C++ 中文周刊 第14期
从reddit/hackernews/lobsters/meetingcpp摘抄一些c++动态。
每周更新
欢迎投稿,推荐或自荐文章/软件/资源等,请提交 issue
资讯
编译器信息最新动态推荐关注hellogcc公众号
文章
-
struct B { __int128 c; uint64_t d; }; struct A { char a; // struct B b; char b[0]; }; int main() { A* a = (A*)malloc(sizeof(struct A) + sizeof(B)); struct B* b = (struct B*)a->b; __int128 bb; b->c = bb; asm volatile("" : "+m,r"(b->c) : : "memory"); return 0; }这段代码使用-march优化可能会core,汇编用了movaps vmovdqa 需要对齐
` MOVAPS & vmovdqa`这两条指令,支持 128 bit 的操作,同时要求 16B 地址对齐,如果违反对齐规则,就会触发 SEGV。
对于 GCC 来说,在
x86-64下,默认 march 是x86-64,具有最好的兼容性,其支持 SSE 指令。可以通过gcc -Q --help=target | grep -- '-march='来查看 GCC 默认 march 属性。 对于Sandy Bridge架构,至少支持AVX,XSAVE等指令。 所以,我们可以看到,编译选项开了-march=sandybridge之后,使用上了 AVX 指令。 同时,如果不开编译器优化,那么使用 mov 指令来完成 4 字节的搬迁,开启 O2 优化,会使用对应的 SSE 或者 AVX 指令来优化 mov 操作。
-
#include <vector> #include <algorithm> int count_even(const std::vector<int>& v) { const auto& my_func = [] (int i)->bool { return i%2==0; }; return std::count_if(std::cbegin(v), std::cend(v), my_func); }这里的my_func是const&的,这段代码用const&相当于用函数指针,要省一点拷贝lambda的开销?
测试结果表示确实是要比值lambda省一点的
-
Using CMake and managing dependencies
手把手教你用FetchContent
First, let’s add
add_subdirectory(dependencies)to our rootCMakeLists.txt:... add_subdirectory(dependencies) # add this add_subdirectory(src)The
dependencies/CMakeLists.txtlooks like this:include(FetchContent) FetchContent_Declare( sfml GIT_REPOSITORY "https://github.com/SFML/SFML" GIT_TAG 2f11710abc5aa478503a7ff3f9e654bd2078ebab # 2.5.1 ) add_subdirectory(sfml)Next,
dependencies/sfml/CMakeLists.txt(I’ll explain what goes on here a bit later):message(STATUS "Fetching SFML...") # No need to build audio and network modules set(SFML_BUILD_AUDIO FALSE) set(SFML_BUILD_NETWORK FALSE) FetchContent_MakeAvailable(sfml)src/CMakeLists.txtlooks like this now:add_executable(example_exe main.cpp) target_link_libraries(example_exe PRIVATE sfml-graphics)And finally, let’s change our
src/main.cppto the following “SFML Hello world” code which is used in its many examples:#include <SFML/Graphics.hpp> int main() { sf::RenderWindow window(sf::VideoMode(200, 200), "SFML works!"); sf::CircleShape shape(100.f); shape.setFillColor(sf::Color::Green); while (window.isOpen()) { sf::Event event; while (window.pollEvent(event)) { if (event.type == sf::Event::Closed) window.close(); } window.clear(); window.draw(shape); window.display(); } return 0; }cmake --build . -
Managing dependencies with Meson + WrapDB 上面教程的meson版本,meson也是一种编译管理工具
-
Mocking non-virtual member functions with gmock
比如这段代码,如何mock
class IWantToBeMocked { public: int setNumber(int n); void resetNumber(); private: int n; };就是加一层
#if defined(UNITTEST) #define TEST_IFACE virtual #else #define TEST_IFACE #endif class IWantToBeMocked { private: void setNumberImpl(int n); int resetNumberImpl(); protected: void TEST_IFACE setNumberIface(int n) { setNumberImpl(n); } int TEST_IFACE resetNumberIface() { return resetNumberImpl(); } public: void setNumber(int n) { setNumberIface(n); } int resetNumber() { return resetNumberIface(); } private: int n; };注意这个TEST_IFACE virtual 测试环境,这里是virtual的,就可以mock iface函数,继而变相mock setNumber达到效果。
可以加上aways_inline优化掉多层函数开销
-
c++ tip of week 227 Did you know that
std::variantbecome valueless by exception?就是下面这段代码
struct foo {
foo() = default;
foo(const foo&) { throw 42; }
};
int main() {
std::variant<int, foo> v{42};
assert(not v.valueless_by_exception());
try {
v = foo{}; // throws
} catch(...) { }
assert(v.valueless_by_exception());
}
这段代码没啥问题
std::vector<int> create_range()
{
return {1, 2, 3, 4, 5};
}
int main()
{
for (auto const& value : create_range())
{
std::cout << value << ' ';
}
}
这段代码有问题
std::vector<int> create_range()
{
return {1, 2, 3, 4, 5};
}
std::vector<int> const& f(std::vector<int> const& v)
{
return v;
}
int main()
{
for (auto const& value : f(create_range()))
{
std::cout << value << ' ';
}
}
Range-for中的range是个万能引用/右值引用,f是constT& 绑定不上,所以这里是未定义行为, 解决方法,别偷懒,放到循环外面
-
Counting the number of matching characters in two ASCII strings
给了一种比较字符串的优化写法, 简单写了个benchmark
#include <stdlib.h> #include <cstring> const char* s1 = "bpADxkvXqHNaWj2PEnD31uDBijfcR8bm7kR00x7FuDQ4AGz5c1HHCY8jGXEBLUYvIflw0bR1WCEdYWwjGgyToyS0Oes6pCpEDVRd"; const char* s2 = "rq7o9ZRudrLgMeeMJVxRcWL0dJN8n6GefMkqbEcTCznvup1iqTuafrDhDjxYepJczStOJfO8Wh53NOLuje8FnDiC7ZRwOdyQNHw3"; uint64_t matching_bytes_in_word(uint64_t x, uint64_t y) { uint64_t xor_xy = x ^ y; // credit: mula // 7th bit set if lower 7 bits are zero const uint64_t t0 = (~xor_xy & 0x7f7f7f7f7f7f7f7fllu) + 0x0101010101010101llu; // 7th bit set if 7th bit is zero const uint64_t t1 = (~xor_xy & 0x8080808080808080llu); uint64_t zeros = t0 & t1; return ((zeros >> 7) * 0x0101010101010101ULL) >> 56; } uint64_t matching_bytes(const char * c1, const char * c2, size_t n) { size_t count = 0; size_t i = 0; uint64_t x, y; for(; i + sizeof(uint64_t) <= n; i+= sizeof(uint64_t)) { memcpy(&x, c1 + i, sizeof(uint64_t) ); memcpy(&y, c2 + i, sizeof(uint64_t) ); count += matching_bytes_in_word(x,y); } for(; i < n; i++) { if(c1[i] == c2[i]) { count++; } } return count; } uint64_t standard_matching_bytes(const char * c1, const char * c2, size_t n) { size_t count = 0; size_t i = 0; for(; i < n; i++) { if(c1[i] == c2[i]) { count++; } } return count; } static void b_standard_matching_bytes(benchmark::State& state) { for (auto _ : state) { auto res = standard_matching_bytes(s1, s2, 100); benchmark::DoNotOptimize(res); } } BENCHMARK(b_standard_matching_bytes); static void b_matching_bytes(benchmark::State& state) { for (auto _ : state) { auto res = matching_bytes(s1, s2, 100); benchmark::DoNotOptimize(res); } } BENCHMARK(b_matching_bytes);效果如图
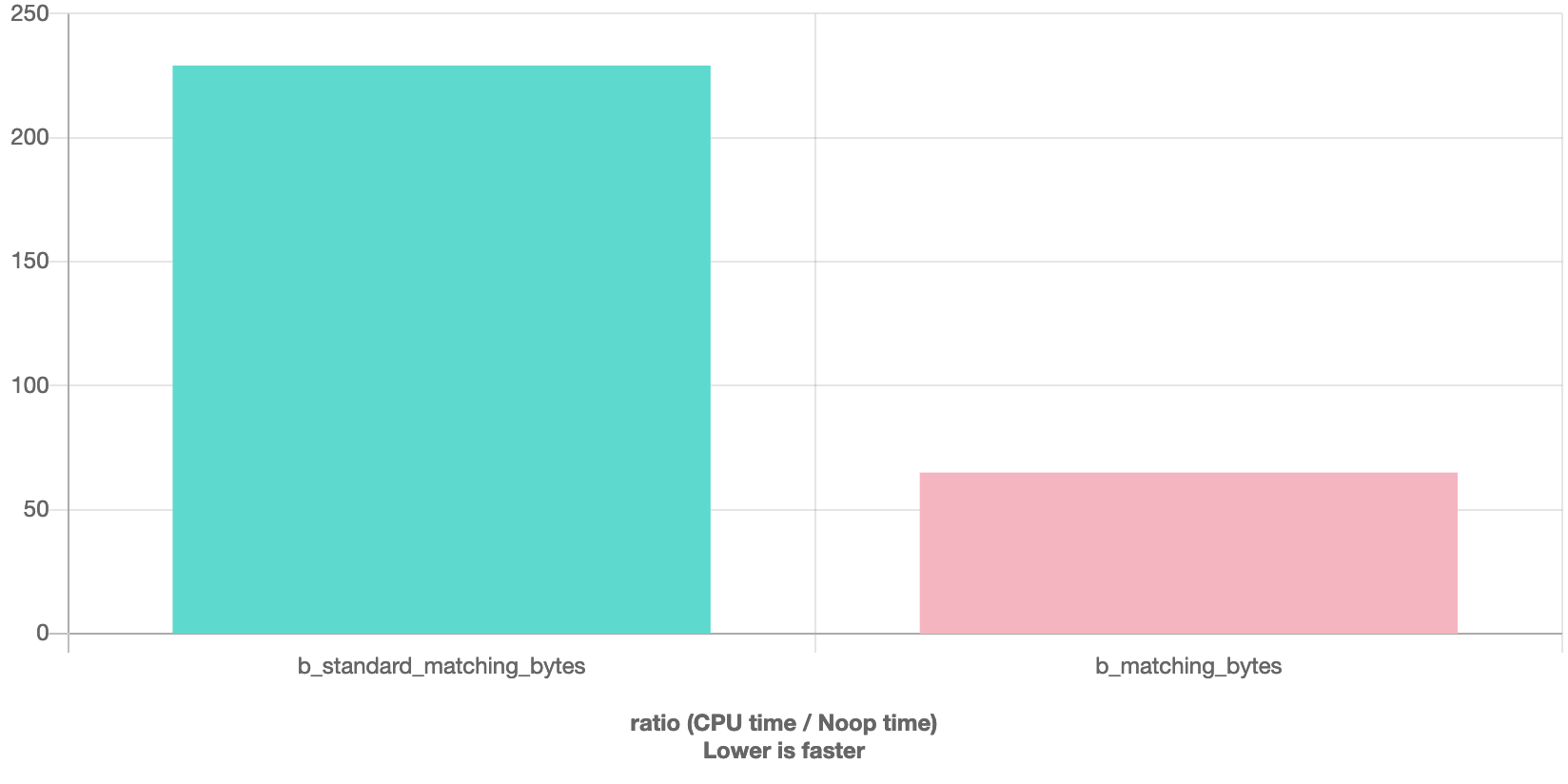
能看出明显快不少的
视频
-
C++ Weekly - Ep 273 - C++23’s Lambda Simplification (With Commodore 64 Example) 讨论mutable场景下的lambda的()不能省掉。c++23有提案修订。
-
JetBrains Brings C++Now to You cppnow已经结束了,但是视频还没正式放出来,jetbrains是赞助商,放出来几个视频,一共六个 简单看了一眼,colony容器的可以看看,还有个讲解unicode的,我不懂,就不评论了。讲cmake的没啥看的
-
在线走读CTRE代码,这种模式挺有意思的,不过内容比较枯燥
CTRE是一个编译器正则匹配库。很硬核
项目
- https://github.com/cdeln/cpp_enum_set/blob/master/example/basic_tutorial.cpp 一个enum 取交集并集的裤
- imgui版本更新 https://github.com/ocornut/imgui/releases/tag/v1.83 imgui是一个很小巧方便的GUI工具库
- https://github.com/foonathan/memory 更好用的内存分配组件
