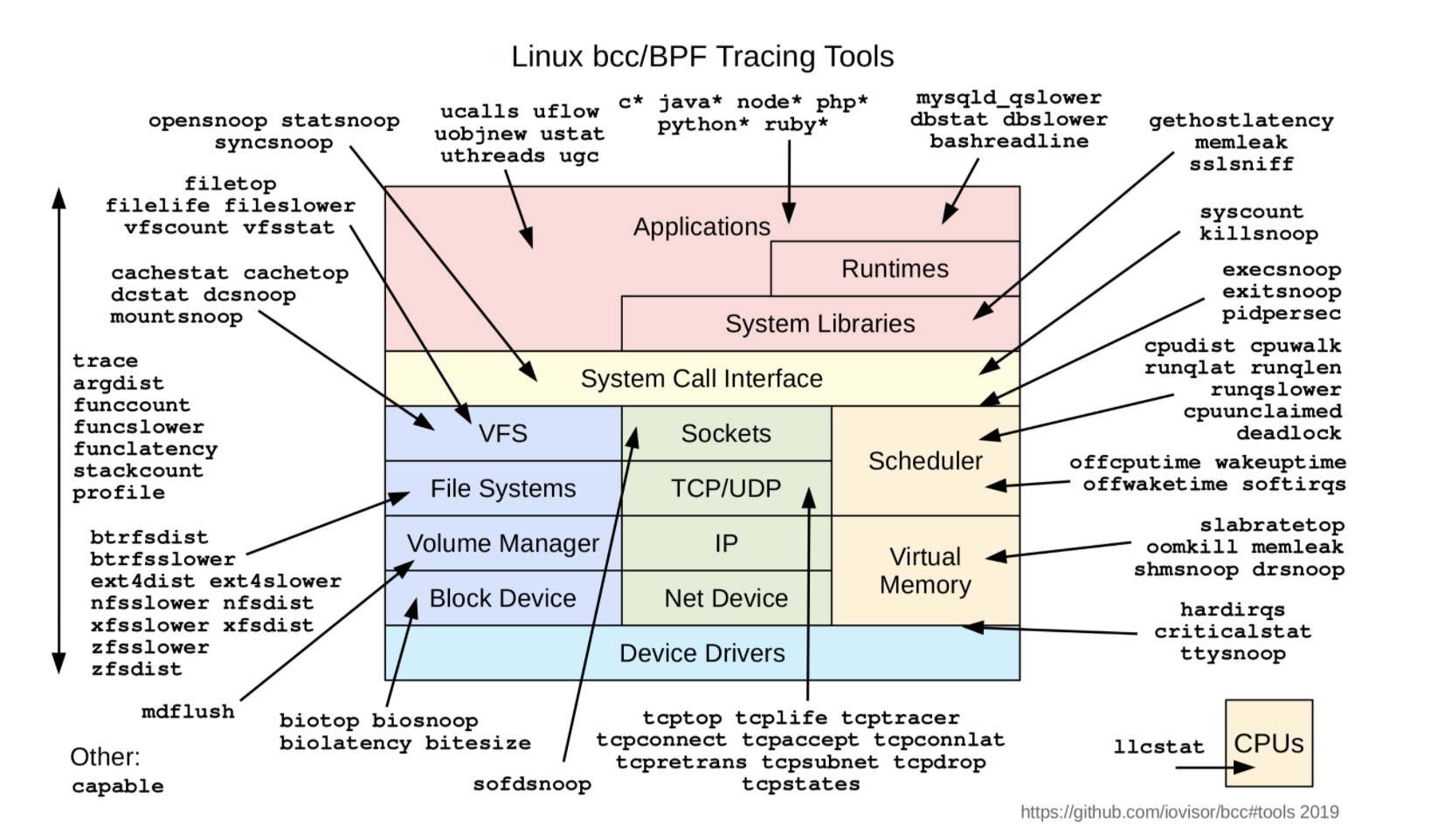
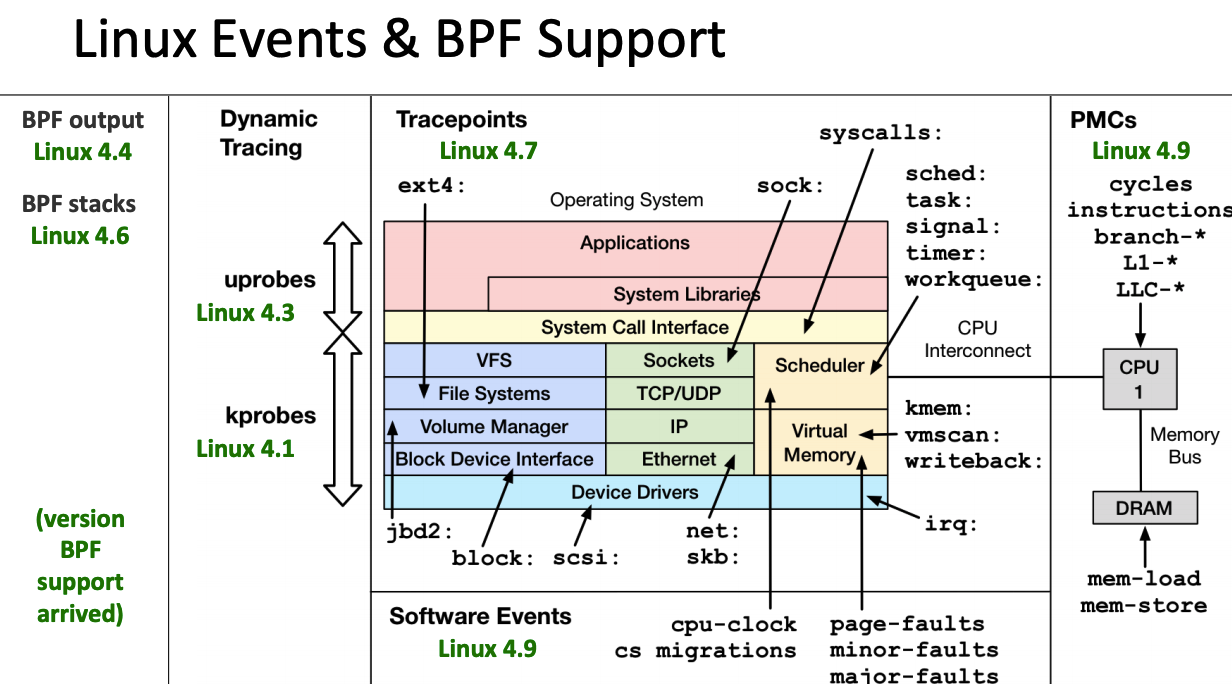
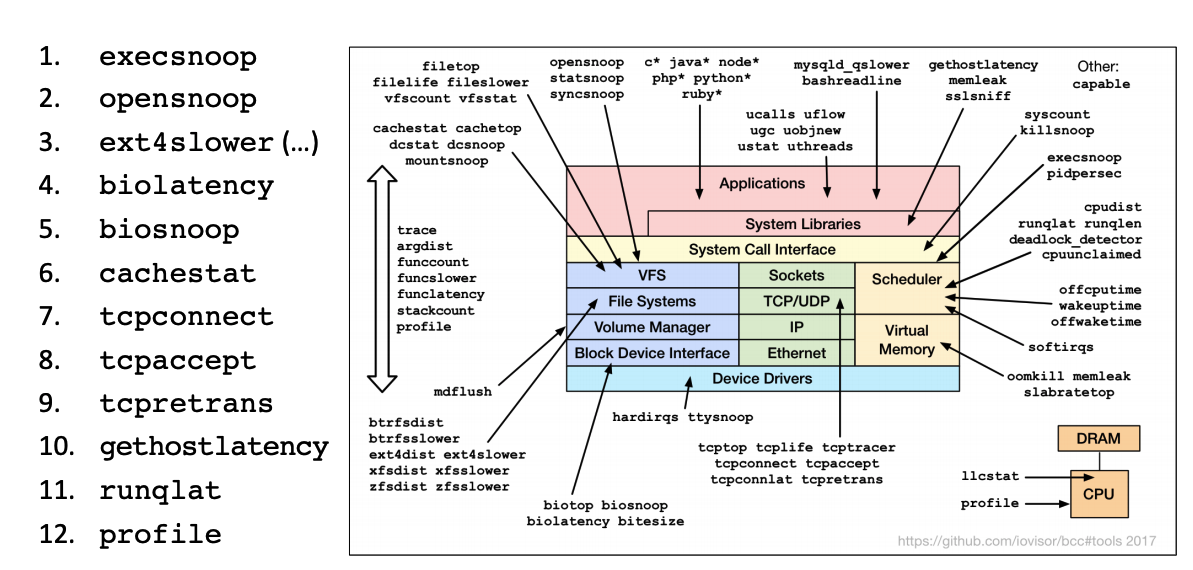
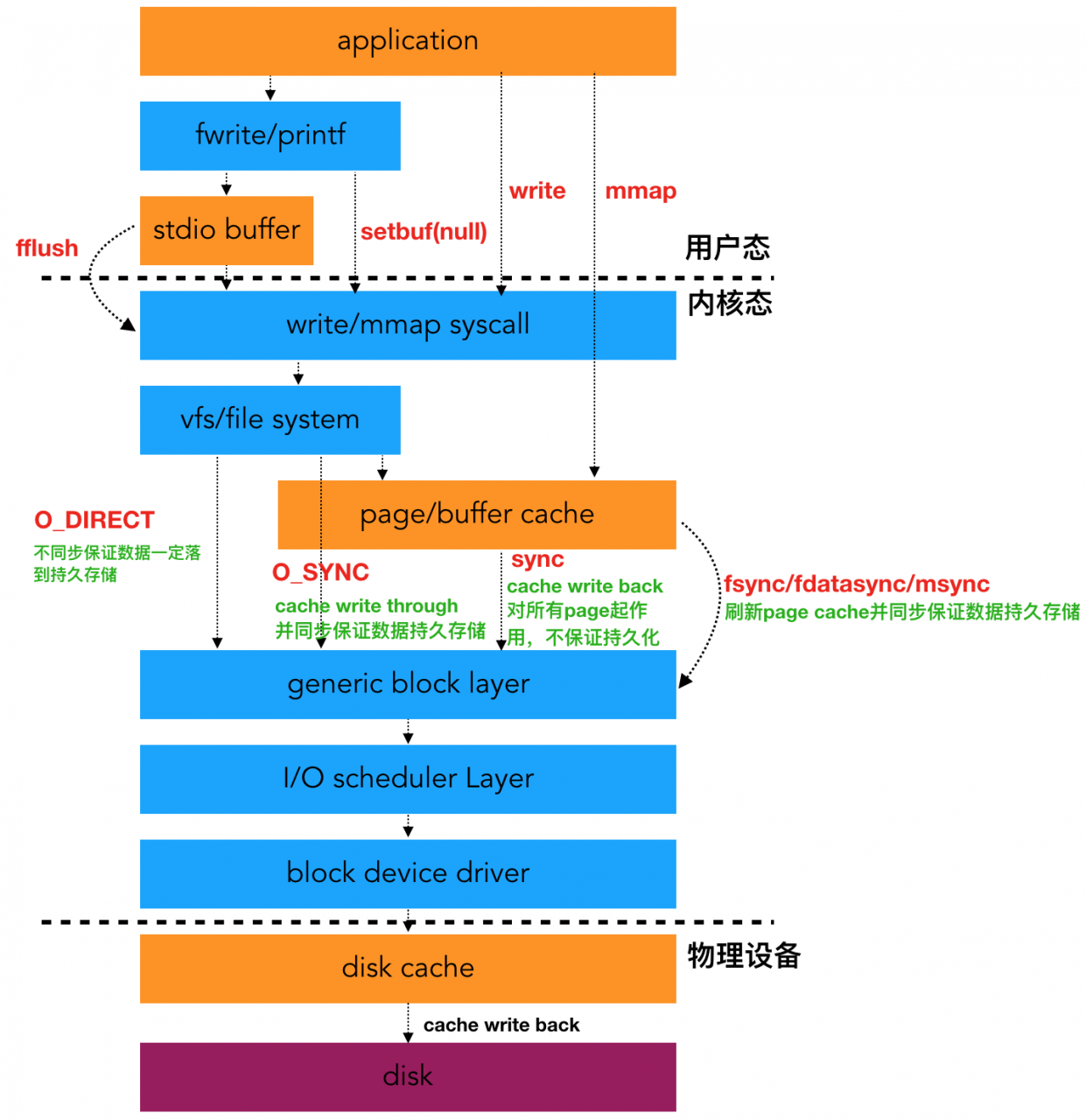
英语原文链接 https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/ 作者:Quentin Monnet
中文翻译 转自 https://linux.cn/article-9507-1.html 感谢 译者:qhwdw 校对:wxy 感谢 Linux中国-LCTT 原创编译!
什么是 BPF?
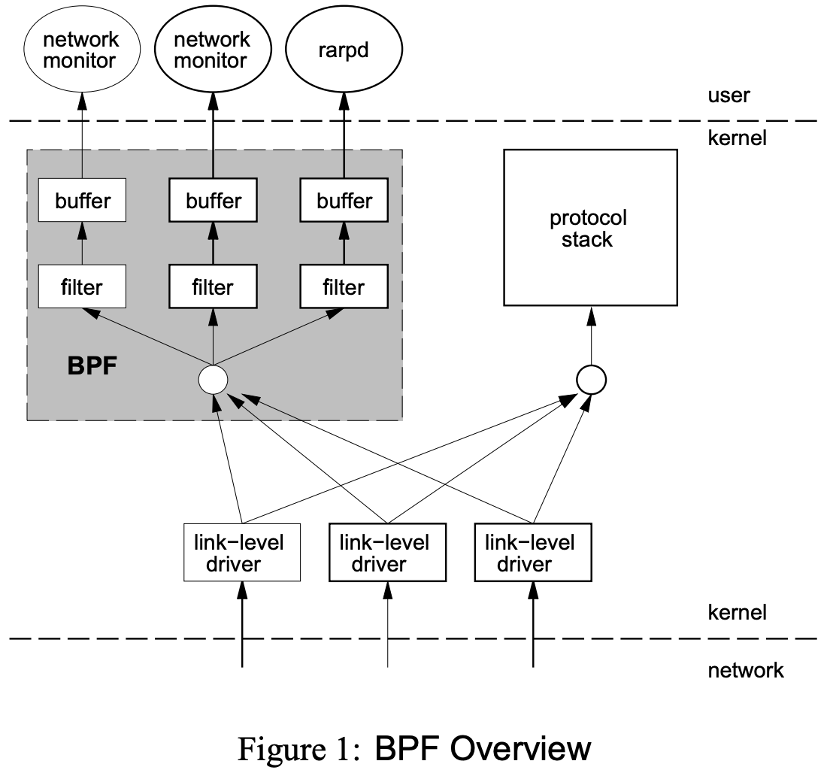
BPF,及伯克利包过滤器,最初构想提出于 1992 年,其目的是为了提供一种过滤包的方法,并且要避免从内核空间到用户空间的无用的数据包复制行为。它最初是由从用户空间注入到内核的一个简单的字节码构成,它在那个位置利用一个校验器进行检查 —— 以避免内核崩溃或者安全问题 —— 并附着到一个套接字上,接着在每个接收到的包上运行。几年后它被移植到 Linux 上,并且应用于一小部分应用程序上(例如,tcpdump)。其简化的语言以及存在于内核中的即时编译器(JIT),使 BPF 成为一个性能卓越的工具。
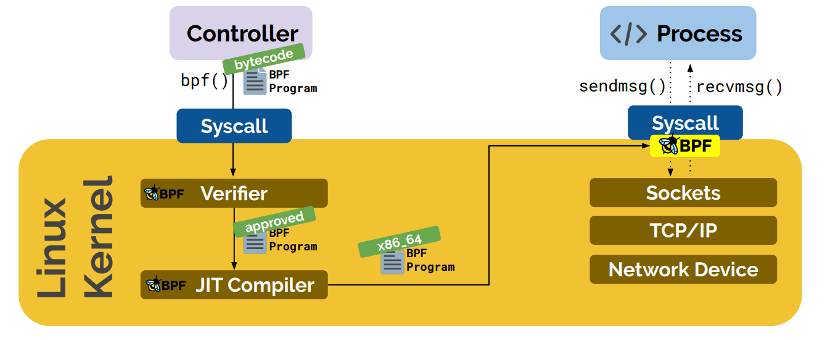
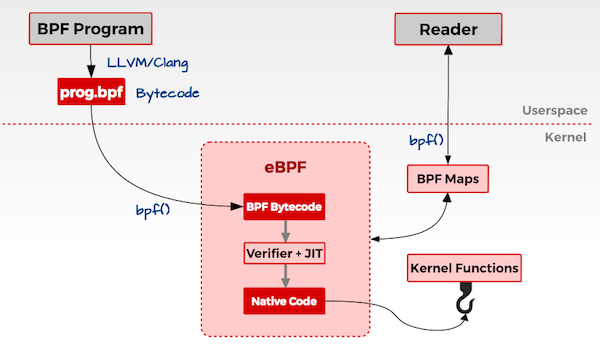
然后,在 2013 年,Alexei Starovoitov 对 BPF 进行彻底地改造,并增加了新的功能,改善了它的性能。这个新版本被命名为 eBPF (意思是 “extended BPF”),与此同时,将以前的 BPF 变成 cBPF(意思是 “classic” BPF)。新版本出现了如映射和尾调用这样的新特性,并且 JIT 编译器也被重写了。新的语言比 cBPF 更接近于原生机器语言。并且,在内核中创建了新的附着点。
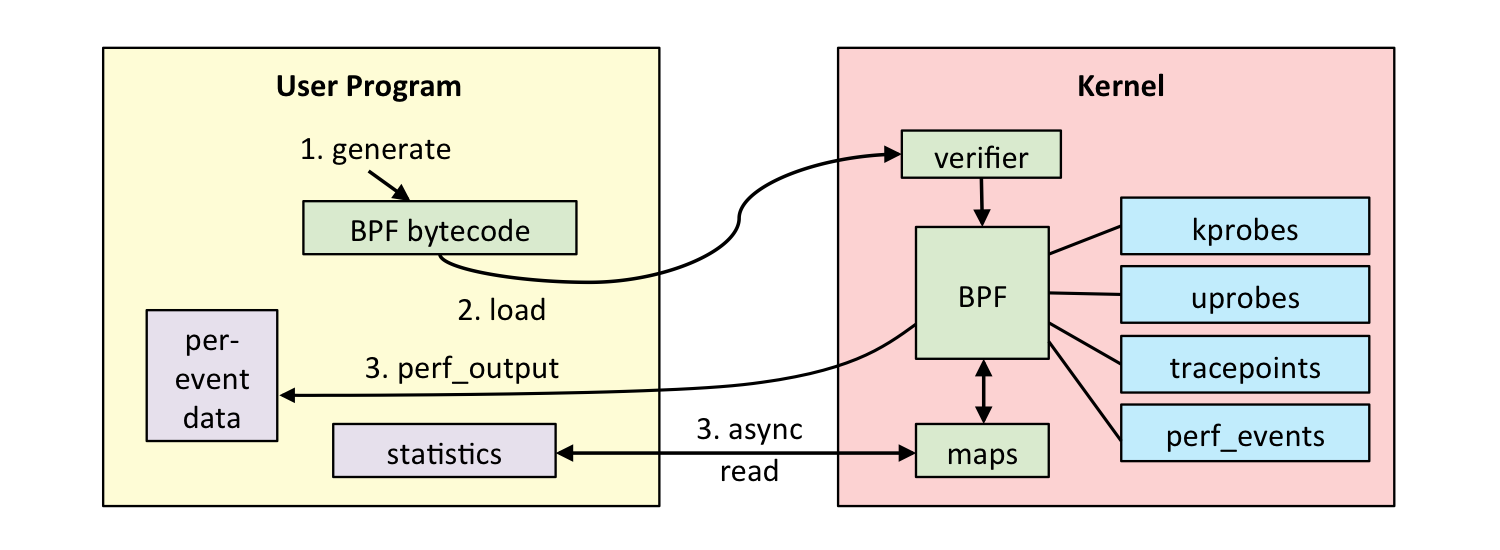
感谢那些新的钩子,eBPF 程序才可以被设计用于各种各样的情形下,其分为两个应用领域。其中一个应用领域是内核跟踪和事件监控。BPF 程序可以被附着到探针(kprobe),而且它与其它跟踪模式相比,有很多的优点(有时也有一些缺点)。
另外一个应用领域是网络编程。除了套接字过滤器外,eBPF 程序还可以附加到 tc(Linux 流量控制工具)的入站或者出站接口上,以一种很高效的方式去执行各种包处理任务。这种使用方式在这个领域开创了一个新的天地。
并且 eBPF 通过使用为 IO Visor 项目开发的技术,使它的性能进一步得到提升:也为 XDP(“eXpress Data Path”)添加了新的钩子,XDP 是不久前添加到内核中的一种新式快速路径。XDP 与 Linux 栈组合,然后使用 BPF ,使包处理的速度更快。
甚至一些项目,如 P4、Open vSwitch,考虑 或者开始去接洽使用 BPF。其它的一些,如 CETH、Cilium,则是完全基于它的。BPF 是如此流行,因此,我们可以预计,不久之后,将围绕它有更多工具和项目出现 …
深入理解字节码
就像我一样:我的一些工作(包括 BEBA)是非常依赖 eBPF 的,并且在这个网站上以后的几篇文章将关注于这个主题。按理说,在深入到细节之前,我应该以某种方式去介绍 BPF —— 我的意思是,真正的介绍,在第一节所提供的简要介绍上更多地介绍在 BPF 上开发的新功能:什么是 BPF 映射?尾调用?内部结构是什么样子?等等。但是,在这个网站上已经有很多这个主题的介绍了,而且,我也不希望去写另一篇 “BPF 介绍” 的重复文章。
毕竟,我花费了很多的时间去阅读和学习关于 BPF 的知识,因此,在这里我们将要做什么呢,我收集了非常多的关于 BPF 的阅读材料:介绍、文档,也有教程或者示例。这里有很多的材料可以去阅读,但是,为了去阅读它,首先要去 找到 它。因此,为了能够帮助更多想去学习和使用 BPF 的人,现在的这篇文章给出了一个资源清单。这里有各种阅读材料,它可以帮你深入理解内核字节码的机制。
资源

简介
这篇文章中下面的链接提供了 BPF 的基本概述,或者,一些与它密切相关的一些主题。如果你对 BPF 非常陌生,你可以在这些介绍文章中挑选出一篇你喜欢的文章去阅读。如果你已经理解了 BPF,你可以针对特定的主题去阅读,下面是阅读清单。
关于 BPF
关于 eBPF 的常规介绍:
-
全面介绍 eBPF(Matt Flemming,on LWN.net,December 2017):
一篇写的很好的,并且易于理解的,介绍 eBPF 子系统组件的概述文章。
-
利用 BPF 和 XDP 实现可编程的内核网络数据路径 (Daniel Borkmann, OSSNA17, Los Angeles, September 2017):
快速理解所有的关于 eBPF 和 XDP 的基础概念的最好讲稿中的一篇(主要是关于网络处理的)
-
BSD 包过滤器 (Suchakra Sharma, June 2017):
一篇非常好的介绍文章,主要是关于跟踪方面的。
-
BPF:跟踪及更多(Brendan Gregg, January 2017):
主要内容是跟踪使用案例相关的。
-
Linux BPF 的超强功能 (Brendan Gregg, March 2016):
第一部分是关于火焰图的使用。
-
IO Visor(Brenden Blanco, SCaLE 14x, January 2016):
介绍了 IO Visor 项目。
-
大型机上的 eBPF(Michael Holzheu, LinuxCon, Dubin, October 2015)
-
在 Linux 上新的(令人激动的)跟踪新产品(Elena Zannoni, LinuxCon, Japan, 2015)
-
BPF — 内核中的虚拟机(Alexei Starovoitov, February 2015):
eBPF 的作者写的一篇讲稿。
-
扩展 extended BPF (Jonathan Corbet, July 2014)
BPF 内部结构:
- Daniel Borkmann 正在做的一项令人称奇的工作,它用于去展现 eBPF 的 内部结构,尤其是,它的关于 随同 tc 使用 的几次演讲和论文。
-
使用 tc 的 cls_bpf 的高级可编程和它的最新更新(netdev 1.2, Tokyo, October 2016):
Daniel 介绍了 eBPF 的细节,及其用于隧道和封装、直接包访问和其它特性。
-
自 netdev 1.1 以来的 cls_bpf/eBPF 更新 (netdev 1.2, Tokyo, October 2016, part of this tc workshop)
-
使用 cls_bpf 实现完全可编程的 tc 分类器 (netdev 1.1, Sevilla, February 2016):
介绍 eBPF 之后,它提供了许多 BPF 内部机制(映射管理、尾调用、校验器)的见解。对于大多数有志于 BPF 的人来说,这是必读的!全文在这里。
-
Linux tc 和 eBPF (fosdem16, Brussels, Belgium, January 2016)
-
eBPF 和 XDP 攻略和最新更新 (fosdem17, Brussels, Belgium, February 2017)
这些介绍可能是理解 eBPF 内部机制设计与实现的最佳文档资源之一。
IO Visor 博客 有一些关于 BPF 的值得关注技术文章。它们中的一些包含了一点营销讨论。
内核跟踪:总结了所有的已有的方法,包括 BPF:
-
邂逅 eBPF 和内核跟踪 (Viller Hsiao, July 2016):
Kprobes、uprobes、ftrace
-
Linux 内核跟踪(Viller Hsiao, July 2016):
Systemtap、Kernelshark、trace-cmd、LTTng、perf-tool、ftrace、hist-trigger、perf、function tracer、tracepoint、kprobe/uprobe …
关于 事件跟踪和监视,Brendan Gregg 大量使用了 eBPF,并且就其使用 eBPFR 的一些案例写了极好的文档。如果你正在做一些内核跟踪方面的工作,你应该去看一下他的关于 eBPF 和火焰图相关的博客文章。其中的大多数都可以 从这篇文章中 访问,或者浏览他的博客。
介绍 BPF,也介绍 Linux 网络的一般概念:
-
Linux 网络详解 (Thomas Graf, LinuxCon, Toronto, August 2016)
-
内核网络攻略 (Thomas Graf, LinuxCon, Seattle, August 2015)
硬件卸载(LCTT 译注:“卸载”是指原本由软件来处理的一些操作交由硬件来完成,以提升吞吐量,降低 CPU 负荷。):
-
eBPF 与 tc 或者 XDP 一起支持硬件卸载,开始于 Linux 内核版本 4.9,是由 Netronome 提出的。这里是关于这个特性的介绍:eBPF/XDP 硬件卸载到 SmartNICs(Jakub Kicinski 和 Nic Viljoen, netdev 1.2, Tokyo, October 2016)
-
一年后出现的更新版:
综合 XDP 卸载——处理边界案例(Jakub Kicinski 和 Nic Viljoen,netdev 2.2 ,Seoul,November 2017)
-
我现在有一个简短的,但是在 2018 年的 FOSDEM 上有一个更新版:
XDP 硬件卸载的挑战(Quentin Monnet,FOSDEM 2018,Brussels,February 2018)
关于 cBPF:
关于 XDP
-
在 IO Visor 网站上的 XDP 概述。
-
eXpress Data Path (XDP) (Tom Herbert, Alexei Starovoitov, March 2016):
这是第一个关于 XDP 的演讲。
-
BoF - BPF 能为你做什么? (Brenden Blanco, LinuxCon, Toronto, August 2016)。
-
eXpress Data Path (Brenden Blanco, Linux Meetup at Santa Clara, July 2016):
包含一些(有点营销的意思?)基准测试结果!使用单一核心:
-
ip 路由丢弃: ~3.6 百万包每秒(Mpps)
-
使用 BPF,tc(使用 clsact qdisc)丢弃: ~4.2 Mpps
-
使用 BPF,XDP 丢弃:20 Mpps (CPU 利用率 < 10%)
-
XDP 重写转发(在端口上它接收到的包):10 Mpps
(测试是用 mlx4 驱动程序执行的)。
-
Jesper Dangaard Brouer 有几个非常好的幻灯片,它可以从本质上去理解 XDP 的内部结构。
-
XDP − eXpress Data Path,介绍及将来的用法 (September 2016):
“Linux 内核与 DPDK 的斗争” 。未来的计划(在写这篇文章时)它用 XDP 和 DPDK 进行比较。
-
网络性能研讨 (netdev 1.2, Tokyo, October 2016):
关于 XDP 内部结构和预期演化的附加提示。
-
XDP – eXpress Data Path, 可用于 DDoS 防护 (OpenSourceDays, March 2017):
包含了关于 XDP 的详细情况和使用案例,以及 性能测试 的 性能测试结果 和 代码片断,以及使用 eBPF/XDP(基于一个 IP 黑名单模式)的用于 基本的 DDoS 防护。
-
内存 vs. 网络,激发和修复内存瓶颈 (LSF Memory Management Summit, March 2017):
提供了许多 XDP 开发者当前所面对 内存问题 的许多细节。不要从这一个开始,但如果你已经理解了 XDP,并且想去了解它在页面分配方面的真实工作方式,这是一个非常有用的资源。
-
XDP 能为其它人做什么(netdev 2.1, Montreal, April 2017),及 Andy Gospodarek:
普通人怎么开始使用 eBPF 和 XDP。这个演讲也由 Julia Evans 在 她的博客 上做了总结。
-
XDP 能为其它人做什么,第二版(netdev 2.2, Seoul, November 2017),同一个作者:
该演讲的修订版本,包含了新的内容。
(Jesper 也创建了并且尝试去扩展了有关 eBPF 和 XDP 的一些文档,查看 相关节。)
-
XDP 研讨 — 介绍、体验和未来发展(Tom Herbert, netdev 1.2, Tokyo, October 2016)
在这篇文章中,只有视频可用,我不知道是否有幻灯片。
-
在 Linux 上进行高速包过滤 (Gilberto Bertin, DEF CON 25, Las Vegas, July 2017)
在 Linux 上的最先进的包过滤的介绍,面向 DDoS 的保护、讨论了关于在内核中进行包处理、内核旁通、XDP 和 eBPF。
关于 基于 eBPF 或者 eBPF 相关的其它组件
-
在边界上的 P4 (John Fastabend, May 2016):
提出了使用 P4,一个包处理的描述语言,使用 BPF 去创建一个高性能的可编程交换机。
-
如果你喜欢音频的演讲,这里有一个相关的 OvS Orbit 片断(#11),叫做 在边界上的 P4,日期是 2016 年 8 月。OvS Orbit 是对 Ben Pfaff 的访谈,它是 Open vSwitch 的其中一个核心维护者。在这个场景中,John Fastabend 是被访谈者。
-
P4, EBPF 和 Linux TC 卸载 (Dinan Gunawardena 和 Jakub Kicinski, August 2016):
另一个 P4 的演讲,一些有关于 Netronome 的 NFP(网络流处理器)架构上的 eBPF 硬件卸载的因素。
- Cilium 是一个由 Cisco 最先发起的技术,它依赖 BPF 和 XDP 去提供 “基于 eBPF 程序即时生成的,用于容器的快速内核强制的网络和安全策略”。这个项目的代码 在 GitHub 上可以访问到。Thomas Graf 对这个主题做了很多的演讲:
在上述不同的演讲中重复了大量的内容;嫌麻烦就选最近的一个。Daniel Borkmann 作为 Google 开源博客的特邀作者,也写了 Cilium 简介。
-
这里也有一个关于 Cilium 的播客节目:一个是 OvS Orbit episode (#4),它是 Ben Pfaff 访谈 Thomas Graf (2016 年 5 月),和 另外一个 Ivan Pepelnjak 的播客,仍然是 Thomas Graf 关于 eBPF、P4、XDP 和 Cilium 方面的(2016 年 10 月)。
-
Open vSwitch (OvS),它是 Open Virtual Network(OVN,一个开源的网络虚拟化解决方案)相关的项目,正在考虑在不同的层次上使用 eBPF,它已经实现了几个概念验证原型:
据我所知,这些 eBPF 的使用案例看上去仅处于提议阶段(并没有合并到 OvS 的主分支中),但是,看它带来了什么将是非常值得关注的事情。
-
XDP 的设计对分布式拒绝访问(DDoS)攻击是非常有用的。越来越多的演讲都关注于它。例如,在 2017 年 4 月加拿大蒙特利尔举办的 netdev 2.1 会议上,来自 Cloudflare 的人们的讲话(XDP 实践:将 XDP 集成到我们的 DDoS 缓解管道)或者来自 Facebook 的(Droplet:由 BPF + XDP 驱动的 DDoS 对策)都存在这样的很多使用案例。
-
Kubernetes 可以用很多种方式与 eBPF 交互。这里有一篇关于 在 Kubernetes 中使用 eBPF 的文章,它解释了现有的产品(Cilium、Weave Scope)如何支持 eBPF 与 Kubernetes 一起工作,并且进一步描述了,在容器部署环境中,eBPF 感兴趣的交互内容是什么。
-
CETH for XDP (Yan Chan 和 Yunsong Lu、Linux Meetup、Santa Clara、July 2016):
CETH,是由 Mellanox 发起的,为实现更快的网络 I/O 而主张的通用以太网驱动程序架构。
-
VALE 交换机,另一个虚拟交换机,它可以与 netmap 框架结合,有 一个 BPF 扩展模块。
-
Suricata,一个开源的入侵检测系统,它的旁路捕获旁特性依赖于 XDP。有一些关于它的资源:
当使用原生驱动的 XDP 时,这个项目要求实现非常高的性能。
-
InKeV:对于 DCN 的内核中分布式网络虚拟化 (Z. Ahmed, M. H. Alizai 和 A. A. Syed, SIGCOMM, August 2016):
InKeV 是一个基于 eBPF 的虚拟网络、目标数据中心网络的数据路径架构。它最初由 PLUMgrid 提出,并且声称相比基于 OvS 的 OpenStack 解决方案可以获得更好的性能。
-
gobpf - 在 Go 中使用 eBPF (Michael Schubert, fosdem17, Brussels, Belgium, February 2017):
“一个来自 Go 库,可以去创建、加载和使用 eBPF 程序”
-
ply 是为 Linux 实现的一个小而灵活的开源动态 跟踪器,它的一些特性非常类似于 bcc 工具,是受 awk 和 dtrace 启发,但使用一个更简单的语言。它是由 Tobias Waldekranz 写的。
- 如果你读过我以前的文章,你可能对我在这篇文章中的讨论感兴趣,使用 eBPF 实现 OpenState 接口,关于包状态处理,在 fosdem17 中。

文档
一旦你对 BPF 是做什么的有一个大体的理解。你可以抛开一般的演讲而深入到文档中了。下面是 BPF 的规范和功能的最全面的文档,按你的需要挑一个开始阅读吧!
关于 BPF
-
BPF 的规范(包含 classic 和 extended 版本)可以在 Linux 内核的文档中,和特定的文件 linux/Documentation/networking/filter.txt 中找到。BPF 使用以及它的内部结构也被记录在那里。此外,当加载 BPF 代码失败时,在这里可以找到 被校验器抛出的错误信息,这有助于你排除不明确的错误信息。
-
此外,在内核树中,在 eBPF 那里有一个关于 常见问答 的文档,它在文件 linux/Documentation/bpf/bpf_design_QA.txt 中。
-
… 但是,内核文档是非常难懂的,并且非常不容易阅读。如果你只是去查找一个简单的 eBPF 语言的描述,可以去 IO Visor 的 GitHub 仓库,那儿有 它的概括性描述。
-
顺便说一下,IO Visor 项目收集了许多 关于 BPF 的资源。大部分分别在 bcc 仓库的 文档目录 中,和 bpf-docs 仓库 的整个内容中,它们都在 GitHub 上。注意,这个非常好的 BPF 参考指南 包含一个详细的 BPF C 和 bcc Python 的 helper 的描述。
-
想深入到 BPF,那里有一些必要的 Linux 手册页。第一个是 bpf(2) man 页面 关于 bpf() 系统调用,它用于从用户空间去管理 BPF 程序和映射。它也包含一个 BPF 高级特性的描述(程序类型、映射等等)。第二个是主要是处理希望附加到 tc 接口的 BPF 程序:它是 tc-bpf(8) man 页面,是 使用 BPF 和 tc 的一个参考,并且包含一些示例命令和参考代码。
-
Jesper Dangaard Brouer 发起了一个 更新 eBPF Linux 文档 的尝试,包含 不同的映射。他有一个草案,欢迎去贡献。一旦完成,这个文档将被合并进 man 页面并且进入到内核文档。
-
Cilium 项目也有一个非常好的 BPF 和 XDP 参考指南,它是由核心的 eBPF 开发者写的,它被证明对于 eBPF 开发者是极其有用的。
-
David Miller 在 xdp-newbies 邮件列表中发了几封关于 eBPF/XDP 内部结构的富有启发性的电子邮件。我找不到一个单独的地方收集它们的链接,因此,这里是一个列表:
最后一个可能是目前来说关于校验器的最佳的总结。
-
Ferris Ellis 发布的 一个关于 eBPF 的系列博客文章。作为我写的这个短文,第一篇文章是关于 eBPF 的历史背景和未来期望。接下来的文章将更多的是技术方面,和前景展望。
-
每个内核版本的 BPF 特性列表 在 bcc 仓库中可以找到。如果你想去知道运行一个给定的特性所要求的最小的内核版本,它是非常有用的。我贡献和添加了链接到提交中,它介绍了每个特性,因此,你也可以从那里很容易地去访问提交历史。
关于 tc
当为了网络目的结合使用 BPF 与 tc (Linux 流量控制
关于 XDP
关于 P4 和 BPF
P4 是一个用于指定交换机行为的语言。它可以为多种目标硬件或软件编译。因此,你可能猜到了,这些目标中的一个就是 BPF … 仅部分支持的:一些 P4 特性并不能被转化到 BPF 中,并且,用类似的方法,BPF 可以做的事情,而使用 P4 却不能表达出现。不过,P4 与 BPF 使用 的相关文档,被隐藏在 bcc 仓库中。这个改变在 P4_16 版本中,p4c 引用的编辑器包含 一个 eBPF 后端。

教程
Brendan Gregg 为想要 使用 bcc 工具 跟踪和监视内核中的事件的人制作了一个非常好的 教程。第一个教程是关于如何使用 bcc 工具,它有许多章节,可以教你去理解怎么去使用已有的工具,而 针对 Python 开发者的一篇 专注于开发新工具,它总共有十七节 “课程”。
Sasha Goldshtein 也有一些 Linux 跟踪研究材料 涉及到使用几个 BPF 工具进行跟踪。
Jean-Tiare Le Bigot 的另一篇文章提供了一个详细的(和有指导意义的)使用 perf 和 eBPF 去设置一个低级的跟踪器 的示例。
对于网络相关的 eBPF 使用案例也有几个教程。有一些值得关注的文档,包括一篇 eBPF 卸载入门指南,是关于在 Open NFP 平台上用 Netronome 操作的。其它的那些,来自 Jesper 的演讲,XDP 能为其它人做什么(及其第二版),可能是 XDP 入门的最好的方法之一。

示例
有示例是非常好的。看看它们是如何工作的。但是 BPF 程序示例是分散在几个项目中的,因此,我列出了我所知道的所有的示例。示例并不是总是使用相同的 helper(例如,tc 和 bcc 都有一套它们自己的 helper,使它可以很容易地去用 C 语言写 BPF 程序)
来自内核的示例
内核中包含了大多数类型的程序:过滤器绑定到套接字或者 tc 接口、事件跟踪/监视、甚至是 XDP。你可以在 linux/samples/bpf/ 目录中找到这些示例。
现在,更多的示例已经作为单元测试被添加到 linux/tools/testing/selftests/bpf 目录下,这里面包含对硬件卸载的测试或者对于 libbpf 的测试。
Jesper 的 Dangaard Brouer 在他的 prototype-kernel 仓库中也维护了一套专门的示例。 这些示例与那些内核中提供的示例非常类似,但是它们可以脱离内核架构(Makefile 和头文件)编译。
也不要忘记去看一下 git 相关的提交历史,它们介绍了一些特定的特性,也许包含了一些特性的详细示例。
来自包 iproute2 的示例
iproute2 包也提供了几个示例。它们都很明显地偏向网络编程,因此,这个程序是附着到 tc 入站或者出站接口上。这些示例在 iproute2/examples/bpf/ 目录中。
来自 bcc 工具集的示例
许多示例都是 与 bcc 一起提供的:
-
一些网络的示例放在相关的目录下面。它们包括套接字过滤器、tc 过滤器、和一个 XDP 程序。
-
tracing 目录包含许多 跟踪编程 的示例。前面的教程中提到的都在那里。那些程序涉及了很大部分的事件监视功能,并且,它们中的一些是面向生产系统的。注意,某些 Linux 发行版(至少是 Debian、Ubuntu、Fedora、Arch Linux)、这些程序已经被 打包了 并且可以很 “容易地” 通过比如 # apt install bcc-tools 进行安装。但是在写这篇文章的时候(除了 Arch Linux),首先要求安装 IO Visor 的包仓库。
-
也有一些 使用 Lua 作为一个不同的 BPF 后端(那是因为 BPF 程序是用 Lua 写的,它是 C 语言的一个子集,它允许为前端和后端使用相同的语言)的一些示例,它在第三个目录中。
-
当然,bcc 工具 自身就是 eBPF 程序使用案例的值得关注示例。
手册页面
虽然 bcc 一般很容易在内核中去注入和运行一个 BPF 程序,将程序附着到 tc 接口也能通过 tc 工具自己完成。因此,如果你打算将 BPF 与 tc 一起使用,你可以在 tc-bpf(8) 手册页面 中找到一些调用示例。

代码
有时候,BPF 文档或者示例并不够,而且你只想在你喜欢的文本编辑器(它当然应该是 Vim)中去显示代码并去阅读它。或者,你可能想深入到代码中去做一个补丁程序或者为机器增加一些新特性。因此,这里对有关的文件的几个建议,找到你想要的函数只取决于你自己!
在内核中的 BPF 代码
XDP 钩子代码
一旦装载进内核的 BPF 虚拟机,由一个 Netlink 命令将 XDP 程序从用户空间钩入到内核网络路径中。接收它的是在 linux/net/core/dev.c 文件中的 dev_change_xdp_fd() 函数,它被调用并设置一个 XDP 钩子。钩子被放在支持的网卡的驱动程序中。例如,用于 Netronome 硬件钩子的 ntp 驱动程序实现放在 drivers/net/ethernet/netronome/nfp/ 中。文件 nfp_net_common.c 接受 Netlink 命令,并调用 nfp_net_xdp_setup(),它会转而调用 nfp_net_xdp_setup_drv() 实例来安装该程序。
在 bcc 中的 BPF 逻辑
在 bcc 的 GitHub 仓库 能找到的 bcc 工具集的代码。其 Python 代码,包含在 BPF 类中,最初它在文件 bcc/src/python/bcc/__init__.py 中。但是许多我觉得有意思的东西,比如,加载 BPF 程序到内核中,出现在 libbcc 的 C 库中。
使用 tc 去管理 BPF 的代码
当然,这些代码与 iproute2 包中的 tc 中的 BPF 相关。其中的一些在 iproute2/tc/ 目录中。文件 f_bpf.c 和 m_bpf.c(和 e_bpf.c)各自用于处理 BPF 的过滤器和动作的(和 tc exec 命令,等等)。文件 q_clsact.c 定义了为 BPF 特别创建的 clsact qdisc。但是,大多数的 BPF 用户空间逻辑 是在 iproute2/lib/bpf.c 库中实现的,因此,如果你想去使用 BPF 和 tc,这里可能是会将你搞混乱的地方(它是从文件 iproute2/tc/tc_bpf.c 中移动而来的,你也可以在旧版本的包中找到相同的代码)。
BPF 实用工具
内核中也带有 BPF 相关的三个工具的源代码(bpf_asm.c、 bpf_dbg.c、 bpf_jit_disasm.c),根据你的版本不同,在 linux/tools/net/ (直到 Linux 4.14)或者 linux/tools/bpf/ 目录下面:
-
bpf_asm 是一个极小的 cBPF 汇编程序。
-
bpf_dbg 是一个很小的 cBPF 程序调试器。
-
bpf_jit_disasm 对于两种 BPF 都是通用的,并且对于 JIT 调试来说非常有用。
-
bpftool 是由 Jakub Kicinski 写的通用工具,它可以与 eBPF 程序交互并从用户空间的映射,例如,去展示、转储、pin 程序、或者去展示、创建、pin、更新、删除映射。
阅读在源文件顶部的注释可以得到一个它们使用方法的概述。
与 eBPF 一起工作的其它必需的文件是来自内核树的两个用户空间库,它们可以用于管理 eBPF 程序或者映射来自外部的程序。这个函数可以通过 linux/tools/lib/bpf/ 目录中的头文件 bpf.h 和 libbpf.h(更高层面封装)来访问。比如,工具 bpftool 主要依赖这些库。
其它值得关注的部分
如果你对关于 BPF 的不常见的语言的使用感兴趣,bcc 包含 一个 BPF 目标的 P4 编译器以及 一个 Lua 前端,它可以被用以代替 C 的一个子集,并且(用 Lua )替代 Python 工具。
LLVM 后端
这个 BPF 后端用于 clang / LLVM 将 C 编译到 eBPF ,是在 这个提交 中添加到 LLVM 源代码的(也可以在 这个 GitHub 镜像 上访问)。
在用户空间中运行
到目前为止,我知道那里有至少两种 eBPF 用户空间实现。第一个是 uBPF,它是用 C 写的。它包含一个解析器、一个 x86_64 架构的 JIT 编译器、一个汇编器和一个反汇编器。
uBPF 的代码似乎被重用来产生了一个 通用实现,其声称支持 FreeBSD 内核、FreeBSD 用户空间、Linux 内核、Linux 用户空间和 Mac OSX 用户空间。它被 VALE 交换机的 BPF 扩展模块使用。
其它用户空间的实现是我做的:rbpf,基于 uBPF,但是用 Rust 写的。写了解析器和 JIT 编译器 (Linux 下两个都有,Mac OSX 和 Windows 下仅有解析器),以后可能会有更多。
提交日志
正如前面所说的,如果你希望得到更多的关于一些特定的 BPF 特性的信息,不要犹豫,去看一些提交日志。你可以在许多地方搜索日志,比如,在 git.kernel.org、在 GitHub 上、或者如果你克隆过它还有你的本地仓库中。如果你不熟悉 git,你可以尝试像这些去做 git blame <file> 去看看介绍特定代码行的提交内容,然后,git show <commit> 去看详细情况(或者在 git log 的结果中按关键字搜索,但是这样做通常比较单调乏味)也可以看在 bcc 仓库中的 按内核版本区分的 eBPF 特性列表,它链接到相关的提交上。

排错
对 eBPF 的追捧是最近的事情,因此,到目前为止我还找不到许多关于怎么去排错的资源。所以这里只有几个,是我在使用 BPF 进行工作的时候,对自己遇到的问题进行的记录。
编译时的错误
-
确保你有一个最新的 Linux 内核版本(也可以看 这个文档)。
-
如果你自己编译内核:确保你安装了所有正确的组件,包括内核镜像、头文件和 libc。
-
当使用 tc-bpf(用于去编译 C 代码到 BPF 中)的 man 页面提供的 bcc shell 函数时:我曾经必须添加包含 clang 调用的头文件:
__bcc() {
clang -O2 -I "/usr/src/linux-headers-$(uname -r)/include/" \
-I "/usr/src/linux-headers-$(uname -r)/arch/x86/include/" \
-emit-llvm -c $1 -o - | \
llc -march=bpf -filetype=obj -o "`basename $1 .c`.o"
}
(现在似乎修复了)。
-
对于使用 bcc 的其它问题,不要忘了去看一看这个工具集的 答疑。
-
如果你从一个并不精确匹配你的内核版本的 iproute2 包中下载了示例,可能会由于在文件中包含的头文件触发一些错误。这些示例片断都假设安装在你的系统中内核的头文件与 iproute2 包是相同版本的。如果不是这种情况,下载正确的 iproute2 版本,或者编辑示例中包含的文件的路径,指向到 iproute2 中包含的头文件上(在运行时一些问题可能或者不可能发生,取决于你使用的特性)。
在加载和运行时的错误
-
使用 tc 去加载一个程序,确保你使用了一个与使用中的内核版本等价的 iproute2 中的 tc 二进制文件。
-
使用 bcc 去加载一个程序,确保在你的系统上安装了 bcc(仅下载源代码去运行 Python 脚本是不够的)。
-
使用 tc,如果 BPF 程序不能返回一个预期值,检查调用它的方式:过滤器,或者动作,或者使用 “直传” 模式的过滤器。
-
还是 tc,注意不使用过滤器,动作不会直接附着到 qdiscs 或者接口。
-
通过内核校验器抛出错误到解析器可能很难。内核文档或许可以提供帮助,因此,可以 参考指南 或者,万不得一的情况下,可以去看源代码(祝你好运!)。记住,校验器 不运行 程序,对于这种类型的错误,记住这点是非常重要的。如果你得到一个关于无效内存访问或者关于未初始化的数据的错误,它并不意味着那些问题真实发生了(或者有时候是,它们完全有可能发生)。它意味着你的程序是以校验器预计可能发生错误的方式写的,并且因此而拒绝这个程序。
-
注意 tc 工具有一个 verbose 模式,它与 BPF 一起工作的很好:在你的命令行尾部尝试追加一个 verbose。
-
bcc 也有一个 verbose 选项:BPF 类有一个 debug 参数,它可以带 DEBUG_LLVM_IR、DEBUG_BPF 和 DEBUG_PREPROCESSOR 三个标志中任何组合(详细情况在 源文件中)。 为调试该代码,它甚至嵌入了 一些条件去打印输出代码。
-
LLVM v4.0+ 为 eBPF 程序 嵌入一个反汇编器。因此,如果你用 clang 编译你的程序,在编译时添加 -g 标志允许你通过内核校验器去以人类可读的格式去转储你的程序。处理转储文件,使用:
$ llvm-objdump -S -no-show-raw-insn bpf_program.o
-
使用映射?你应该去看看 bpf-map,这是一个为 Cilium 项目而用 Go 创建的非常有用的工具,它可以用于去转储内核中 eBPF 映射的内容。也有一个用 Rust 开发的 克隆。
-
在 StackOverflow 上有个旧的 bpf 标签,但是,在这篇文章中从没用过它(并且那里几乎没有与新版本的 eBPF 相关的东西)。如果你是一位来自未来的阅读者,你可能想去看看在这方面是否有更多的活动(LCTT 译注:意即只有旧东西)。

更多!
请经常会回到这篇博客中,来看一看 关于 BPF 有没有新的文章!
特别感谢 Daniel Borkmann 指引我找到了 更多的文档,因此我才完成了这个合集。
via: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
作者:Quentin Monnet
译者:qhwdw
校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出