clickhouse 简单走读
[toc]
基本架构
主要路径
基本概念
MergeTree

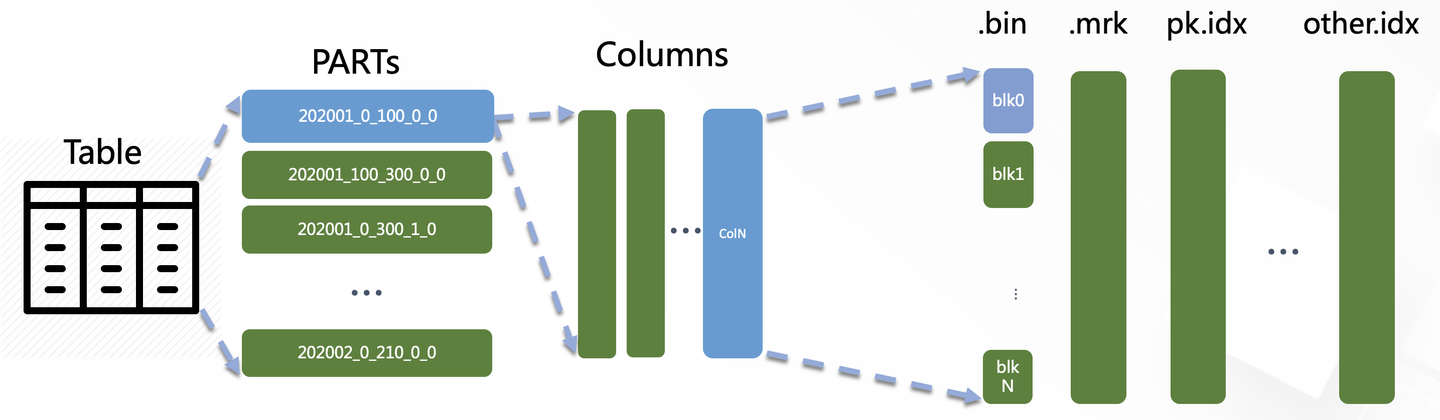
类似memtable和sst的关系
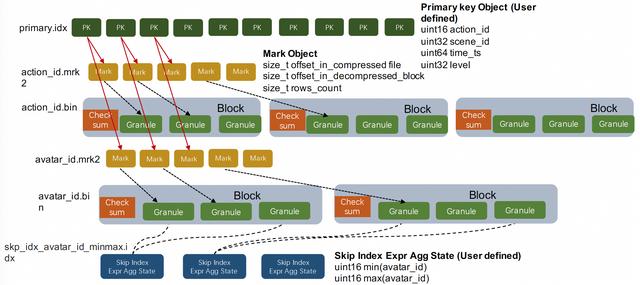
具体内容
上图展示了单个MergeTree Data Part里最核心的一部分磁盘文件(只画了action_id和avatar_id列其关的存储文件),从功能上分主要有三个类:
1 数据文件:action_id.bin、avatar_id.bin等都是单个列按块压缩后的列存文件。ClickHouse采用了非常极端的列存模式,这里展开一些细节,单个列数据可能会对应多个列存文件,例如申明一个Nullable字段时会多一个nullable标识的列存文件,申明一个Array字段时会多一个array size的列存文件, 采用字典压缩时字典Key也会单独变成一个列存文件。有一点小Tips:当用户不需要Null值特殊标识时,最好不要去申明Nullable,这是ClickHouse的极简化设计思路。
2 Mark标识文件:action_id.mrk2、avatar_id.mrk2等都是列存文件中的Mark标记,Mark标记和MergeTree列存中的两个重要概念相关:Granule和Block。
- Granule是数据按行划分时用到的逻辑概念。关于多少行是一个Granule这个问题,在老版本中这是用参数index_granularity设定的一个常量,也就是每隔确定行就是一个Granule。在当前版本中有另一个参数index_granularity_bytes会影响Granule的行数,它的意义是让每个Granule中所有列的sum size尽量不要超过设定值。老版本中的定长Granule设定主要的问题是MergeTree中的数据是按Granule粒度进行索引的,这种粗糙的索引粒度在分析超级大宽表的场景中,从存储读取的data size会膨胀得非常厉害,需要用户非常谨慎得设定参数。
- Block是列存文件中的压缩单元。每个列存文件的Block都会包含若干个Granule,具体多少个Granule是由参数min_compress_block_size控制,每次列的Block中写完一个Granule的数据时,它会检查当前Block Size有没有达到设定值,如果达到则会把当前Block进行压缩然后写磁盘。
- 从以上两点可以看出MergeTree的Block既不是定data size也不是定行数的,Granule也不是一个定长的逻辑概念。所以我们需要额外信息快速找到某一个Granule。这就是Mark标识文件的作用,它记录了每个Granule的行数,以及它所在的Block在列存压缩文件中的偏移,同时还有Granule在解压后的Block中的偏移位置。
3主键索引:primary.idx是表的主键索引。ClickHouse对主键索引的定义和传统数据库的定义稍有不同,它的主键索引没用主键去重的含义,但仍然有快速查找主键行的能力。ClickHouse的主键索引存储的是每一个Granule中起始行的主键值,而MergeTree存储中的数据是按照主键严格排序的。所以当查询给定主键条件时,我们可以根据主键索引确定数据可能存在的Granule Range,再结合上面介绍的Mark标识,我们可以进一步确定数据在列存文件中的位置区间。ClickHoue的主键索引是一种在索引构建成本和索引效率上相对平衡的粗糙索引。MergeTree的主键序列默认是和Order By序列保存一致的,但是用户可以把主键序列定义成Order By序列的部分前缀。
4分区键索引:minmax_time.idx、minmax_region_name.idx是表的分区键索引。MergeTree存储会把统计每个Data Part中分区键的最大值和最小值,当用户查询中包含分区键条件时,就可以直接排除掉不相关的Data Part,这是一种OLAP场景下常用的分区裁剪技术。
5Skipping索引:skp_idx_avatar_id_minmax.idx是用户在avatar_id列上定义的MinMax索引。Merge Tree中 的Skipping Index是一类局部聚合的粗糙索引。用户在定义skipping index的时候需要设定granularity参数,这里的granularity参数指定的是在多少个Granule的数据上做聚合生成索引信息。用户还需要设定索引对应的聚合函数,常用的有minmax、set、bloom_filter、ngrambf_v1等,聚合函数会统计连续若干个Granule中的列值生成索引信息。Skipping索引的思想和主键索引是类似的,因为数据是按主键排序的,主键索引统计的其实就是每个Granule粒度的主键序列MinMax值,而Skipping索引提供的聚合函数种类更加丰富,是主键索引的一种补充能力。另外这两种索引都是需要用户在理解索引原理的基础上贴合自己的业务场景来进行设计的。
datapart 以10_1_1_0为例
- 10表示分区key的值,本表使用a列作为分区键,日常生产会使用日期函数来作为分区键
- 1表示存储这个datapart的数据的block的最小值
- 1表示存储这个datapart的数据的block的最大值
- 0表示MergeTree的深度,大约可以理解为datapart进行mutation的次数
datapart
每个datapart存储着压缩后的数据文件,元数据文件和各种索引文件,校验和文件等。datapart其实在磁盘上有两种存储方式:一种是MergeTreeDataPartCompact,另一种是MergeTreeDataPartWide.所有写入的数据先写入到内存中的MergeTreeDataPartInMemory中,你可以理解为ClickHouse的MemTable,当In Memory DataPart积攒到一定大小就会flush到磁盘生成compact或者wide形式的datapart。
Compact方式
所有的列数据单独存储在一个文件data.bin中,所有索引文件也存储在一个data.mrk3文件中.这种compact存储方式用于存储大小不足10M的小datapart. 可用于优化频繁的小批量写操作,并且只有开启了自适应性granularity功能的MergeTree Table才支持Compact方式的存储.而随着数据增加,最终在mutation之后还是会以Wide方式来存储datapart.
Wide方式
每一个列都会有单独的mrk3文件和若干个.bin文件来分别存储其元数据和压缩后的数据文件. 当未压缩的数据的大小或者行数分别超过min_bytes_for_wide_part 或者min_rows_for_wide_part就会采用Wide方式来存储.
Granule
我们知道数据以列存形式组织,那么即使是读取一行数据也要把整个.bin文件加载到内存,那么这样是很消耗IO的,那CK是如何在存储引擎来解决IO读放大问题呢?
ClickHouse引入了颗粒度这个概念。每个data part都会被逻辑划分为若干个Granules,Granule作为CK在内存中进行数据扫描的单位。写入数据会根据index_granularity或者index_granularity_bytes 参数来积攒成一个Granule,默认是8192行一个Granule ,当若干个Granule在内存的buffer中又积攒到一定量(min_compress_block_size 默认64KB)的时候就会触发数据压缩和落盘操作而生成一个Block。每个Granule会对应.mrk文件中的一个mrk。
Block
Block作为CK进行磁盘IO的基本单位和文件压缩/解压缩的基本单位。每一个Block都有若干个Granules。在CK的代码内我们也可以看到许多以Block为单位的字节流接口,说明数据在读写字节流中都是以Block为单位进行传输的。block的大小范围取决于max_compress_block_size和min_compress_block_size,每个block的文件头都会保存该block压缩前后大小,用于数据校验。
参考
- https://zhuanlan.zhihu.com/p/143708307
