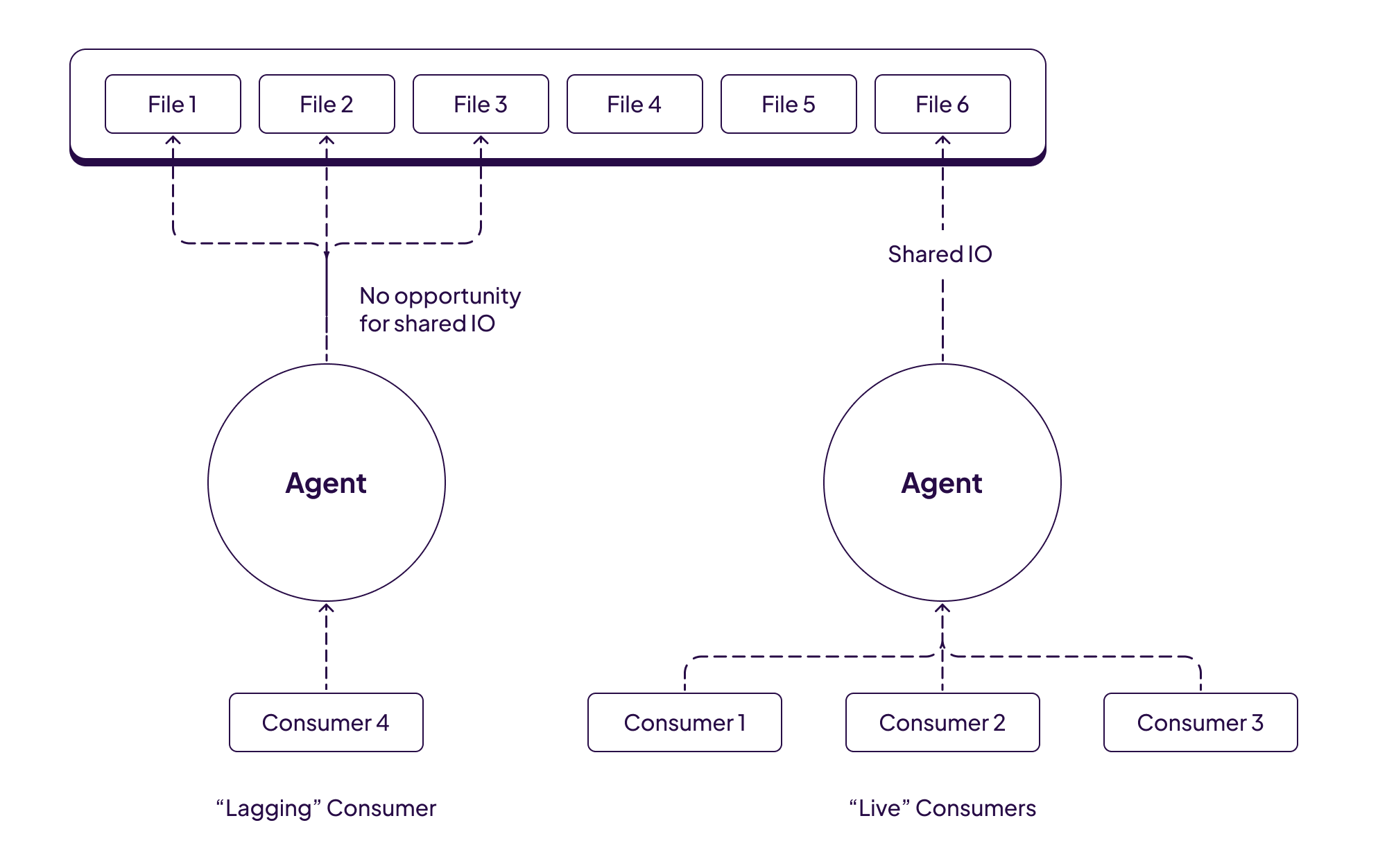
可能是唯一亮点,共享IO
假设rocksdb场景,如果blockcache没命中,多个相同的IO请求能不能pin住合成一个请求?当然pagecache硬抗也可以
Demystifying Database Transactions
各种事务场景介绍
A Comprehensive Dive into the New Time-Series Storage Engine - Mito?
TODO
存储格式调研 Kudu篇
Source file: mmd/cfile.mmd:
一个CFile放置DiskRowSet的一个列或者一个DeltaFile,此外BF或者ad-hoc索引也存储在单独的CFIle。 CFile由Header,Blocks和footer组成。其中block包含了datablocks,nullable blocks,index blocks,dictionary blocks。 datablocks:存数据 indexblocks:存datablock跟rowid之间的映射关系
CFile的Data Encoding
- Plain: 不做encoding
- Dictionary: 对String和Binary有效,字典是在整CFile级别,如果Dictionary block装不下这么多字典,就说明重复数据不多,会直接回退plain
- Prefix: 针对BINARY and STRING ,去除掉跟前一个Value的公共部分,每隔一段时间会有一个restart point,所以随机查询的时候可以先找到restart point
- RLE: Integer and bool types, “aaaa”可以存成啊*4
- BitShuffle: 把高位放在一起,低位放在一起,高位大概率全是0,增加压缩的概率。如果遇到重复数据,几乎所有的bit都是一样的,压缩效果也非常好。
Writing a storage engine for Postgres: an in-memory Table Access Method
pg也能引擎模块化,社区有几个实现
比如 https://github.com/orioledb/orioledb
https://github.com/citusdata/citus/blob/main/src/backend/columnar/README.md
为什么有这个需求?
场景不同
AP可能就要列存一些
写的猛可能就LSM一些
这个是手把手教你写一个
Resolving a year-long ClickHouse lock contention
首先监控https://github.com/ClickHouse/ClickHouse/pull/55029/files
然后复现,拆锁 https://github.com/ClickHouse/ClickHouse/pull/55121
无锁编程实践:RocksDB ThreadLocalPtr剖析
superversion的修改动作可以看成一个读写观测,就需要这种tls管理
TX-Rocks Sum性能调优之旅
优化点三:多线程并发
多线程并发最主要的是要解决数据的并发拆分问题,在讨论具体的拆分策略之前,我们首先要明确几点:
拆分对象内容的获取
由于MyRocks的多个索引共享一个Column Family参考1,其数据视图对应于Rocksdb的Version ,MyRocks及Rocksdb中并没有一个可以和索引相对应的数据视图,那么需要怎么获取待拆分索引的全部内容?所幸,MyRocks对索引中每条Record进行编码时都带上了indexid做前缀参考2,因此(indexid_0000, (indexid+1)_0000)的双开区间即可以表示某个column family中属于某个索引的全部数据,通过这个范围即可对应的version中过滤出需要的数据。
拆分的依据
基于什么信息进行拆分?怎么保证拆分的尽量均匀?这里有两种备选拆分策略: (1) 静态拆分。即假如需要拆分成4个线程,那么用(indexid_0000, indexid_0000_00], (indexid_0000_00, indexid_0000_01],(indexid_0000_01, indexid_0000_10],(indexid_0000_10, (indexid+1)_0000),四个区间即可对整个索引进行拆分。但是这种策略有一个坏处就是各个区间的记录个数不容易均匀,这会降低并发效果。 (2) 基于数据分布直方图的拆分。也就是根据实际的数据分布范围情况进行分布,尽量使每个分区内的记录数目相近,这样多个并发处理的线程会几乎同时完成,并发效果最好。因此,我们选择了这种方式进行拆分。
数据分布直方图的获取:
Rocksdb中每个Version对象会有一个VersionStorageInfo类型结构体storage_info来保存当前属于Version的所有文件的记录数据、记录范围、以及所处的level等相关信息,这是天然的数据分布直方图,我们只需要选择其中的记录数目最多的层进行范围拆分即可。在代码实现上,这个结构体层次比较深,而且这个对象当前Rocksdb并不对外暴露,不过这些都不是问题。
拆分的粒度
可以基于文件级别,也可以基于记录级别。由于我们的数据直方图中只有文件级别的统计信息,因此只能基于文件级别进行拆分。
基于以上考虑,我们的并发拆分策略如下:
- 获取storage_info;
- 根据storage_info获取当前LSM数的level数目;
- 判断level数据及层次,决定拆分所依据的level层次。
- 如果为1并且是level0层,由于lvel0层的文件之间范围有可能相互重叠,无法拆分,因此这种情况不能进行多线程并发,对应的区间为(indexid_0000, (indexid+1)_0000),拆分算法结束,return;
- 如果level数目为1且不是level0层,则将该层作为待拆分的层次;
- 如果level数目不为1,则遍历除level0层以外的所有层,找到记录数目最多的层次,作为待拆分的层次;
- 获取当前CPU空闲的个数,根据一定算法确定当前可以进行并发的线程数。
- 遍历待拆分的层文件,获取当前层记录的数目,计算出每个线程处理的记录数目为:待拆分记录数/并发线程数。
- 遍历待拆分层的文件,根据每个线程处理的记录数目,将该层的文件分为并发线程数个区间。
Omid Transaction Processing
TODO
Integrate YugabyteDB Logs into Splunk for Comprehensive Monitoring and Analysis
TODO
Data Replication in YugabyteDB
TODO
