blog review 第二十七期
面向离职编程,把你每一行代码,每个文档,都当做离职交接文档。配置文件的详细描述,代码的打包,部署,
测试环境和正式环境的配置,TODO,如何扩展等
https://www.zhihu.com/question/68611994/answer/298467553
最近面试了一堆公司,看看大家都在忙什么
其实kv和存储距离很近,比如ceph用rocksdb存meta
AI公司很多场景要的是个牛逼点查的对象存储
和sue又讨论了一个场景,他有个导入服务和tendis,导入期间延迟升高
导入服务上传文件影响tendis网络延迟了,换成rsync就缓解了;
挺离谱的
ingest导致的升高,可能是memtable重叠导致的写停/compaction
和pika社区讨论到的zset问题
zrange等类似操作没有监控,没有有效的compact策略
而且readoption bound也没设置,prefix_extrator也没设置,我靠
统计操作数compact不是特别准,针对慢的搜索针对性compactkey更好一些
kvrocks做的是基于时间的compact。按理说zset数据特别多,数据混在一起
这种场景基于文件创建时间的排序不是能很好的compact到吧。不过他们社区并没有相关的反馈
ClickHouse Keeper: A ZooKeeper alternative written in C++
能嵌入到clickhouse 也能单独部署
更好的磁盘压缩率
jute.maxbuffer 坑 消息 默认1M cloud.tencent.com
zxid泄露问题
基于nuraft重写
todo 看nuraft
zippydb
For ephemeral data, ZippyDB has native TTL support where the client can optionally specify the expiry time for an object at the time of the write. We piggyback on RocksDB’s periodic compaction support to clean up all the expired keys efficiently while filtering out dead keys on the read side in between compaction runs.
分片管理有个shard manager,可以普通分片,也可以按照key的使用分布来分片,有个akkio服务,特殊处理news feed之类的业务
multipaxos 多写策略
一致性 可配置,可read your own write fast-ack或者线性一致性
事务支持
occ
epoch + write set
Conditional write 这玩意类似dynamo的设计 select for update?
How Facebook deals with PCIe faults to keep our data centers running reliably
简单来说就是定期检查PCIE状态,连接,带宽,分别计算
其他就是PCIE错误处理之类的
taobench
把ycsb-cpp改改,适配图数据库场景
有点意思
其实更多是mysql上建模图数据库的场景 TAO那种就是cache+mysql 优化cache设计
bytegraph好像也这样
避免在分布式系统中回退 fallback
考虑单机回退场景 malloc失败再来个malloc2 很难测 很难维护
再比如读cache读不到读db,这也是一种回退
分布式场景,回退,复杂度xN
怎么解决
- 避免这么用,主动重试,而不是主动回退,增加冲击
- 组件自身有修复机制,而不是靠调用方回退逻辑触发
- 主动推送数据,这也是上面的修复机制的另一种说法
- IAM场景,必须推,如果IAM挂了就完了
- 回退逻辑由于不经常触发可能成为隐患,所以改成一种故障迁移逻辑更常见更可测,风险更低
- 重试/超时不是回退。增加随机性,要增加监控,避免重试/超时成为风暴来源
- 如果回退非常重要,那么要在测试中体现出来
这些要成为checklist
Cache made consisten
引入新节点Polaris 伪装成cache节点,发给其他cache一致性检查
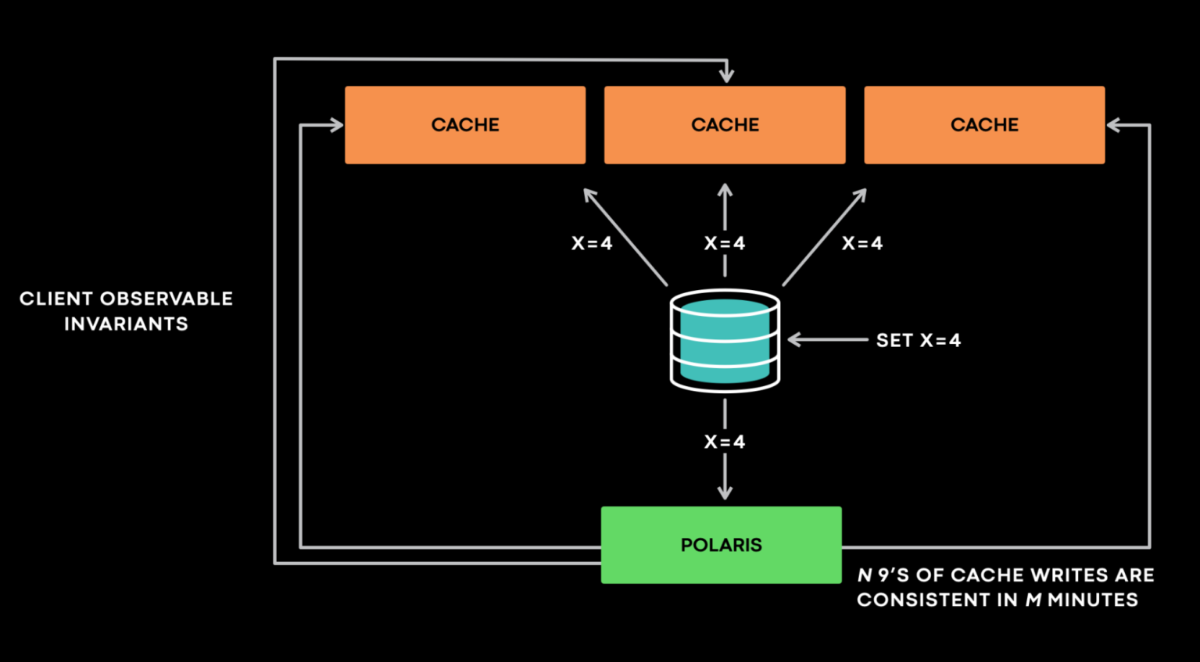
检查可能有问题
- 重试,避免误报报错
- 时机不对,假阳性,polaris收到的cache变动已经是旧的了,新的还没过来
场景,x=3 version 4 查其他cache不存在,这个场景可能是x被删version3 也可能是x被删version5
这种场景只能 反查db来校正,但反查db可能导致后端被打爆。在重试无法解决的场景下
推迟反查,比如一分钟五分钟,之后反查。尽可能拉长窗口避免雪崩
上报指标 N个9在M分钟内 缓存一致
想提高9,就增加polaris服务 增加吞吐,聚集更多数据?perform aggregation over a longer time window.
写回时间窗导致的cache不一致问题
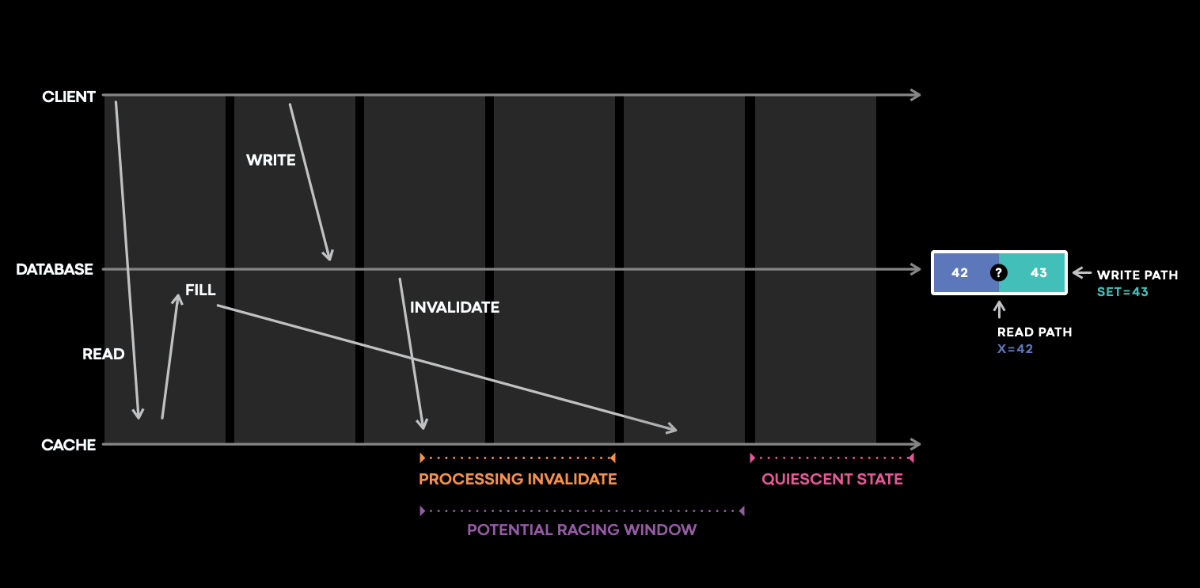
紫色时间窗
只能是记录事件时间序列来回溯?
这种数据也太多了,怎么维护的过来?
然后举了一个版本号相同但data不同的线上bug。
cache更新同时db也在写刷新淘汰缓存,存在这个时间窗,导致更新失败,触发失败淘汰旧key drop_cache(key,version)
但更新是根据version来清除的,version小于才会清除,实际上version相等了,导致key没淘汰掉。
感觉是版本号不够随机,不合理
版本号应该是个逻辑时钟
引入polaris这个checker框架能够更快速的告警发现bug,毕竟这种失败是比较静默的
海量数据问题
最近面试被面到好几次。没准备就是不行啊
简单思路
- 分片缩小数据集(可能是hash也可能是范围) + hash统计 + 堆/快速/归并排序;
- Bloom filter/Bitmap;
- Trie树/数据库/倒排索引;
- 败者树外排序
- Map Reduce。
问题1 多个文件 大于内存 找公共部分/TopK /海量数据找TopK
一般都是hash分片,然后hashmap统计/ 堆排序
问题2 文本文件中频率最高的TopK /wordcount/搜索引擎
trie树构建 堆排序
问题3 1G数据 1M内存 找TopK
内存明显不够用,外排序
问题4 40亿数字集合和一个target,求是否在集合中
bitmap
问题5 亿级别数字 找出不重复的整数的个数
范围分片 + bitmap + bitmap合并
问题6 亿级数字,找中位数
范围分片 统计每个片的个数
Redis 中 BigKey、HotKey 的发现与处理
大key定义
- list/zset > 10000
-
hash 总体大于100M
热key定义
- 满负载请求 70%单一key,执行大量无意义的processcmd
- hash filed > 1000 size >1M hgetall
- zset filed > 10000 zrange -> CPU 升高
大key带来多余的带宽/CPU占用 间接导致热key
热key多余的CPU使用可能导致业务错误
本质还是流量倾斜
如何发现
- 常规 异步分析 scan + object freq 时效性问题
- moniter 影响性能 类似方案已经不维护
- 网络抓包可能性?tcpdump比较麻烦,ebpf感觉有可能,但没见谁用过,只提思路
- 客户端统计 侵入性
- proxy层统计 需要单独实现
如何解决?本质还是打散
- 重组key 按照分片拆开(热key备份),分摊
- 读热点?读写分离
- proxy 可以query cache
- 客户端缓存
京东hotkey方案
收集器,可定制key规则, 收集器将收集的key/传到jvm 缓存
基于etcd watch订阅key收集器
snmalloc
重点设计
Allocations on one thread are freed by a different thread
Deallocations occur in large batches
异步释放内存 - work steal内存管理降低延迟
大内存释放无锁
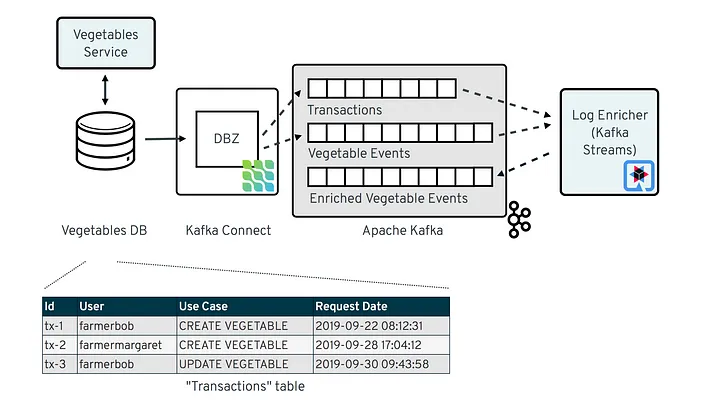
8 Practical Use Cases of Change Data Capture
- 更新cache 案例 https://www.confluent.io/events/kafka-summit-london-2022/keep-your-cache-always-fresh-with-debezium/?source=post_page—–8f059da4c3b7——————————–
- 更新 index 比如ES
- 内存的index数据小,index的变化容易构建
- OLAP数据导入 常规
- 当复制同步用,比如账单
- 当物化视图用,读写分离模式
- 数据交换
- 流数据处理聚集 flink
- 订阅模式
- 报表BI汇聚
Don’t use DISTINCT as a “join-fixer”
distinct暗含排序
select distinct join会多排序,浪费
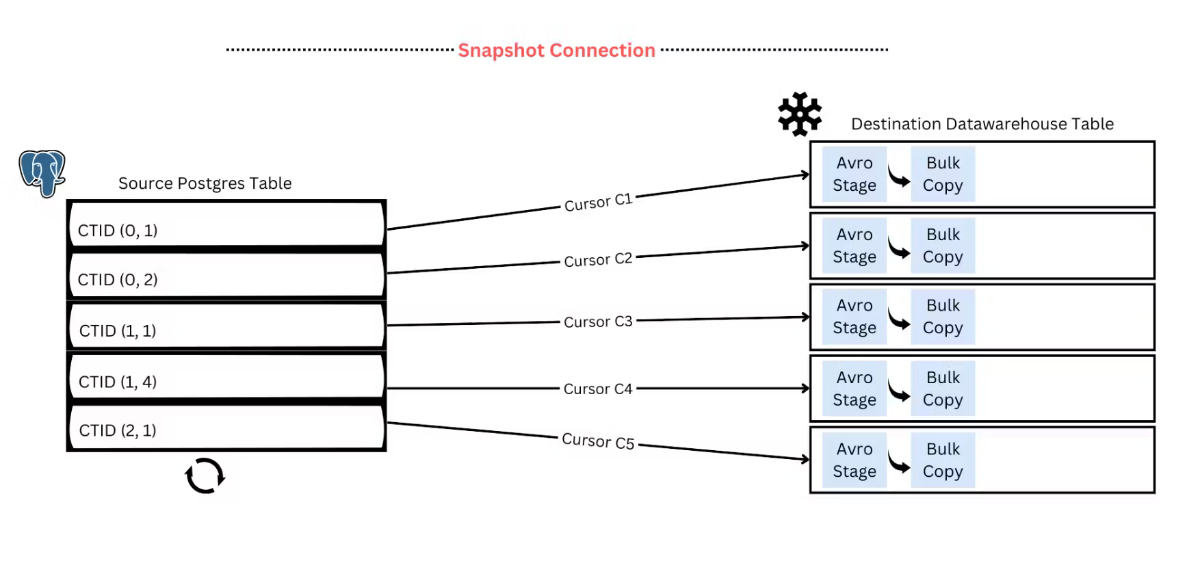
peerdb 迁移为什么快
迁移pg的
We do this by logically partitioning the large table based on internal tuple identifiers (CTID) and parallelly streaming those partitions to Snowflake
学习的duckdb的经验,根据CTID并行化 https://duckdb.org/2022/09/30/postgres-scanner.html#parallel
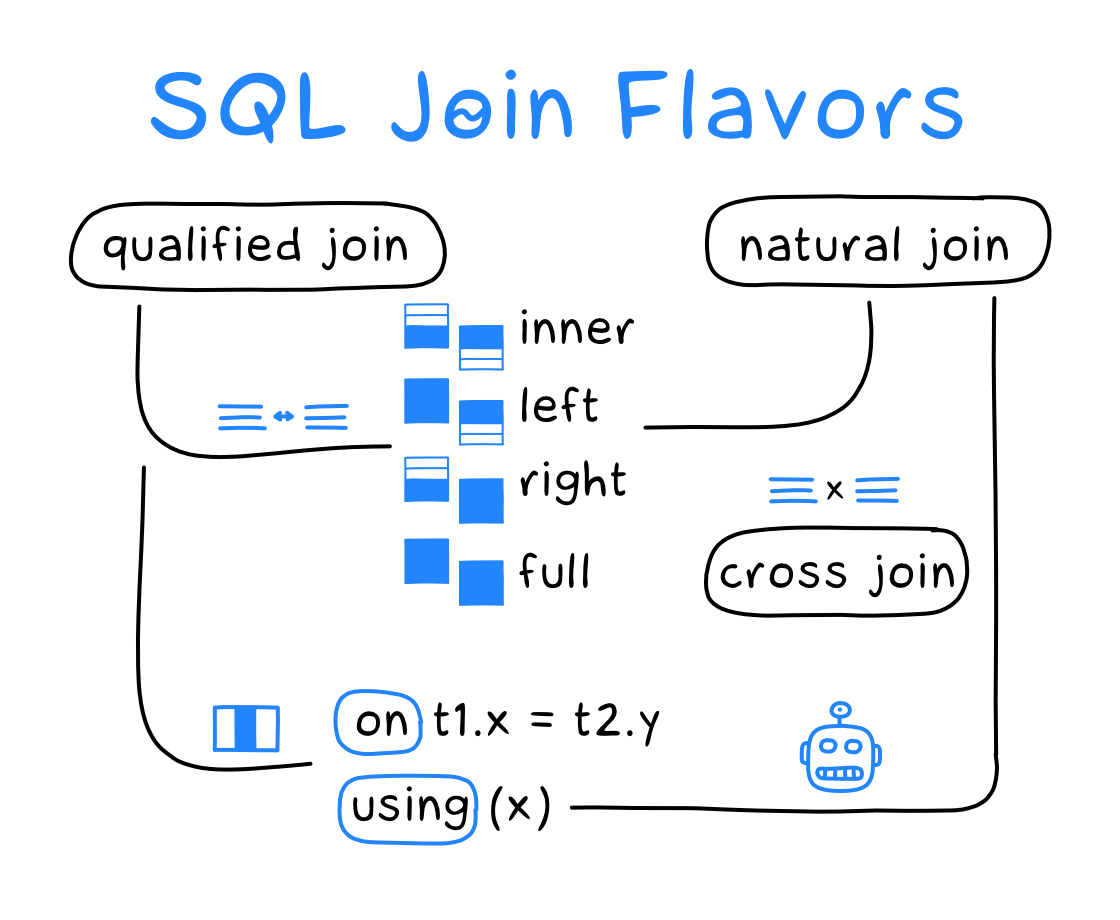
SQL join flavors
一张图解释join,挺好的,马上就懂了
FIFO queues are all you need for cache eviction
感觉就是2Q的一种变种 代码在这 https://github.com/Thesys-lab/sosp23-s3fifo/blob/main/libCacheSim/libCacheSim/cache/eviction/S3FIFO.c
2Q原理
把被访问的数据放到LRU的缓存中,如果这个对象再一次被访问,就把他转移到第二个、更大的LRU缓存,使用了多级缓存的方式。
去除缓存对象是保持第一个缓存池是第二个缓存池的1/3。
Scaling data ingestion for machine learning training at Meta
特征存储是导入的,列举了几个他们的优化思路
首先是读取优化,特征本身是多个维度,只要某一个维度,完全可以列存避免读到别的数据
另外本身特征是多版本的,更适合列存,性能翻倍
对于DPP导入组件来说,这样优化,减少不必要的数据读,性能也有提升
map本身冲突?可以flaten优化省掉无意义读。也降低了服务内存使用
根据读取来重排数据,降低无意义的数据开销 这个思路有点意思。可能得采样读取信息,根据这个profile重新生成数据,哈哈,PGO
连接数超过连接池之后的行为是什么样的?临时连接?
请求限流,没有连接就等,间隔MS之后再创建新的连接,把连接创建平稳下来
问题:大量的连接等同于泄漏,即使平稳了曲线
全链路校验
rpc不偷懒。。加上checksum blake3
降冷
从Raft log层回写key→ cos文件位置的时候,一定要把降冷的kv的version带回来执行cas操作,只有当最新kv仍然是这个version时才能回写,不然可能会覆盖用户最新的写入
热点冲突
- shared promise/query cache 合并
- writecache 增加流程提前解锁,定期刷writecache - 延迟升高
| SAMSUNG MZQL23T8HCLS-00B7C | 210 | 3.84 TB | 6900 MB/s | 4100 MB/s | 1 | https://semiconductor.samsung.com/ssd/datacenter-ssd/pm9a3/mzql23t8hcjs-00a07/ |
|---|---|---|---|---|---|---|
| INTEL SSDPF2KX038TZ | 508 | 3.84 TB | 6500 MBps | 3400 MBps | 1 | https://www.wiredzone.com/shop/product/10021441-intel-ssdpf2kx038tz-3-84tb-drive-nvme-pcie-4-0-u-2-15mm-1dwpd-8252 |
| SAMSUNG MZWLJ3T8HBLS-0007C | 44 | 3.84 TB | 7000 MB/s | 3800 MB/s | 1 | https://semiconductor.samsung.com/ssd/enterprise-ssd/pm1733-pm1735/mzwlj3t8hbls-00007/ |
| INTEL SSDPE2KX040T8 | 63 | 3.84 TB | 2.93 GB/s | 2.83 GB/s | 1 | https://www.wiredzone.com/shop/product/10028040-intel-ssdpe2kx040t8-hard-drive-4tb-nvme-pcie-3-1-3d-tlc-2-5in-u-2-15mm-1dwpd-2266 |
| HFS3T8GETFEI-D430A | 99 | 3.84 TB | 6500 MB/s | 3700 MB/s | 1 | https://product.skhynix.com/products/ssd/essd.go |
| 设备 | 进程 | 流程 |
|---|---|---|
| 客户端 | client | 发起sync |
| 内核 | 物理网卡 | |
| 服务端gw物理机 | 内核 | 物理网卡 bond1 |
| iptables | ||
| ipvs | ||
| 虚拟网卡 vxnet | ||
| flannel | 转发,udp? | |
| gateway | listen & accept | |
| 协议解析 | ||
| 路由查询 | ||
| 子任务拆分执行 | ||
| backup request | ||
| redirect | ||
| 内核 | 虚拟网卡 vxnet | |
| 服务端dbs物理机 | 内核 | 虚拟网卡 vxnet |
| flannel | 本地转发 | |
| database | listen & accept |
服务进程(gw/dbs等)连接处理异常
场景:
业务请求大量超时,或存在明显的IP到IP的延时高或超时
表现:
服务端recv-q阻塞,数值长时间未变动或增加
可能的原因:
过载,超过处理速率
检查cpu是否占满
检查单核
检查单线程
检查k8s 的cpu是否达到limit
检查numa
检查是否存在pipeline串行
软件bug,连接未处理
解决手段:
过载则扩容,注意避免hash映射导致的集中
bug要修,紧急手段要具体分析
k8s组件导致异常连接
场景:
少量IP到IP之前,访问完全不通
服务端是k8s的非host网络
表现:
服务端连未绑定进程(线程id显示 - ),状态是ESTABLISHED,截图不准确(没找到其他图)
对应端口是kube-proxy或者galaxy在监听
原因:
galaxy/kubeproxy进程listen后,相关服务的pod重启过程中客户端尝试建立连接,将不会触发accept
处理手段:
有访问的情况下,可以通过tcpkill断掉指定连接,影响范围较小
无论有无访问,均可通过重启galaxy/kubeproxy(根据对应监听端口确认)的方式来进行恢复
自动断链抖动
dcc断链
dcc有默认断链时长,关键字close
rpc断链
rpc client/service均有断链时长
关键词为idle_time
内核断链
内核默认7200s断链(2h)
sysctl net.ipv4.tcp_keepalive_time
ivps断链
ipvs tcp 默认900s断链(15min)
新上集群调整为7200s(2h) ivpsadm -L –timeout conntrack断链
默认432000s断链(3day) sysctl net.netfilter.nf_conntrack_tcp_timeout_established
dns/路由异常
todo dns缺失
nslookup $dns dns同步缓慢
查看etcd cpu 路由缺失
todo,近期无路由缺失case 路由表过大 iptables -L
上述查询命令查询缓慢,会高频提示有锁 iptables-save | wc -l
检查表项目,通常是表项过多(1W~10W)
此时kubelet组件可能会注册iptables失败,但是仍然ready,导致访问失败
可以通过缩减表项、增加kubelet组件sync频率、或者切换到ipvs策略来解决
netstat netstat -nap | grep gateway | grep ESTAB
其中,-p会打印线程名;会导致开销增加。频繁执行时一般不加-p
注意,容器内外执行效果不同。目前监控只抓了host的 ss ss -nap | grep gateway | grep ESTAB
效率优于netstat,会打印fd。推荐
据说在老版本linux没有安装。但是目前现网设备都支持 tcpkill
伪装rst包以停连接,只能用于有请求的连接。若无请求,则联系开发使用特殊版本。对业务来说,能够感知连接关闭,可能会有微量失败
安装,建议在宿主机
yum install dsniff -y
使用netstat获取需要断链的信息,并聚合
执行,语法和tcpdump近似
tcpkill -i bond1 dst port 20000 and src host 1.1.1.1
会持续抓包断链,需要一定时间
业务可能会新建连接,因此不保证业务访问一定掉底
重新检查连接是否存在
iptables
拉取
iptables -L
等待拉取
iptables -L -w
nat表拉取
iptables -L -w -t nat
纯拉取,无锁
iptables-save
ipvsadm
yum install -y ipvsadm
ipvsadm-save
ipset list
