jemalloc 原理
先说下glibc自带的ptmalloc
多线程支持
- Ptmalloc2有一个主分配区(main arena), 有多个非主分配区。 非主分配区只能使用mmap向操作系统批发申请HEAP_MAX_SIZE(64位系统为64MB)大小的虚拟内存。 当某个线程调用malloc的时候,会先查看线程私有变量中是否已经存在一个分配区,如果存在则尝试加锁,如果加锁失败则遍历arena链表试图获取一个没加锁的arena, 如果依然获取不到则创建一个新的非主分配区。
- free()的时候也要获取锁。分配小块内存容易产生碎片,ptmalloc在整理合并的时候也要对arena做加锁操作。在线程多的时候,锁的开销就会增大。
ptmalloc内存管理
-
用户请求分配的内存在ptmalloc中使用chunk表示, 每个chunk至少需要8个字节额外的开销。 用户free掉的内存不会马上归还操作系统,ptmalloc会统一管理heap和mmap区域的空闲chunk,避免了频繁的系统调用。
-
ptmalloc 将相似大小的 chunk 用双向链表链接起来, 这样的一个链表被称为一个 bin。Ptmalloc 一共 维护了 128 个 bin,并使用一个数组来存储这些 bin(图就像二维数组,或者std::deque底层实现那种感觉,rocksdb arena实现也这样的)
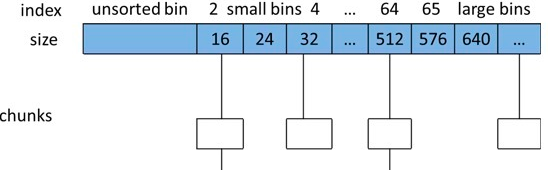
- 数组中的第一个为 unsorted bin, 数组中从 2 开始编号的前 64 个 bin 称为 small bins, 同一个small bin中的chunk具有相同的大小。small bins后面的bin被称作large bins。
- 当free一个chunk并放入bin的时候, ptmalloc 还会检查它前后的 chunk 是否也是空闲的, 如果是的话,ptmalloc会首先把它们合并为一个大的 chunk, 然后将合并后的 chunk 放到 unstored bin 中。 另外ptmalloc 为了提高分配的速度,会把一些小的(不大于64B) chunk先放到一个叫做 fast bins 的容器内。
- 在fast bins和bins都不能满足需求后,ptmalloc会设法在一个叫做top chunk的空间分配内存。 对于非主分配区会预先通过mmap分配一大块内存作为top chunk, 当bins和fast bins都不能满足分配需要的时候, ptmalloc会设法在top chunk中分出一块内存给用户, 如果top chunk本身不够大, 分配程序会重新mmap分配一块内存chunk, 并将 top chunk 迁移到新的chunk上,并用单链表链接起来。如果free()的chunk恰好 与 top chunk 相邻,那么这两个 chunk 就会合并成新的 top chunk,如果top chunk大小大于某个阈值才还给操作系统。主分配区类似,不过通过sbrk()分配和调整top chunk的大小,只有heap顶部连续内存空闲超过阈值的时候才能回收内存。
- 需要分配的 chunk 足够大,而且 fast bins 和 bins 都不能满足要求,甚至 top chunk 本身也不能满足分配需求时,ptmalloc 会使用 mmap 来直接使用内存映射来将页映射到进程空间。
ptmalloc的缺陷
- 后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
- 多线程锁开销大, 需要避免多线程频繁分配释放。
- 内存从thread的arena中分配, 内存不能从一个arena移动到另一个arena, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。 比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena, 但是线程1的300M却不能用了。
- 每个chunk至少8字节的开销很大
- 不定期分配长生命周期的内存容易造成内存碎片,不利于回收。 64位系统最好分配32M以上内存,这是使用mmap的阈值。
这里的问题在于arena是全局的 jemalloc和tcmalloc都针对这个做优化
tcmalloc的数据结构看参考链接
主要的优化 size分类,TheadCache
小对象分配
- tcmalloc为每个线程分配了一个线程本地ThreadCache,小内存从ThreadCache分配,此外还有个中央堆(CentralCache),ThreadCache不够用的时候,会从CentralCache中获取空间放到ThreadCache中。
- 小对象(<=32K)从ThreadCache分配,大对象从CentralCache分配。大对象分配的空间都是4k页面对齐的,多个pages也能切割成多个小对象划分到ThreadCache中。
- 小对象有将近170个不同的大小分类(class),每个class有个该大小内存块的FreeList单链表,分配的时候先找到best fit的class,然后无锁的获取该链表首元素返回。如果链表中无空间了,则到CentralCache中划分几个页面并切割成该class的大小,放入链表中。
CentralCache分配管理
-
大对象(>32K)先4k对齐后,从CentralCache中分配。 CentralCache维护的PageHeap如下图所示, 数组中第256个元素是所有大于255个页面都挂到该链表中。
- 当best fit的页面链表中没有空闲空间时,则一直往更大的页面空间则,如果所有256个链表遍历后依然没有成功分配。 则使用sbrk, mmap, /dev/mem从系统中分配。
- tcmalloc PageHeap管理的连续的页面被称为span. 如果span未分配, 则span是PageHeap中的一个链表元素 如果span已经分配,它可能是返回给应用程序的大对象, 或者已经被切割成多小对象,该小对象的size-class会被记录在span中
- 在32位系统中,使用一个中央数组(central array)映射了页面和span对应关系, 数组索引号是页面号,数组元素是页面所在的span。 在64位系统中,使用一个3-level radix tree记录了该映射关系。
回收
- 当一个object free的时候,会根据地址对齐计算所在的页面号,然后通过central array找到对应的span。
- 如果是小对象,span会告诉我们他的size class,然后把该对象插入当前线程的ThreadCache中。如果此时ThreadCache超过一个预算的值(默认2MB),则会使用垃圾回收机制把未使用的object从ThreadCache移动到CentralCache的central free lists中。
- 如果是大对象,span会告诉我们对象锁在的页面号范围。 假设这个范围是[p,q], 先查找页面p-1和q+1所在的span,如果这些临近的span也是free的,则合并到[p,q]所在的span, 然后把这个span回收到PageHeap中。
- CentralCache的central free lists类似ThreadCache的FreeList,不过它增加了一级结构,先根据size-class关联到spans的集合, 然后是对应span的object链表。如果span的链表中所有object已经free, 则span回收到PageHeap中。
jemalloc
-
与tcmalloc类似,每个线程同样在<32KB的时候无锁使用线程本地cache。
-
Jemalloc在64bits系统上使用下面的size-class分类:
categories Spacing Size Small 8 [8] 16 [16, 32, 48, …, 128] 32 [160, 192, 224, 256] 64 [320, 384, 448, 512] 128 [640, 768, 896, 1024] 256 [1280, 1536, 1792, 2048] 512 [2560, 3072, 3584] Large 4 KiB [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB] Huge 4 KiB [4 MiB, 8 MiB, 12 MiB, …] -
small/large对象查找metadata需要常量时间, huge对象通过全局红黑树在对数时间内查找。
-
虚拟内存被逻辑上分割成chunks(默认是4MB,1024个4k页),应用线程通过round-robin算法在第一次malloc的时候分配arena, 每个arena都是相互独立的,维护自己的chunks, chunk切割pages到small/large对象。free()的内存总是返回到所属的arena中,而不管是哪个线程调用free()。
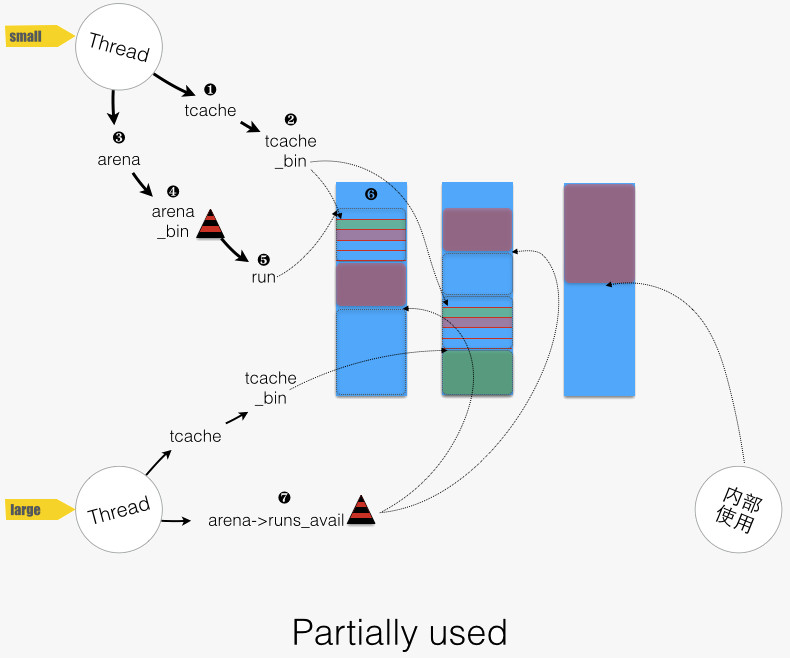
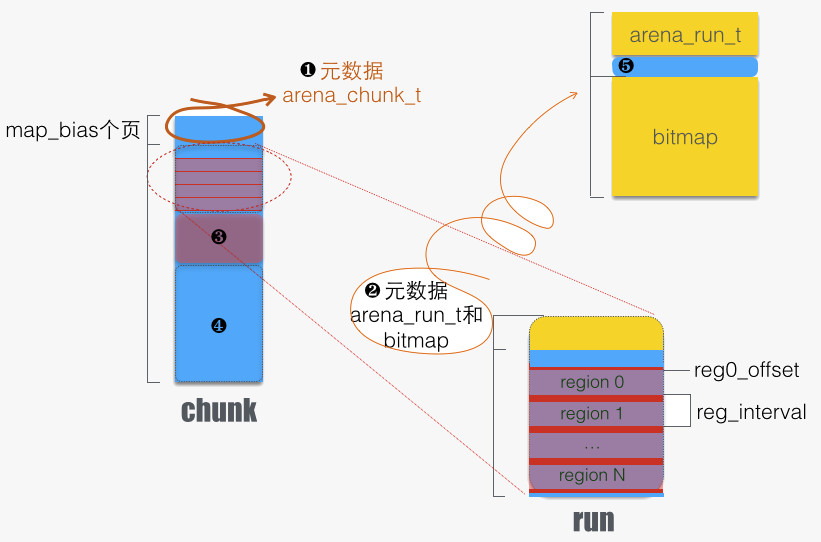
结构图
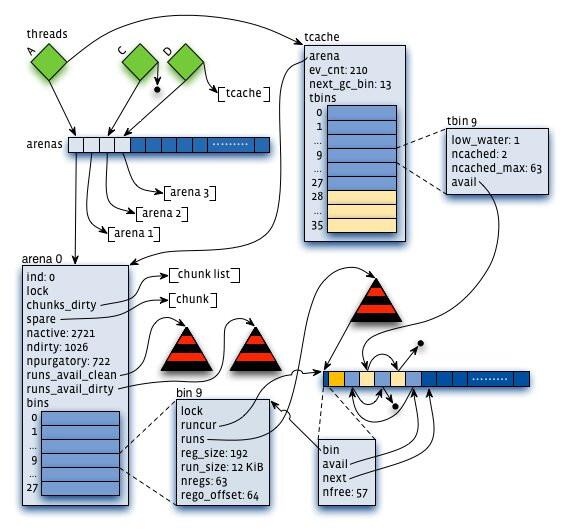
jemalloc 的内存分配,可分成四类:
- small( size < min(arena中得bin) ):如果请求size不大于arena的最小的bin,那么就通过线程对应的tcache来进行分配。首先确定size的大小属于哪一个tbin,比如2字节的size就属于最小的8字节的tbin,然后查找tbin中有没有缓存的空间,如果有就进行分配,没有则为这个tbin对应的arena的bin分配一个run,然后把这个run里面的部分块的地址依次赋给tcache的对应的bin的avail数组,相当于缓存了一部分的8字节的块,最后从这个availl数组中选取一个地址进行分配
- large( max(tcache中的块) > size > min(arean中的bin) ): 如果请求size大于arena的最小的bin,同时不大于tcache能缓存的最大块,也会通过线程对应的tcache来进行分配,但方式不同。首先看tcache对应的tbin里有没有缓存块,如果有就分配,没有就从chunk里直接找一块相应的page整数倍大小的空间进行分配(当这块空间后续释放时,这会进入相应的tcache对应的tbin里)
- large( chunk > size > tcache ): 如果请求size大于tcache能缓存的最大块,同时不大于chunk大小(默认是4M),具体分配和第2类请求相同,区别只是没有使用tcache
- huge(size> chunk ):如果请求大于chunk大小,直接通过mmap进行分配。
简而言之,就是:
小内存(small class): 线程缓存bin -> 分配区bin(bin加锁) -> 问系统要 中型内存(large class):分配区bin(bin加锁) -> 问系统要 大内存(huge class): 直接mmap组织成N个chunk+全局huge红黑树维护(带缓存)
回收流程大体和分配流程类似,有tcache机制的会将回收的块进行缓存,没有tcache机制的直接回收(不大于chunk的将对应的page状态进行修改,回收对应的run;大于chunk的直接munmap)。需要关注的是jemalloc何时会将内存还给操作系统,因为ptmalloc中存在因为使用top_chunk机制(详见华庭的文章)而使得内存无法还给操作系统的问题。目前看来,除了大内存直接munmap,jemalloc还有两种机制可以释放内存:
- 当释放时发现某个chunk的所有内存都已经为脏(即分配后又回收)就把整个chunk释放
- 当arena中的page分配情况满足一个阈值时对dirty page进行purge(通过调用madvise来进行)。这个阈值的具体含义是该arena中的dirty page大小已经达到一个chunk的大小且占到了active page的1/opt_lg_dirty_mult(默认为1/32)。active page的意思是已经正在使用中的run的page,而dirty page就是其中已经分配后又回收的page。
Ref
- ptmalloc 原理,抄自这里http://www.cnhalo.net/2016/06/13/memory-optimize/
- 图解tcmallochttps://zhuanlan.zhihu.com/p/29216091
- jemalloc 分析
- gdb查看jemalloc内存布局https://www.twblogs.net/a/5b8464ee2b71775d1cd09277/zh-cn
- Scalable memory allocation using jemalloc 这个值得翻译一下,里面有架构图和优化细节
- 核心架构介绍http://brionas.github.io/2015/01/31/jemalloc%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90-%E6%A0%B8%E5%BF%83%E6%9E%B6%E6%9E%84/
- jemalloc 内存管理http://brionas.github.io/2015/01/31/jemalloc%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90-%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/
- 各种对比 https://blog.csdn.net/huangynn/article/details/50700093
这里把搜集的一些资料列举一下,后续做整理
-
nedmallochttps://www.nedprod.com/programs/portable/nedmalloc/
-
tcmalloc和jemalloc比较https://stackoverflow.com/questions/7852731/c-memory-allocation-mechanism-performance-comparison-tcmalloc-vs-jemalloc
结论放这里
If I remember correctly, the main difference was with multi-threaded projects.
Both libraries try to de-contention memory acquire by having threads pick the memory from different caches, but they have different strategies:
jemalloc(used by Facebook) maintains a cache per threadtcmalloc(from Google) maintains a pool of caches, and threads develop a “natural” affinity for a cache, but may change
This led, once again if I remember correctly, to an important difference in term of thread management.
jemallocis faster if threads are static, for example using poolstcmallocis faster when threads are created/destructed
There is also the problem that since
jemallocspin new caches to accommodate new thread ids, having a sudden spike of threads will leave you with (mostly) empty caches in the subsequent calm phase.As a result, I would recommend
tcmallocin the general case, and reservejemallocfor very specific usages (low variation on the number of threads during the lifetime of the application) -
ruby使用各种malloc的benchmark,有点参考价值http://engineering.appfolio.com/appfolio-engineering/2018/2/1/benchmarking-rubys-heap-malloc-tcmalloc-jemalloc
-
repo https://github.com/jemalloc/jemalloc wiki值得看下
-
一个使用例子 https://www.jianshu.com/p/5fd2b42cbf3d
-
这是另一个测试,不过HN上有人说测得不合理http://ithare.com/testing-memory-allocators-ptmalloc2-tcmalloc-hoard-jemalloc-while-trying-to-simulate-real-world-loads/
-
jemalloc设计者的博客,很多文章。是个狠人http://branchtaken.net/blog/2008/07/25/treaps-versus-red-black-trees.html
-
glibc malloc的调优文档https://www.gnu.org/software/libc/manual/html_node/Memory-Allocation-Tunables.html
-
理解glibc malloc https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
-
论文https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
-
malloc 概论 必读http://blog.reverberate.org/2009/02/one-malloc-to-rule-them-all.html