2019年 二月段子
27 Feb 2019
|
简单说,是一个语法糖
template< class Predicate >
void wait( std::unique_lock<std::mutex>& lock, Predicate pred );
等价于
while (!pred()) {
wait(lock);
}
写过pthread_cond_wait 都明白第二种写法,为了避免虚假唤醒。
标准库还提供不带谓词的wait版本,如果不是用过底层api原语的很容易用错,写成if形式,所以提供了上面这个版本,比较优雅,while形式比较不容易表明意图。
还写了个最佳实践
http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Rconc-wait
话说这个我只是收藏了,从来没看完过,可以理解成more modern effective c++
出自 ` cppcon2014 - Mixins for C++ - Roland Bock` 演讲人是sqlpp11的作者
下面就是根据sqlpp11来讲变参模板+CRTP来实现魔法了。。。
TabFoo foo;
Db db(/* some arguments*/);
// selecting zero or more results, iterating over the results
for (const auto& row : db(select(foo.name, foo.hasFun).from(foo).where(foo.id > 17 and foo.name.like("%bar%"))))
{
if (row.name.is_null())
std::cerr << "name is null, will convert to empty string" << std::endl;
std::string name = row.name; // string-like fields are implicitly convertible to string
bool hasFun = row.hasFun; // bool fields are implicitly convertible to bool
}
如何实现select调用链?抽象出sql语句类 statement_t 定义在这里
template <typename Db, typename... Policies>
struct statement_t : public Policies::template _base_t<detail::statement_policies_t<Db, Policies...>>...,
public expression_operators<statement_t<Db, Policies...>,
value_type_of<detail::statement_policies_t<Db, Policies...>>>,
public detail::statement_policies_t<Db, Policies...>::_result_methods_t
{...
变参模板继承,将policies的属性转发出来,实际上还是元函数转发,变参继承要比之前的手写转发强很多。
policies类都是sql子句或关键字类,比如select_t ,serializer_t分别特化藏起字符串。
struct select_name_t { };
struct select_t : public statement_name_t<select_name_t, tag::is_select> {};
template <typename Context>
struct serializer_t<Context, select_name_t>
{
using _serialize_check = consistent_t;
using T = select_name_t;
static Context& _(const T& /*unused*/, Context& context)
{
context << "SELECT ";
return context;
}
};
template <typename Database>
using blank_select_t = statement_t<Database,
no_with_t,
select_t,
no_select_flag_list_t,
no_select_column_list_t,
no_from_t,
no_where_t<true>,
no_group_by_t,
no_having_t,
no_order_by_t,
no_limit_t,
no_offset_t,
no_union_t,
no_for_update_t>;
//一些blank_select_t的特化
主要是是这个blank_select_t,这就是select的原型了,所有子句都是空的。但都是全的。
所以select
template <typename... Columns>
auto select(Columns... columns) -> decltype(blank_select_t<void>().columns(columns...))
{
return blank_select_t<void>().columns(columns...);
}
这里的blank_select_t会转发给statement_t背后的_base_t ,然后转发给base_t的columns函数,
由于每个子句类都有base_t,这个匹配会匹配第一个由columns函数的,匹配失败不是错误,直到匹配成功为止,
就会匹配到no_select_column_list_t 上
template <typename... Args>
auto columns(Args... args) const
-> _new_statement_t<decltype(_check_args(args...)), detail::make_select_column_list_t<void, Args...>>
{
static_assert(sizeof...(Args), "at least one selectable expression (e.g. a column) required in columns()");
static_assert(decltype(_check_args(args...))::value,
"at least one argument is not a selectable expression in columns()");
return _columns_impl<void>(decltype(_check_args(args...)){}, detail::column_tuple_merge(args...));
}
按照接口,返回的是下一个子句,继续匹配。。假如后面用到了where 在no_where_t::_base_t中
template <typename Expression>
auto where(Expression expression) const
-> _new_statement_t<check_where_static_t<Expression>, where_t<void, Expression>>
{
using Check = check_where_static_t<Expression>;
return _where_impl<void>(Check{}, expression);
}
就会匹配到where函数继续返回新的子句。如果匹配到最后怎么办?什么都匹配不到,临时对象。
这个PPT的主题是多重继承的实现,以及字段字符串的问题
ppt没理解通,代码倒是简单走了一遍,太复杂了。咋想到的。
##TL;DR
直接安装pycflow2dot
pip install pycflow2dot
然后使用命令cflow2dot ,具体可以看帮助(-h)
cflow2dot -i default/berry.c -o b.svg -f svg
该包依赖cflow 和graphviz(aka dot),按需安装即可
题外话
刚搜了个cflow +graphviz的方案,需要中间构造dot文件,需要tree2dotx脚本,我搜了一下关键字,直接蹦出来这个pip包了。利器。分析十分带劲。下面是两个刚抓的图,c++画图稍微有点问题,不过也能画出来


曾经我以为我懂makefile,看着网上的一步一步教你写makefile读完,感觉自己啥都会了。makefile不就是个语法诡异的perl吗,都有cmake了谁还有make。那个时候,我既不懂编译原理,也不懂perl,更不懂cmake,现在我也不太懂。
简单概括流程
顶层makefile直接 引导到src目录$(MAKE) $@ 转发到子目录
make deps 注意有些有文件生成,需要脚本权限(jemalloc说的就是你
chmod 777 deps/jemalloc/configure
chmod 777 src/mkreleasehdr.sh
chmod 777 deps/jemalloc/include/jemalloc/*
chmod 777 deps/jemalloc/scripts/*
这里面好多规则跳跃,有点迷糊。
make流程日志
[root@redis]# make
cd src && make all
sh: ./mkreleasehdr.sh: Permission denied #注意这里,需要权限
make[1]: Entering directory `/root/redis/src'
CC Makefile.dep
make[1]: Leaving directory `/root/redis/src'
sh: ./mkreleasehdr.sh: Permission denied
make[1]: Entering directory `/root/redis/src'
rm -rf redis-server redis-sentinel redis-cli redis-benchmark redis-check-rdb redis-check-aof *.o *.gcda *.gcno *.gcov redis.info lcov-html Makefile.dep dict-benchmark
(cd ../deps && make distclean)
make[2]: Entering directory `/root/redis/deps'
(cd hiredis && make clean) > /dev/null || true
(cd linenoise && make clean) > /dev/null || true
(cd lua && make clean) > /dev/null || true
(cd jemalloc && [ -f Makefile ] && make distclean) > /dev/null || true
(rm -f .make-*)
make[2]: Leaving directory `/root/redis/deps'
(rm -f .make-*)
echo STD=-std=c99 -pedantic -Dredis_STATIC='' >> .make-settings
echo WARN=-Wall -W -Wno-missing-field-initializers >> .make-settings
echo OPT=-O2 >> .make-settings
echo MALLOC=jemalloc >> .make-settings
echo CFLAGS= >> .make-settings
echo LDFLAGS= >> .make-settings
echo redis_CFLAGS= >> .make-settings
echo redis_LDFLAGS= >> .make-settings
echo PREV_FINAL_CFLAGS=-std=c99 -pedantic -Dredis_STATIC='' -Wall -W -Wno-missing-field-initializers -O2 -g -ggdb -I../deps/hiredis -I../deps/linenoise -I../deps/lua/src -DUSE_JEMALLOC -I../deps/jemalloc/include >> .make-settings
echo PREV_FINAL_LDFLAGS= -g -ggdb -rdynamic >> .make-settings
(cd ../deps && make hiredis linenoise lua jemalloc)
make[2]: Entering directory `/root/redis/deps'
(cd hiredis && make clean) > /dev/null || true
(cd linenoise && make clean) > /dev/null || true
(cd lua && make clean) > /dev/null || true
(cd jemalloc && [ -f Makefile ] && make distclean) > /dev/null || true
(rm -f .make-*)
(echo "" > .make-cflags)
(echo "" > .make-ldflags)
MAKE hiredis
cd hiredis && make static
make[3]: Entering directory `/root/redis/deps/hiredis'
ar rcs libhiredis.a net.o hiredis.o sds.o async.o read.o
make[3]: Leaving directory `/root/redis/deps/hiredis'
MAKE linenoise
cd linenoise && make
make[3]: Entering directory `/root/redis/deps/linenoise'
cc -Wall -Os -g -c linenoise.c
make[3]: Leaving directory `/root/redis/deps/linenoise'
MAKE lua
cd lua/src && make all CFLAGS="-O2 -Wall -DLUA_ANSI -DENABLE_CJSON_GLOBAL -Dredis_STATIC='' " MYLDFLAGS="" AR="ar rcu"
make[3]: Entering directory `/root/redis/deps/lua/src'
cc -o luac luac.o print.o liblua.a -lm
make[3]: Leaving directory `/root/redis/deps/lua/src'
MAKE jemalloc
cd jemalloc && ./configure --with-version=5.1.0-0-g0 --with-lg-quantum=3 --with-jemalloc-prefix=je_ --enable-cc-silence CFLAGS="-std=gnu99 -Wall -pipe -g3 -O3 -funroll-loops " LDFLAGS=""
///bin/sh: ./configure: Permission denied 注意这里,也需要权限
make[2]: *** [jemalloc] Error 126
make[2]: Leaving directory `/root/redis/deps'
make[1]: [persist-settings] Error 2 (ignored)
# redis Makefile
# Copyright (C) 2009 Salvatore Sanfilippo <antirez at gmail dot com>
# This file is released under the BSD license, see the COPYING file
#
# The Makefile composes the final FINAL_CFLAGS and FINAL_LDFLAGS using
# what is needed for redis plus the standard CFLAGS and LDFLAGS passed.
# However when building the dependencies (Jemalloc, Lua, Hiredis, ...)
# CFLAGS and LDFLAGS are propagated to the dependencies, so to pass
# flags only to be used when compiling / linking redis itself redis_CFLAGS
# and redis_LDFLAGS are used instead (this is the case of 'make gcov').
#
# Dependencies are stored in the Makefile.dep file. To rebuild this file
# Just use 'make dep', but this is only needed by developers.
#生成 release信息
release_hdr := $(shell sh -c './mkreleasehdr.sh')
#提取Linux
uname_S := $(shell sh -c 'uname -s 2>/dev/null || echo not')
#提取 x85_64
uname_M := $(shell sh -c 'uname -m 2>/dev/null || echo not')
# 优化等级
OPTIMIZATION?=-O2
# 子模块,注意,这里的内容会被转发给make,进入deps层编译,如果加子模块需要改动这里
DEPENDENCY_TARGETS=hiredis linenoise lua
NODEPS:=clean distclean
# Default settings
# 注意这个std=c99
STD=-std=c99 -pedantic -Dredis_STATIC=''
ifneq (,$(findstring clang,$(CC)))
ifneq (,$(findstring FreeBSD,$(uname_S)))
#不用c11拓展?为了兼容性吧,本身都 c99 l
STD+=-Wno-c11-extensions
endif
endif
WARN=-Wall -W -Wno-missing-field-initializers
OPT=$(OPTIMIZATION)
PREFIX?=/usr/local
INSTALL_BIN=$(PREFIX)/bin
INSTALL=install
#设置内存分配器,默认jemalloc
# Default allocator defaults to Jemalloc if it's not an ARM
MALLOC=libc
ifneq ($(uname_M),armv6l)
ifneq ($(uname_M),armv7l)
ifeq ($(uname_S),Linux)
MALLOC=jemalloc
endif
endif
endif
# To get ARM stack traces if redis crashes we need a special C flag.
ifneq (,$(filter aarch64 armv,$(uname_M)))
CFLAGS+=-funwind-tables
else
ifneq (,$(findstring armv,$(uname_M)))
CFLAGS+=-funwind-tables
endif
endif
# Backwards compatibility for selecting an allocator
ifeq ($(USE_TCMALLOC),yes)
MALLOC=tcmalloc
endif
ifeq ($(USE_TCMALLOC_MINIMAL),yes)
MALLOC=tcmalloc_minimal
endif
ifeq ($(USE_JEMALLOC),yes)
MALLOC=jemalloc
endif
ifeq ($(USE_JEMALLOC),no)
MALLOC=libc
endif
# Override default settings if possible
#注意这行 默认是会生成一个 .make-settings文件的,如果有这个文件
#就不会再生成了,所有编译选线都缓存了,所以光改makefile没用,还得把这个文件删掉(make distclean)
-include .make-settings
#下面是调试符号支持和pthread支持,平台各异
FINAL_CFLAGS=$(STD) $(WARN) $(OPT) $(DEBUG) $(CFLAGS) $(redis_CFLAGS)
FINAL_LDFLAGS=$(LDFLAGS) $(redis_LDFLAGS) $(DEBUG)
FINAL_LIBS=-lm
DEBUG=-g -ggdb
ifeq ($(uname_S),SunOS)
# SunOS
ifneq ($(@@),32bit)
CFLAGS+= -m64
LDFLAGS+= -m64
endif
DEBUG=-g
DEBUG_FLAGS=-g
export CFLAGS LDFLAGS DEBUG DEBUG_FLAGS
INSTALL=cp -pf
FINAL_CFLAGS+= -D__EXTENSIONS__ -D_XPG6
FINAL_LIBS+= -ldl -lnsl -lsocket -lresolv -lpthread -lrt
else
ifeq ($(uname_S),Darwin)
# Darwin
FINAL_LIBS+= -ldl
else
ifeq ($(uname_S),AIX)
# AIX
FINAL_LDFLAGS+= -Wl,-bexpall
FINAL_LIBS+=-ldl -pthread -lcrypt -lbsd
else
ifeq ($(uname_S),OpenBSD)
# OpenBSD
FINAL_LIBS+= -lpthread
ifeq ($(USE_BACKTRACE),yes)
FINAL_CFLAGS+= -DUSE_BACKTRACE -I/usr/local/include
FINAL_LDFLAGS+= -L/usr/local/lib
FINAL_LIBS+= -lexecinfo
endif
else
ifeq ($(uname_S),FreeBSD)
# FreeBSD
FINAL_LIBS+= -lpthread -lexecinfo
else
ifeq ($(uname_S),DragonFly)
# FreeBSD
FINAL_LIBS+= -lpthread -lexecinfo
else
# All the other OSes (notably Linux)
FINAL_LDFLAGS+= -rdynamic
FINAL_LIBS+=-ldl -pthread -lrt
endif
endif
endif
endif
endif
endif
#这里是deps目录,指定目录放在这
# Include paths to dependencies
FINAL_CFLAGS+= -I../deps/hiredis -I../deps/linenoise -I../deps/lua/src
ifeq ($(MALLOC),tcmalloc)
FINAL_CFLAGS+= -DUSE_TCMALLOC
FINAL_LIBS+= -ltcmalloc
endif
ifeq ($(MALLOC),tcmalloc_minimal)
FINAL_CFLAGS+= -DUSE_TCMALLOC
FINAL_LIBS+= -ltcmalloc_minimal
endif
ifeq ($(MALLOC),jemalloc)
DEPENDENCY_TARGETS+= jemalloc
FINAL_CFLAGS+= -DUSE_JEMALLOC -I../deps/jemalloc/include
FINAL_LIBS := ../deps/jemalloc/lib/libjemalloc.a $(FINAL_LIBS)
endif
redis_CC=$(QUIET_CC)$(CC) $(FINAL_CFLAGS)
redis_LD=$(QUIET_LINK)$(CC) $(FINAL_LDFLAGS)
redis_INSTALL=$(QUIET_INSTALL)$(INSTALL)
CCCOLOR="\033[34m"
LINKCOLOR="\033[34;1m"
SRCCOLOR="\033[33m"
BINCOLOR="\033[37;1m"
MAKECOLOR="\033[32;1m"
ENDCOLOR="\033[0m"
ifndef V
QUIET_CC = @printf ' %b %b\n' $(CCCOLOR)CC$(ENDCOLOR) $(SRCCOLOR)$@$(ENDCOLOR) 1>&2;
QUIET_LINK = @printf ' %b %b\n' $(LINKCOLOR)LINK$(ENDCOLOR) $(BINCOLOR)$@$(ENDCOLOR) 1>&2;
QUIET_INSTALL = @printf ' %b %b\n' $(LINKCOLOR)INSTALL$(ENDCOLOR) $(BINCOLOR)$@$(ENDCOLOR) 1>&2;
endif
#所有生成文件的obj文件依赖,手写。见all哪里,指定生成文件,调到相应规则,然后找这里的依赖
redis_SERVER_NAME=redis-server
redis_SENTINEL_NAME=redis-sentinel
redis_SERVER_OBJ=adlist.o quicklist.o ae.o anet.o dict.o server.o sds.o zmalloc.o lzf_c.o lzf_d.o pqsort.o zipmap.o sha1.o ziplist.o release.o networking.o util.o object.o db.o replication.o rdb.o t_string.o t_list.o t_set.o t_zset.o t_hash.o config.o aof.o pubsub.o multi.o debug.o sort.o intset.o syncio.o cluster.o crc16.o endianconv.o slowlog.o scripting.o bio.o rio.o rand.o memtest.o crc64.o bitops.o sentinel.o notify.o setproctitle.o blocked.o hyperloglog.o latency.o sparkline.o redis-check-rdb.o redis-check-aof.o geo.o lazyfree.o module.o evict.o expire.o geohash.o geohash_helper.o childinfo.o defrag.o siphash.o rax.o t_stream.o listpack.o localtime.o lolwut.o lolwut5.o swapdata.o thpool.o sp_queue.o
redis_CLI_NAME=redis-cli
redis_CLI_OBJ=anet.o adlist.o dict.o redis-cli.o zmalloc.o release.o anet.o ae.o crc64.o siphash.o crc16.o
redis_BENCHMARK_NAME=redis-benchmark
redis_BENCHMARK_OBJ=ae.o anet.o redis-benchmark.o adlist.o zmalloc.o redis-benchmark.o
redis_CHECK_RDB_NAME=redis-check-rdb
redis_CHECK_AOF_NAME=redis-check-aof
#这是所有编译入口,逐个编译。之前会生成dep,生成依赖。这里的流程没有搞清楚
all: $(redis_SERVER_NAME) $(redis_SENTINEL_NAME) $(redis_CLI_NAME) $(redis_BENCHMARK_NAME) $(redis_CHECK_RDB_NAME) $(redis_CHECK_AOF_NAME)
@echo ""
@echo "Hint: It's a good idea to run 'make test' ;)"
@echo ""
Makefile.dep:
-$(redis_CC) -MM *.c > Makefile.dep 2> /dev/null || true
ifeq (0, $(words $(findstring $(MAKECMDGOALS), $(NODEPS))))
-include Makefile.dep
endif
.PHONY: all
#生成 .make-setting,这里都是编译配置
persist-settings: distclean
echo STD=$(STD) >> .make-settings
echo WARN=$(WARN) >> .make-settings
echo OPT=$(OPT) >> .make-settings
echo MALLOC=$(MALLOC) >> .make-settings
echo CFLAGS=$(CFLAGS) >> .make-settings
echo LDFLAGS=$(LDFLAGS) >> .make-settings
echo redis_CFLAGS=$(redis_CFLAGS) >> .make-settings
echo redis_LDFLAGS=$(redis_LDFLAGS) >> .make-settings
echo PREV_FINAL_CFLAGS=$(FINAL_CFLAGS) >> .make-settings
echo PREV_FINAL_LDFLAGS=$(FINAL_LDFLAGS) >> .make-settings
#注意这里,生成编译配置后会进入deps编译子模块
-(cd ../deps && $(MAKE) $(DEPENDENCY_TARGETS))
.PHONY: persist-settings
#检测是否生成make-setting的一个占位符
# Prerequisites target
.make-prerequisites:
@touch $@
# Clean everything, persist settings and build dependencies if anything changed
ifneq ($(strip $(PREV_FINAL_CFLAGS)), $(strip $(FINAL_CFLAGS)))
.make-prerequisites: persist-settings
endif
ifneq ($(strip $(PREV_FINAL_LDFLAGS)), $(strip $(FINAL_LDFLAGS)))
.make-prerequisites: persist-settings
endif
#所有二进制依赖
# redis-server
$(redis_SERVER_NAME): $(redis_SERVER_OBJ)
$(redis_LD) -o $@ $^ ../deps/hiredis/libhiredis.a ../deps/lua/src/liblua.a $(FINAL_LIBS)
# redis-sentinel
$(redis_SENTINEL_NAME): $(redis_SERVER_NAME)
$(redis_INSTALL) $(redis_SERVER_NAME) $(redis_SENTINEL_NAME)
# redis-check-rdb
$(redis_CHECK_RDB_NAME): $(redis_SERVER_NAME)
$(redis_INSTALL) $(redis_SERVER_NAME) $(redis_CHECK_RDB_NAME)
# redis-check-aof
$(redis_CHECK_AOF_NAME): $(redis_SERVER_NAME)
$(redis_INSTALL) $(redis_SERVER_NAME) $(redis_CHECK_AOF_NAME)
# redis-cli
$(redis_CLI_NAME): $(redis_CLI_OBJ)
$(redis_LD) -o $@ $^ ../deps/hiredis/libhiredis.a ../deps/linenoise/linenoise.o $(FINAL_LIBS)
# redis-benchmark
$(redis_BENCHMARK_NAME): $(redis_BENCHMARK_OBJ)
$(redis_LD) -o $@ $^ ../deps/hiredis/libhiredis.a $(FINAL_LIBS)
dict-benchmark: dict.c zmalloc.c sds.c siphash.c
$(redis_CC) $(FINAL_CFLAGS) $^ -D DICT_BENCHMARK_MAIN -o $@ $(FINAL_LIBS)
# Because the jemalloc.h header is generated as a part of the jemalloc build,
# building it should complete before building any other object. Instead of
# depending on a single artifact, build all dependencies first.
#最开始执行这个,编译,检查prerequisites,不满足会跳到
# persis-setting ,跳到到make-setting, 然后执行编译生成obj文件,最后执行all。
%.o: %.c .make-prerequisites
$(redis_CC) -c $<
#注意这个清理是不清理 .make*文件的。对于普通用户来说,这加速编译了一下,不用反复编译deps模块,对于开发者要注意。
clean:
rm -rf $(redis_SERVER_NAME) $(redis_SENTINEL_NAME) $(redis_CLI_NAME) $(redis_BENCHMARK_NAME) $(redis_CHECK_RDB_NAME) $(redis_CHECK_AOF_NAME) *.o *.gcda *.gcno *.gcov redis.info lcov-html Makefile.dep dict-benchmark
.PHONY: clean
distclean: clean
-(cd ../deps && $(MAKE) distclean)
-(rm -f .make-*)
.PHONY: distclean
test: $(redis_SERVER_NAME) $(redis_CHECK_AOF_NAME)
@(cd ..; ./runtest)
test-sentinel: $(redis_SENTINEL_NAME)
@(cd ..; ./runtest-sentinel)
check: test
lcov:
$(MAKE) gcov
@(set -e; cd ..; ./runtest --clients 1)
@geninfo -o redis.info .
@genhtml --legend -o lcov-html redis.info
test-sds: sds.c sds.h
$(redis_CC) sds.c zmalloc.c -DSDS_TEST_MAIN $(FINAL_LIBS) -o /tmp/sds_test
/tmp/sds_test
.PHONY: lcov
bench: $(redis_BENCHMARK_NAME)
./$(redis_BENCHMARK_NAME)
32bit:
@echo ""
@echo "WARNING: if it fails under Linux you probably need to install libc6-dev-i386"
@echo ""
$(MAKE) CFLAGS="-m32" LDFLAGS="-m32"
gcov:
$(MAKE) redis_CFLAGS="-fprofile-arcs -ftest-coverage -DCOVERAGE_TEST" redis_LDFLAGS="-fprofile-arcs -ftest-coverage"
noopt:
$(MAKE) OPTIMIZATION="-O0"
valgrind:
$(MAKE) OPTIMIZATION="-O0" MALLOC="libc"
helgrind:
$(MAKE) OPTIMIZATION="-O0" MALLOC="libc" CFLAGS="-D__ATOMIC_VAR_FORCE_SYNC_MACROS"
src/help.h:
@../utils/generate-command-help.rb > help.h
install: all
@mkdir -p $(INSTALL_BIN)
$(redis_INSTALL) $(redis_SERVER_NAME) $(INSTALL_BIN)
$(redis_INSTALL) $(redis_BENCHMARK_NAME) $(INSTALL_BIN)
$(redis_INSTALL) $(redis_CLI_NAME) $(INSTALL_BIN)
$(redis_INSTALL) $(redis_CHECK_RDB_NAME) $(INSTALL_BIN)
$(redis_INSTALL) $(redis_CHECK_AOF_NAME) $(INSTALL_BIN)
@ln -sf $(redis_SERVER_NAME) $(INSTALL_BIN)/$(redis_SENTINEL_NAME)
make 参考文档 https://www.gnu.org/software/make/manual/make.pdf
跟我一起写makefile https://seisman.github.io/how-to-write-makefile
[toc]
set
| 命令 | intset 编码的实现方法 |
hashtable 编码的实现方法 |
|---|---|---|
| SADD | 调用 intsetAdd 函数, 将所有新元素添加到整数集合里面。 |
调用 dictAdd , 以新元素为键, NULL 为值, 将键值对添加到字典里面。 |
| SCARD | 调用 intsetLen 函数, 返回整数集合所包含的元素数量, 这个数量就是集合对象所包含的元素数量。 |
调用 dictSize 函数, 返回字典所包含的键值对数量, 这个数量就是集合对象所包含的元素数量。 |
| SISMEMBER | 调用 intsetFind 函数, 在整数集合中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 |
调用 dictFind 函数, 在字典的键中查找给定的元素, 如果找到了说明元素存在于集合, 没找到则说明元素不存在于集合。 |
| SMEMBERS | 遍历整个整数集合, 使用 intsetGet 函数返回集合元素。 |
遍历整个字典, 使用 dictGetKey 函数返回字典的键作为集合元素。 |
| SRANDMEMBER | 调用 intsetRandom 函数, 从整数集合中随机返回一个元素。 |
调用 dictGetRandomKey 函数, 从字典中随机返回一个字典键。 |
| SPOP | 调用 intsetRandom 函数, 从整数集合中随机取出一个元素, 在将这个随机元素返回给客户端之后, 调用 intsetRemove 函数, 将随机元素从整数集合中删除掉。 |
调用 dictGetRandomKey 函数, 从字典中随机取出一个字典键, 在将这个随机字典键的值返回给客户端之后, 调用 dictDelete 函数, 从字典中删除随机字典键所对应的键值对。 |
| SREM | 调用 intsetRemove 函数, 从整数集合中删除所有给定的元素。 |
调用 dictDelete 函数, 从字典中删除所有键为给定元素的键值对。 |
zset
为什么ZSCORE是O(1)的 因为是组合存储的,hashtable+skiplist
内部实现skiplist/ziplist
skiplist

| 命令 | ziplist 编码的实现方法 |
zset 编码的实现方法 |
|---|---|---|
| ZADD | 调用 ziplistInsert 函数, 将成员和分值作为两个节点分别插入到压缩列表。 |
先调用 zslInsert 函数, 将新元素添加到跳跃表, 然后调用 dictAdd 函数, 将新元素关联到字典。 |
| ZCARD | 调用 ziplistLen 函数, 获得压缩列表包含节点的数量, 将这个数量除以 2 得出集合元素的数量。 |
访问跳跃表数据结构的 length 属性, 直接返回集合元素的数量。 |
| ZCOUNT | 遍历压缩列表, 统计分值在给定范围内的节点的数量。 | 遍历跳跃表, 统计分值在给定范围内的节点的数量。 |
| ZRANGE | 从表头向表尾遍历压缩列表, 返回给定索引范围内的所有元素。 | 从表头向表尾遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZREVRANGE | 从表尾向表头遍历压缩列表, 返回给定索引范围内的所有元素。 | 从表尾向表头遍历跳跃表, 返回给定索引范围内的所有元素。 |
| ZRANK | 从表头向表尾遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 | 从表头向表尾遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREVRANK | 从表尾向表头遍历压缩列表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 | 从表尾向表头遍历跳跃表, 查找给定的成员, 沿途记录经过节点的数量, 当找到给定成员之后, 途经节点的数量就是该成员所对应元素的排名。 |
| ZREM | 遍历压缩列表, 删除所有包含给定成员的节点, 以及被删除成员节点旁边的分值节点。 | 遍历跳跃表, 删除所有包含了给定成员的跳跃表节点。 并在字典中解除被删除元素的成员和分值的关联。 |
| ZSCORE | 遍历压缩列表, 查找包含了给定成员的节点, 然后取出成员节点旁边的分值节点保存的元素分值。 | 直接从字典中取出给定成员的分值。 |
编码的区别,api完全一致
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
| 命令 | ziplist 编码的实现方法 |
linkedlist 编码的实现方法 |
|---|---|---|
| LPUSH | 调用 ziplistPush 函数, 将新元素推入到压缩列表的表头。 |
调用 listAddNodeHead 函数, 将新元素推入到双端链表的表头。 |
| RPUSH | 调用 ziplistPush 函数, 将新元素推入到压缩列表的表尾。 |
调用 listAddNodeTail 函数, 将新元素推入到双端链表的表尾。 |
| LPOP | 调用 ziplistIndex 函数定位压缩列表的表头节点, 在向用户返回节点所保存的元素之后, 调用 ziplistDelete 函数删除表头节点。 |
调用 listFirst 函数定位双端链表的表头节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表头节点。 |
| RPOP | 调用 ziplistIndex 函数定位压缩列表的表尾节点, 在向用户返回节点所保存的元素之后, 调用 ziplistDelete 函数删除表尾节点。 |
调用 listLast 函数定位双端链表的表尾节点, 在向用户返回节点所保存的元素之后, 调用 listDelNode 函数删除表尾节点。 |
| LINDEX | 调用 ziplistIndex 函数定位压缩列表中的指定节点, 然后返回节点所保存的元素。 |
调用 listIndex 函数定位双端链表中的指定节点, 然后返回节点所保存的元素。 |
| LLEN | 调用 ziplistLen 函数返回压缩列表的长度。 |
调用 listLength 函数返回双端链表的长度。 |
| LINSERT | 插入新节点到压缩列表的表头或者表尾时, 使用 ziplistPush 函数; 插入新节点到压缩列表的其他位置时, 使用 ziplistInsert 函数。 |
调用 listInsertNode 函数, 将新节点插入到双端链表的指定位置。 |
| LREM | 遍历压缩列表节点, 并调用 ziplistDelete 函数删除包含了给定元素的节点。 |
遍历双端链表节点, 并调用 listDelNode 函数删除包含了给定元素的节点。 |
| LTRIM | 调用 ziplistDeleteRange 函数, 删除压缩列表中所有不在指定索引范围内的节点。 |
遍历双端链表节点, 并调用 listDelNode 函数删除链表中所有不在指定索引范围内的节点。 |
| LSET | 调用 ziplistDelete 函数, 先删除压缩列表指定索引上的现有节点, 然后调用 ziplistInsert 函数, 将一个包含给定元素的新节点插入到相同索引上面。 |
调用 listIndex 函数, 定位到双端链表指定索引上的节点, 然后通过赋值操作更新节点的值。 |
string
| 命令 | int 编码的实现方法 |
embstr 编码的实现方法 |
raw 编码的实现方法 |
|---|---|---|---|
| SET | 使用 int 编码保存值。 |
使用 embstr 编码保存值。 |
使用 raw 编码保存值。 |
| GET | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后向客户端返回这个字符串值。 | 直接向客户端返回字符串值。 | 直接向客户端返回字符串值。 |
| APPEND | 将对象转换成 raw 编码, 然后按 raw编码的方式执行此操作。 |
将对象转换成 raw 编码, 然后按 raw编码的方式执行此操作。 |
调用 sdscatlen 函数, 将给定字符串追加到现有字符串的末尾。 |
| INCRBYFLOAT | 取出整数值并将其转换成 longdouble 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 |
取出字符串值并尝试将其转换成long double 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 |
取出字符串值并尝试将其转换成 longdouble 类型的浮点数, 对这个浮点数进行加法计算, 然后将得出的浮点数结果保存起来。 如果字符串值不能被转换成浮点数, 那么向客户端返回一个错误。 |
| INCRBY | 对整数值进行加法计算, 得出的计算结果会作为整数被保存起来。 | embstr 编码不能执行此命令, 向客户端返回一个错误。 |
raw 编码不能执行此命令, 向客户端返回一个错误。 |
| DECRBY | 对整数值进行减法计算, 得出的计算结果会作为整数被保存起来。 | embstr 编码不能执行此命令, 向客户端返回一个错误。 |
raw 编码不能执行此命令, 向客户端返回一个错误。 |
| STRLEN | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 计算并返回这个字符串值的长度。 | 调用 sdslen 函数, 返回字符串的长度。 |
调用 sdslen 函数, 返回字符串的长度。 |
| SETRANGE | 将对象转换成 raw 编码, 然后按 raw编码的方式执行此命令。 |
将对象转换成 raw 编码, 然后按 raw编码的方式执行此命令。 |
将字符串特定索引上的值设置为给定的字符。 |
| GETRANGE | 拷贝对象所保存的整数值, 将这个拷贝转换成字符串值, 然后取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 |
time zone set的意思。初始化全局的时间记录
如果前面有setenv设置了timezone setenv("TZ", "GMT-8", 1);,这里就会更新。
主要更新
| 全局变量 | 说明 | 缺省值 |
|---|---|---|
| __daylight | 如果在TZ设置中指定夏令时时区 | 1则为非0值;否则为0 |
| __timezone | UTC和本地时间之间的时差,单位为秒 | 28800(28800秒等于8小时) |
| __tzname[0] | TZ环境变量的时区名称的字符串值 | 如果TZ未设置则为空 PST |
| __tzname[1] | 夏令时时区的字符串值; | 如果TZ环境变量中忽略夏令时时区则为空PDT在上表中daylight和tzname数组的缺省值对应于”PST8PDT |
在glibc中代码 time/tzset.c
void
__tzset (void)
{
__libc_lock_lock (tzset_lock);
tzset_internal (1);
if (!__use_tzfile)// 注意这里没有设置过TZ就不会进来。
{
/* Set `tzname'. */
__tzname[0] = (char *) tz_rules[0].name;
__tzname[1] = (char *) tz_rules[1].name;
}
__libc_lock_unlock (tzset_lock);
}
实现在tzset_internal中
static void
tzset_internal (int always)
{
static int is_initialized;
const char *tz;
if (is_initialized && !always)//tzset只会执行一次,初始化过就不会再执行
return;
is_initialized = 1;
/* Examine the TZ environment variable. */
tz = getenv ("TZ");
if (tz && *tz == '\0')
/* User specified the empty string; use UTC explicitly. */
tz = "Universal";
// 处理tz 字符串,过滤掉:...
// 检查tz字符串是不是和上次相同,相同就直接返回...
// 新的tz是NULL 就设定成默认的TZDEFAULT "/etc/localtime"...
//保存到old_tz...
// 去读tzfile ,获取daylight和timezone 这里十分繁琐,也有几处好玩的
// 1. 打开文件校验是硬编码的,We must not allow to read an arbitrary file in a `setuid` program
// 2. FD_CLOSEXEC
/* Note the file is opened with cancellation in the I/O functions
disabled and if available FD_CLOEXEC set. */
//f = fopen (file, "rce"); 具体解释看api文档
//这个mode参数是glibc扩展https://www.gnu.org/software/libc/manual/html_node/Opening-Streams.html
__tzfile_read (tz, 0, NULL);
//后续是没读到文件的默认复制动作...
}
getRandomHexChars -> getRandomBytes
生成随机数直接用
FILE *fp = fopen("/dev/urandom","r");
if (fp == NULL || fread(seed,sizeof(seed),1,fp) != 1){
/* Revert to a weaker seed, and in this case reseed again
* at every call.*/
for (unsigned int j = 0; j < sizeof(seed); j++) {
struct timeval tv;
gettimeofday(&tv,NULL);
pid_t pid = getpid();
seed[j] = tv.tv_sec ^ tv.tv_usec ^ pid ^ (long)fp;
}
}
保证安全,如果失败就先用时间戳和pid生成一个,但是还是不安全,还是会用fopen重新生成
有个局部静态counter ,每次hash都不一样
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
基本上看字段名字就明白啥意思了。就是指针。实现多态用的。
redis所有对外呈现的数据类型,都是dict对象来保存。这个dictType就是用来实例化各个类型对象,具体的类型在通过这个类型对象来初始化。举例,redisdb有个expire,这个dict是用来存有设定过期时间的key,
expire= dictCreate(&expireDictType,NULL);
这样就绑定了类型,内部构造析构都用同一个函数指针就行了。
要让dict发挥多态的效果,就要增加一个类型字段,也就是dictType,通过绑定指针来实现,这就相当于元数据。或者说c++中的构造语义,编译器帮你搞or你自己手动搞,手动搞就要自己设计字段搞定
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
说到这,不如考虑一下hashtable的实现
void _serverPanic(const char *file, int line, const char *msg, ...) {
...log...
#ifdef HAVE_BACKTRACE
serverLog(LL_WARNING,"(forcing SIGSEGV in order to print the stack trace)");
#endif
serverLog(LL_WARNING,"------------------------------------------------");
*((char*)-1) = 'x';
}
指针访问-1 故意段错误,这里也有讨论
int linuxOvercommitMemoryValue(void) {
FILE *fp = fopen("/proc/sys/vm/overcommit_memory","r");
char buf[64];
if (!fp) return -1;
if (fgets(buf,64,fp) == NULL) {
fclose(fp);
return -1;
}
fclose(fp);
return atoi(buf);
}
关于这个参数,见http://linuxperf.com/?p=102
如果/proc/sys/vm/overcommit_memory被设置为0,并且配置了rdb重新功能,如果内存不足,则frok的时候会失败,如果在往redis中塞数据, 会失败,打印 MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk 如果/proc/sys/vm/overcommit_memory被设置为1,则不管内存够不够都会fork失败,这样会引发OOM,最终redis实例会被杀掉。
if ((flags = fcntl(fd, F_GETFL)) == -1)
if (fcntl(fd, F_SETFL, flags | O_NONBLOCK) == -1)
就是这个
::fcntl(sock, F_SETFL, O_NONBLOCK | O_RDWR);
/* Return the UNIX time in microseconds */
long long ustime(void) {
struct timeval tv;
long long ust;
gettimeofday(&tv, NULL);
ust = ((long long)tv.tv_sec)*1000000;
ust += tv.tv_usec;
return ust;
}
/* Return the UNIX time in milliseconds */
mstime_t mstime(void) {
return ustime()/1000;
}
写了个c++里类似的
#include <chrono>
auto [] (){ return std::chrono::duration_cast<std::chrono::microseconds>(
std::chrono::system_clock::now().time_since_epoch()).count();
};
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
一个对象就24字节了。注意type和encoding,就是redis数据结构和实际内部编码,构造也是先type对象->encoding对象初始化,析构也是判断type,判断encoding,然后删encoding对象删type对象。c++就是把这个流程隐藏了。
这个结构就比较复杂了。思考:阻塞命令是怎么阻塞的,为什么影响不到服务端 ->转移到客户端头上了。
阻塞的pop命令,每个客户端都会存个字典,blocking_keys 记录阻塞的key- >客户端链表
如果有push变化,就会遍历一遍找到,然后发送命令,解除阻塞,将这个key放到ready_keys链表中。
还有很多命令的细节放到命令里面讲比较合适。
client还有很多数据结构 看上去很轻巧,复杂的很。
ae.c,networking这几个文件把epoll 和select kqueue封了一起。用法没差别。epoll用的是LT模式。
仔细顺了一遍ET,LT,感觉这个用法有点像ET,没有修改事件, 仔细发现在add/delevent里。。
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}
static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int delmask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
int mask = eventLoop->events[fd].mask & (~delmask);
ee.events = 0;
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (mask != AE_NONE) {
epoll_ctl(state->epfd,EPOLL_CTL_MOD,fd,&ee);
} else {
/* Note, Kernel < 2.6.9 requires a non null event pointer even for
* EPOLL_CTL_DEL. */
epoll_ctl(state->epfd,EPOLL_CTL_DEL,fd,&ee);
}
}
操作客户端的fd
epoll LT ET 主要区别在于LT针对EPOLLOUT事件的处理,
首先EPOLLOUT, 缓冲区可写 调用异步写 → 写满了,EAGAIN→继续等EPOLLOUT事件,这时需要在addevent中修改,加上(MOD)EPOLLOUT事件(可写)
如果没写满,结束了,修改fd,去掉EPOLLOUT事件 ,这时在delevent中删掉(OR 屏蔽掉,MOD),不然这个EPOLLOUT事件会一直触发,就得加屏蔽措施
在比如写一个echo server,或者长连接传文件 ,针对EPOLLOUT事件,写不完,就得手动epoll_ctl MOD一下,暂时屏蔽掉EPOLLOUT事件,然后如果又有了EPOLLOUT事件需要添加就在家上。针对fd得改来改去。如果是ET就没有这么麻烦设定好就行了,要么使劲读到缓冲区读完, or使劲写到缓冲区写满,事件处理完毕,等下一次事件就行。
ET LT是电子信息 信号处理的概念,触发是电平(一直触发)还是毛刺(触发一次),如果用ET,当前框架会不会丢消息?
看了一天epoll 脑袋快炸了
注意新的版本,回复事件全部放在beforeSleep中注册了,上面的分析是3.0版本。
定时任务,处理客户端相关
| 策略 | 说明 |
|---|---|
| volatile-lru | 从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰 |
| volatile-ttl | 从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰 |
| allkeys-lru | 从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰 |
| allkeys-random | 从数据集(server.db[i].dict)中任意选择数据淘汰 |
| no-enviction(驱逐) | 禁止驱逐数据 |
server.maxmemory这个字段用来判断,这个字段有没有推荐设定值?
前期处理,各种条件限制,提前返回。标记上下文涉及到的flag,处理正常会调用call
所有的命令都走它,通过它来执行具体的命令。processCommand ....-> call -> c->cmd->proc(c)
call针对不同的客户端连接,处理不同的flag
把redis源码注释抄过来了
| 标识 | 意义 |
|---|---|
| w | write command (may modify the key space). |
| r | read command (will never modify the key space). |
| m | may increase memory usage once called. Don’t allow if out of memory. |
| a | admin command, like SAVE or SHUTDOWN. |
| p | Pub/Sub related command. |
| f | force replication of this command, regardless of server.dirty. |
| s | command not allowed in scripts. |
| R | R: random command. SPOP |
| l | Allow command while loading the database. |
| t | Allow command while a slave has stale data but is not allowed to server this data. Normally no command is accepted in this condition but just a few. |
| S | Sort command output array if called from script, so that the output is deterministic. |
| M | Do not automatically propagate the command on MONITOR. |
| k | Perform an implicit ASKING for this command, so the command will be accepted in cluster mode if the slot is marked as ‘importing’. |
| F | Fast command: O(1) or O(log(N)) command that should never delay its execution as long as the kernel scheduler is giving us time. Note that commands that may trigger a DEL as a side effect (like SET) are not fast commands. |
初始化server参数
有几个有意思的点:
cachedtime 保存一份时间,优化,因为很多对象用这个,就存一份,比直接调用time要快
server.tcp_backlog设置成了521.
默认的客户端连接空闲时间是0,无限
tcpkeepalive设置成了300
…参数太多
server.commands 用hashtable存了起来,在一开始已经用数组存好了。
检查backlog FILE *fp = fopen(“/proc/sys/net/core/somaxconn”,”r”);
daemonize 不说了,很常见的操作,fork +exit父进程退出,setsid 改权限,重定向标准fd,打开垃圾桶open(“/dev/null”, O_RDWR)
initServer 忽略SIGHUP SIGPIPE,SIGPIPE比较常见
下面就是listen和处理socket ipc了。
然后是各种初始化,LRU初始化
调整打开文件大小,如果小,就设置成1024
一个定时任务,每秒执行server.hz次
里面有run_with_period宏,相当于除,降低次数
整体交互流程


获取客户端参数,如端口、ip地址、dbnum、socket等
根据用户指定参数确定客户端处于哪种模式
进入redisContextInit方法,redisContextInit方法用于创建一个Context结构体保存在内存中,主要用于保存客户端的一些东西,最重要的就是 write buffer和redisReader,write buffer 用于保存客户端的写入,redisReader用于保存协议解析器的一些状态。

至此客户端和服务器端的socket连接已经建立,但是此时服务器端还继续做了2件事:

服务器端依然在进行事件循环,在客户端发来内容的时候触发,对应的文件读取事件。这就是之前创建socket连接的时候建立的事件,该事件绑定的方法是readQueryFromClient 。
在readQueryFromClient方法中从服务器端套接字描述符中读取客户端的内容到服务器端初始化client的查询缓冲中,主要方法如下:
交给processInputBuffer处理,processInputBuffer 主要包含两个方法,processInlineBuffer和processCommand。processInlineBuffer方法用于采用redis协议解析客户端内容并生成对应的命令并传给processCommand 方法,processCommand方法则用于执行该命令
最后进入call方法, 决定调用具体的命令
setCommand方法,setCommand方法会调用setGenericCommand方法,该方法首先会判断该key是否已经过期,最后调用setKey方法。
这里需要说明一点的是,通过以上的分析。redis的key过期包括主动检测以及被动监测
进入setKey方法,setKey方法最终会调用dbAdd方法,其实最终就是将该键值对存入服务器端维护的一个字典中,该字典是在服务器初始化的时候创建,用于存储服务器的相关信息,其中包括各种数据类型的键值存储。完成了写入方法时候,此时服务器端会给客户端返回结果。
进入prepareClientToWrite方法然后通过调用_addReplyToBuffer方法将返回结果写入到outbuf中(客户端连接时创建的client)

/* Check that server.tcp_backlog can be actually enforced in Linux according to the value of /proc/sys/net/core/somaxconn, or warn about it. */
listenToPort 是直接调用net接口了。后面再说吧
/* Convert an amount of bytes into a human readable string in the form
* of 100B, 2G, 100M, 4K, and so forth. */
void bytesToHuman(char *s, unsigned long long n) {
double d;
if (n < 1024) {
/* Bytes */
sprintf(s,"%lluB",n);
} else if (n < (1024*1024)) {
d = (double)n/(1024);
sprintf(s,"%.2fK",d);
} else if (n < (1024LL*1024*1024)) {
d = (double)n/(1024*1024);
sprintf(s,"%.2fM",d);
} else if (n < (1024LL*1024*1024*1024)) {
d = (double)n/(1024LL*1024*1024);
sprintf(s,"%.2fG",d);
} else if (n < (1024LL*1024*1024*1024*1024)) {
d = (double)n/(1024LL*1024*1024*1024);
sprintf(s,"%.2fT",d);
} else if (n < (1024LL*1024*1024*1024*1024*1024)) {
d = (double)n/(1024LL*1024*1024*1024*1024);
sprintf(s,"%.2fP",d);
} else {
/* Let's hope we never need this */
sprintf(s,"%lluB",n);
}
}
rdb文件是内存的一份快照
rdbLoad代码很短
if ((fp = fopen(filename,"r")) == NULL) return C_ERR;
startLoadingFile(fp, filename,rdbflags);
rioInitWithFile(&rdb,fp);//绑定write read flush 等系统api
retval = rdbLoadRio(&rdb,rdbflags,rsi); //正式读
fclose(fp);
stopLoading(retval==C_OK);
rdbLoadRio 处理一些不同类型的数据,像文件头,selectdb号,moduleID等等,处理完之后会进入真正的读string object。kv都帮到一起了,rdb加载就能直接解出来,主要逻辑
//while(1)
if ((key = rdbLoadStringObject(rdb)) == NULL) goto eoferr;
/* Read value */
if ((val = rdbLoadObject(type,rdb,key)) == NULL) {
decrRefCount(key);
goto eoferr;
}
rdbLoadObject解出来每一个object,拿到value。这个函数会根据每种类型来解。如果是list之类的还要在内部继续遍历继续解。代码500行,不抄了
具体的格式见参考链接,我直接抄过来
----------------------------# RDB文件是二进制的,所以并不存在回车换行来分隔一行一行.
52 45 44 49 53 # 以字符串 "REDIS" 开头
30 30 30 33 # RDB 的版本号,大端存储,比如左边这个表示版本号为0003
----------------------------
FE 00 # FE = FE表示数据库编号,Redis支持多个库,以数字编号,这里00表示第0个数据库
----------------------------# Key-Value 对存储开始了
FD $length-encoding # FD 表示过期时间,过期时间是用 length encoding 编码存储的,后面会讲到
$value-type # 1 个字节用于表示value的类型,比如set,hash,list,zset等
$string-encoded-key # Key 值,通过string encoding 编码,同样后面会讲到
$encoded-value # Value值,根据不同的Value类型采用不同的编码方式
----------------------------
FC $length-encoding # FC 表示毫秒级的过期时间,后面的具体时间用length encoding编码存储
$value-type # 同上,也是一个字节的value类型
$string-encoded-key # 同样是以 string encoding 编码的 Key值
$encoded-value # 同样是以对应的数据类型编码的 Value 值
----------------------------
$value-type # 下面是没有过期时间设置的 Key-Value对,为防止冲突,数据类型不会以 FD, FC, FE, FF 开头
$string-encoded-key
$encoded-value
----------------------------
FE $length-encoding # 下一个库开始,库的编号用 length encoding 编码
----------------------------
... # 继续存储这个数据库的 Key-Value 对
FF ## FF:RDB文件结束的标志
第一行就不用讲了,REDIS字符串用于标识是Redis的RDB文件
用了4个字节存储版本号,以大端(big endian)方式存储和读取
以一个字节的0xFE开头,后面存储数据库的具体编号,数据库的编号是一个数字,通过 “Length Encoding” 方式编码存储,“Length Encoding” 我们后面会讲到。
值对包括下面四个部分 1. Key 过期时间,这一项是可有可无的 2. 一个字节表示value的类型 3. Key的值,Key都是字符串,通过 “Redis String Encoding” 来保存 4. Value的值,通过 “Redis Value Encoding” 来根据不同的数据类型做不同的存储
过期时间由 0xFD 或 0xFC开头用于标识,分别表示秒级的过期时间和毫秒级的过期时间,后面的具体时间是一个UNIX时间戳,秒级或毫秒级的。具体时间戳的值通过“Redis Length Encoding” 编码存储。在导入RDB文件的过程中,会通过过期时间判断是否已过期并需要忽略。
Value类型用一个字节进行存储,目前包括以下一些值:
Key值就是简单的 “String Encoding” 编码,具体可以看后面的描述
上面列举了Value的9种类型,实际上可以分为三大类
上面说了很多 Length Encoding ,现在就为大家讲解。可能你会说,长度用一个int存储不就行了吗?但是,通常我们使用到的长度可能都并不大,一个int 4个字节是否有点浪费呢。所以Redis采用了变长编码的方法,将不同大小的数字编码成不同的长度。
这样做有什么好处呢,实际就是节约空间:
Redis的 String Encoding 是二进制安全的,也就是说他没有任何特殊分隔符用于分隔各个值,你可以在里面存储任何东西。它就是一串字节码。 下面是 String Encoding 的三种类型
长度编码字符串是最简单的一种类型,它由两部分组成,一部分是用 “Length Encoding” 编码的字符串长度,第二部分是具体的字节码。
上面说到过 Length Encoding 的特殊编码,就在这里用上了。所以数字替代字符串是以 1 1 开头的,然后读取这个字节剩下的6 位,根据不同的值标识不同的数字类型:
和数据替代字符串一样,它也是以1 1 开头的,然后剩下的6 位如果值为4,那么就表示它是一个压缩字符串。压缩字符串解析规则如下:
Redis List 结构在RDB文件中的存储,是依次存储List中的各个元素的。其结构如下:
Set结构和List结构一样,也是依次存储各个元素的
也是和list类似的,注意double有两种保存方法,做了优化,所以读取也要做区分
注意这个整理,现在6.0版本是不准的,多了module和stream。
其中stream的处理方法是类似的,也是遍历
rdbSaveRio逐个保存,所有的kv对都变成string
核心逻辑
for(all db)
for(each type)
rdbSaveKeyValuePair()
rdb文件整体都是大端的。这也算方便跨平台吧
6.0带来的一大改动就是多线程IO了。
多线程IO读。提高并发。核心代码
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
核心代码没什么好说的
nread = connRead(c->conn, c->querybuf+qblen, readlen);
if (nread == -1) {
if (connGetState(conn) == CONN_STATE_CONNECTED) {
return;
} else {
serverLog(LL_VERBOSE, "Reading from client: %s",connGetLastError(c->conn));
freeClientAsync(c);
return;
}
} else if (nread == 0) {
serverLog(LL_VERBOSE, "Client closed connection");
freeClientAsync(c);
return;
} else if (c->flags & CLIENT_MASTER) {
/* Append the query buffer to the pending (not applied) buffer
* of the master. We'll use this buffer later in order to have a
* copy of the string applied by the last command executed. */
c->pending_querybuf = sdscatlen(c->pending_querybuf,
c->querybuf+qblen,nread);
}
这里读完,后面是processInputBufferAndReplicate->processInputBuffer 解析完命令等执行
从客户链接读数据,几个优化点
各种accept略过
各种buffer处理总入口,processInputBuffer的一层封装
redis支持两种协议,redis protocol,或者inline,按行读
processInputBuffer在检查各种flag之后,根据字符串开头是不是array来判断是processMultibulkBuffer还是processInlineBuffer
Client相关的帮助函数这里省略
整体架构
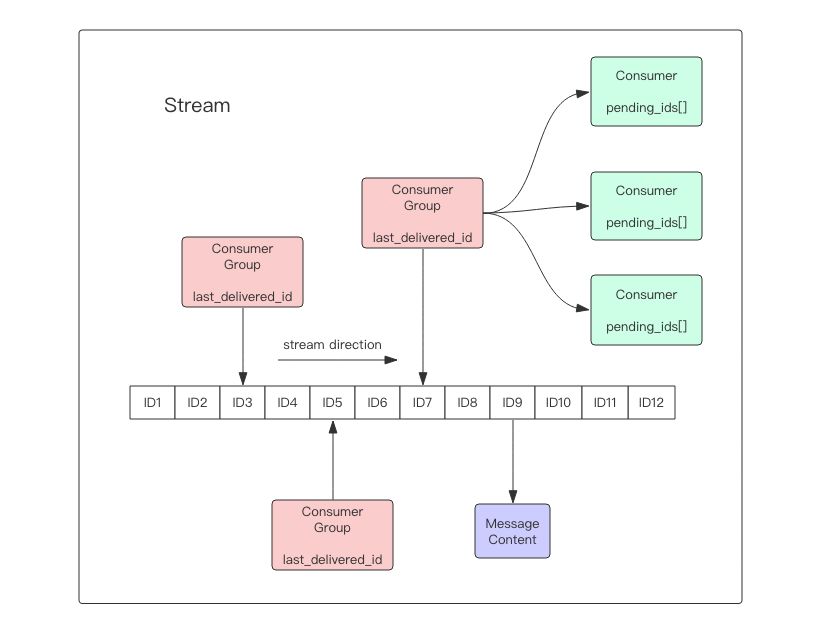
每个Stream都有唯一的名称,Redis key
每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者者有一个组内唯一名称。
pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。简单说
stream key 每条消息存储并生成streamid-seq,然后id和消费组挂钩,消费组内部有游标和消费者,消费者和消费组挂钩。是串行消费游标信息。
如果把stream编码成kv需要怎么做?
首先,stream key本身维护一组信息,需要知道最后一个streamid,需要知道stream个数,本身就算是一个元数据
其次,stream key需要和子字段,streamid编码,方便区分是谁的key的streamID下的字段
消费组,这也算是一个元数据,需要保存最后一个消费到的id,为了快速定位消费组,可以保存到stream key的value里。
然后就是消费者了,这个就是PEL,消费者应该没有必要单独存一个表 。
最近一周做一个第三方c++库糊c wrapper的工作,干的太慢了,一周啊没搞定。我原本的计划是打算这一周就把这个活搞定,结果连10%都没做完。高估自己能力了。
前两天主要是搞定原来的库,去掉对其他库的依赖(锁用的还是pthread api,我给去掉了),剩下的时间,思考怎么把cpp导出c接口。。这也太闹心了。学习了一下rocksdb导出的实现。
类的字段全都要导出接口,天哪。
首先说下我个人的暴力替换法
std::vector<T> 改成 T*
std::vector<std::string>(&) 直接改成 char**
std::vector<std::string>* 直接变成char *** 感觉已经招架不住了
返回指针还是传入指针or传入buffer指针?buffer指针咋设置合适,or 传入指针在内部分配?不如直接返回指针
返回的话管理内存就得交给调用方?
Rocksdb做法
char* rocksdb_get(
rocksdb_t* db,
const rocksdb_readoptions_t* options,
const char* key, size_t keylen,
size_t* vallen,
char** errptr) {
char* result = nullptr;
std::string tmp;
Status s = db->rep->Get(options->rep, Slice(key, keylen), &tmp);
if (s.ok()) {
*vallen = tmp.size();
result = CopyString(tmp);
} else {
*vallen = 0;
if (!s.IsNotFound()) {
SaveError(errptr, s);
}
}
return result;
}
返回指针,传入长度,这只是一个kv,如果是多个呢,如果是复杂的数据结构呢?
Rocksdb 是怎么把错误导出的。传入错误指针,saveerror
static bool SaveError(char** errptr, const Status& s) {
assert(errptr != nullptr);
if (s.ok()) {
return false;
} else if (*errptr == nullptr) {
*errptr = strdup(s.ToString().c_str());
} else {
// This is a bug if *errptr is not created by malloc()
free(*errptr);
*errptr = strdup(s.ToString().c_str());
}
return true;
}
char* err = NULL; 传入&err (为啥二级指针?) err本身是个字符串,传字符串地址。
gcc编译c程序,链接c++的静态库,需要-lstdc++,不然会有连接错误。或者用g++编译,默认带stdc++ runtime
其实这背后有更恶心的问题,如果你链接一个静态库,这个静态库依赖其他静态库,这里头的依赖关系就很恶心了。
最近看pika,主程序依赖rocksdb和blackwidow,blackwidow也依赖rocksdb,链接都是静态。就很混乱。
一个示例
[root@host]# tree
|-- libp.so
|-- libstaticp.a
|-- p.cpp
|-- p.h
|-- p.o
|-- p_test.c
|-- ptest_d
`-- ptest_s
p.cpp
#include "p.h"
#include <iostream>
using namespace std;
extern "C"{
void print_int(int a){
cout<<a<<endl;
}
}
p.h
#ifndef _P_
#define _P_
#ifdef __cplusplus
extern "C" {
#endif
void print_int(int a);
#ifdef __cplusplus
}
#endif
#endif
p_test.c
#include "p.h"
int main(){
print_int(111);
return 0;
}
export LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH
g++ p.cpp -fPIC -shared -o libp.so
g++ -c p.cpp
ar cqs libstaticp.a p.o
gcc -o ptest_d p_test.c -L. -lp #ok
g++ -o ptest_s p_test.c -L. -lstaticp #ok
gcc -o ptest_s p_test.c -L. -lstaticp -lstdc++ #ok
gcc -o ptest_s p_test.c -L. -lstaticp #not ok
./libstaticp.a(p.o): In function `print_int':
p.cpp:(.text+0x11): undefined reference to `std::cout'
p.cpp:(.text+0x16): undefined reference to `std::ostream::operator<<(int)'
p.cpp:(.text+0x1b): undefined reference to `std::basic_ostream<char, std::char_traits<char> >& std::endl<char, std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&)'
p.cpp:(.text+0x23): undefined reference to `std::ostream::operator<<(std::ostream& (*)(std::ostream&))'
./libstaticp.a(p.o): In function `__static_initialization_and_destruction_0(int, int)':
p.cpp:(.text+0x4c): undefined reference to `std::ios_base::Init::Init()'
p.cpp:(.text+0x5b): undefined reference to `std::ios_base::Init::~Init()'
collect2: error: ld returned 1 exit status
摘自深入理解Nginx 第一章
由于默认的Linux内核参数考虑的是最通用的场景,这明显不符合用于支持高并发访问 的Web服务器的定义,所以需要修改Linux内核参数,使得Nginx可以拥有更高的性能。 在优化内核时,可以做的事情很多,不过,我们通常会根据业务特点来进行调整,当 Nginx作为静态Web内容服务器、反向代理服务器或是提供图片缩略图功能(实时压缩图片) 的服务器时,其内核参数的调整都是不同的。这里只针对最通用的、使Nginx支持更多并发 请求的TCP网络参数做简单说明。 首先,需要修改/etc/sysctl.conf来更改内核参数。例如,最常用的配置:
fs.file-max = 999999
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.ip_local_port_range = 1024 61000
net.ipv4.tcp_rmem = 4096 32768 262142
net.ipv4.tcp_wmem = 4096 32768 262142
net.core.netdev_max_backlog = 8096
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 2097152
net.core.wmem_max = 2097152
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn.backlog=1024
然后执行sysctl-p命令,使上述修改生效。 上面的参数意义解释如下:
最近
int sizeofint(int x) {
const static int table[] = { 9, 99, 999, 9999, 99999, 999999, 9999999,
99999999, 999999999, std::numeric_limits<int>::max()};
for (int i = 0; i<10; i++)
if (x <= table[i])
return i + 1;
}
std::vector<std::string> split(const std::string& s, char delimiter)
{
std::vector<std::string> tokens;
std::string token;
std::istringstream tokenStream(s);
while (std::getline(tokenStream, token, delimiter))
{
tokens.push_back(token);
}
return tokens;
}
判断标点符号 std::ispunct,一可以自己写个数组暴力查表
Range for循环判定结尾, 这种写法注意可能vector有重复导致判断错误
for (auto v : vec) {
if (v != vec.back()) {//...}
}