tellstore fast scan 代码走读
[toc]
我看到了infiniband,RDMA没钱上不了,落地先别想了。就是类似ramcloud看看架构
但没有文件,纯内存的。我找了半天没找到文件操作。应该是没有的。因为如果一直append 文件空洞问题页没有考虑
里面的log概念类似操作记录,是内存的,基于page。但没有把page刷入磁盘的动作以及管理地址
重点在内存管理,scan阶段优化
cmakelists.txt能看出来有三种存储
add_tellstored(logstructured logstructured USE_LOGSTRUCTURED_MEMORY)
add_tellstored(rowstore deltamain USE_DELTA_MAIN_REWRITE USE_ROW_STORE)
add_tellstored(columnmap deltamain USE_DELTA_MAIN_REWRITE USE_COLUMN_MAP)
logstructured是文件, 行存列存用的都是deltamain的存储。这里要关注文件的管理/compact
分别对应 LogstructuredMemoryStore, DeltaMainRewriteStore<deltamain::RowStoreContext>, DeltaMainRewriteStore<deltamain::ColumnMapContext>
主要逻辑
class ServerSocket : public crossbow::infinio::RpcServerSocket<ServerManager, ServerSocket>
class ServerManager : public crossbow::infinio::RpcServerManager<ServerManager, ServerSocket>
- Storage,ScanBufferManager InfinibandProcessor = InfinibandService.createProcessor()
- EventProcessor::start() -> doPoll
- poll ->ibv_poll_cq
- processWorkComplete
- RECEIVE:acquireReceiveBuffer -> onReceive/onImmediate -> postReceiveBuffer
- crossbow::buffer_reader.extract
- onMessage
- ServerSocket::onRequest 正式执行命令
- SEND: onSend -> releaseSendBuffer
- WRITE: onWrite
- READ: onRead
- socket->onDrained()
- RECEIVE:acquireReceiveBuffer -> onReceive/onImmediate -> postReceiveBuffer
- prepareSleep
- epoll_wait ->poller->wakeup()
- InfinibandService::run() 内部是rmda拿消息,剩下的handle和epoll之类的差不多
- processEvent
- InfinibandAcceptorImpl::onConnectionRequest
- RpcServerManager<Manager, Socket>::onConnection
- RpcServerManager::createConnection -> new ServerSocket
- InfinibandAcceptorImpl::onConnectionRequest
- processEvent
所有的读写都在handlexx里
CURD
这里以Get为例子,主要路径都差不多
- ServerSocket::handleGet
- handleSnapshot,快照读,没快照直接错误,可以指定快照hasDescriptor或者在cache里随便读一个,或者更新一个snapshot
- mStorage.get 针对不同的storage类型有不同的get
- writeResponse
- buffer_writer
- writeResponse
- mStorage.get 针对不同的storage类型有不同的get
- handleSnapshot,快照读,没快照直接错误,可以指定快照hasDescriptor或者在cache里随便读一个,或者更新一个snapshot
这套代码的风格确实挺asio,都是透传lambda
Scan
Scan Processor
std::vector<ScanQueryProcessor, tbb::cache_aligned_allocator<ScanQueryProcessor>> mQueries;
ColumnMapScanProcessor::process()
processMainPage
evaluateMainQueries(page, startIdx, endIdx);
processMainPage
processUpdateRecord
writeRecord
ScanThread
mThread(&ScanThread<Table>::operator(), this)
startScan Table<Context>::Table::startScan
简单的condvar使用
void notify(void* data, ScanThread::PointerTag tag) {
{
std::unique_lock<decltype(mWaitMutex)> waitLock(mWaitMutex);
mData.store(reinterpret_cast<uintptr_t>(data) | crossbow::to_underlying(tag));
}
mWaitCondition.notify_one();
}
void prepare(typename Table::Scan* scan) {
notify(scan, PointerTag::PREPARE);
}
void process(typename Table::ScanProcessor* processor) {
notify(processor, PointerTag::PROCESS);
}
void operator()() {
while (true) {
uintptr_t data = 0;
{
std::unique_lock<decltype(mWaitMutex)> waitLock(mWaitMutex);
mWaitCondition.wait(waitLock, [this, &data] () {
data = mData.load();
return data != 0;
});
}
if ((data & crossbow::to_underlying(PointerTag::STOP)) != 0) {
break;
}
if ((data & crossbow::to_underlying(PointerTag::PREPARE)) != 0) {
auto scan = reinterpret_cast<typename Table::Scan*>(data & ~crossbow::to_underlying(PointerTag::PREPARE));
scan->prepareMaterialization();
} else if ((data & crossbow::to_underlying(PointerTag::PROCESS)) != 0) {
auto processor = reinterpret_cast<typename Table::ScanProcessor*>(data &
~crossbow::to_underlying(PointerTag::PROCESS));
processor->process();
} else {
LOG_ASSERT(false, "Unknown pointer tag");
}
mData.store(0);
}
}
ScanManager
mMasterThread = std::thread(&ScanManager<Table>::operator(), this);
mSlaves.emplace_back(new ScanThread<Table>());
Storage实现
三种Storage的实现都差不多
mTableManager(*mPageManager, config, mGc, mVersionManager),
PageManager::Ptr mPageManager;
GC mGc;
VersionManager mVersionManager;
TableManager<Table, GC> mTableManager;
所有工作都是TableManager来做
tablemanager和GC,不同storage实现不同
DeltaMainRewriteStore
using Table = deltamain::Table<Context>;
using GC = deltamain::GarbageCollector<Context>;
LogstructuredMemoryStore
using Table = logstructured::Table;
using GC = Table::GarbageCollector;
DeltaMainRewriteStore
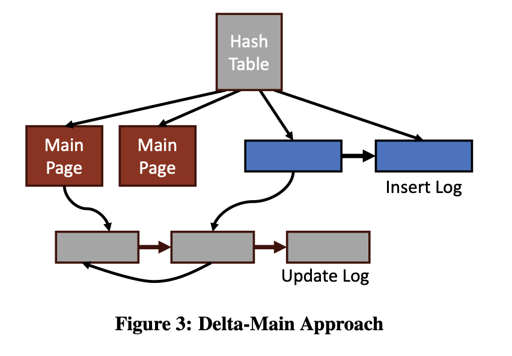
行/列存,主要取决于Context
直接看接口
template <typename Fun>
int get(uint64_t key, const commitmanager::SnapshotDescriptor& snapshot, Fun fun) const;
int insert(uint64_t key, size_t size, const char* data, const commitmanager::SnapshotDescriptor& snapshot);
int update(uint64_t key, size_t size, const char* data, const commitmanager::SnapshotDescriptor& snapshot);
int remove(uint64_t key, const commitmanager::SnapshotDescriptor& snapshot)
int revert(uint64_t key, const commitmanager::SnapshotDescriptor& snapshot);
void runGC(uint64_t minVersion);
insert
- mMainTable.load()->get(key) 线程安全?这回有人改hashtable怎么办?
- internalUpdate
Table构成
PageManager& mPageManager;
crossbow::string mTableName;
Record mRecord;
uint64_t mTableId;
DynamicInsertTable mInsertTable;
Log<OrderedLogImpl> mInsertLog; //记录update
Log<OrderedLogImpl> mUpdateLog; // 记录insert
std::atomic<CuckooTable*> mMainTable;
std::atomic<PageList*> mPages;
Context mContext;
其中PageList就是Log<OrderedLogImpl>::LogIterator的封装,可以看成一个iterator_view
- CuckooTable
构成比较简单
PageManager& mPageManager;
using EntryT = std::pair<uint64_t, void*>;
std::vector<EntryT*> mPages;
cuckoo_hash_function hash1;
cuckoo_hash_function hash2;
cuckoo_hash_function hash3;
mutable std::vector<EntryT*> mPages; //标记当前页是否被改,如果被改需要cow
size_t mSize;
一般pagesize是4k ` getconf PAGESIZE`
tellstore用的pagesize是2M 0x200000
ENTRIES_PER_PAGE再除以 16 也就是 128k个key 也就是12万key
一共三个hash,最起码三个page,三的倍数扩展,hash冲突就定位到下一个page
hash算法比较简单,但保证hash落到page内。hash是根据pagesize不断变化的
rehash阶段会改hash和整体大小,并做一些搬迁页
- OrderedLogImpl
LogstructuredMemoryStore
table构成
VersionManager& mVersionManager;
OpenAddressingTable& mHashMap;
crossbow::string mTableName;
Record mRecord;
const uint64_t mTableId;
Log<UnorderedLogImpl> mLog;
crossbow 的一些小技巧
实现了一个基础类库,有很多无锁小组件
fixed_size_stack
#pragma once
#include <atomic>
#include <cassert>
#include <cstddef>
#include <vector>
template<class T>
class fixed_size_stack {
private:
struct alignas(8) Head {
unsigned readHead = 0u;
unsigned writeHead = 0u;
Head() noexcept = default;
Head(unsigned readHead, unsigned writeHead)
: readHead(readHead),
writeHead(writeHead)
{}
};
static_assert(sizeof(T) <= 8, "Only CAS with less than 8 bytes supported");
std::vector<T> mVec;
std::atomic<Head> mHead;
public:
fixed_size_stack(size_t size, T nullValue)
: mVec(size, nullValue)
{
mHead.store(Head(0u, 0u));
assert(mHead.is_lock_free());
assert(mVec.size() == size);
assert(mHead.load().readHead == 0);
assert(mHead.load().writeHead == 0);
}
/**
* \returns true if pop succeeded - result will be set
* to the popped element on the stack
*/
bool pop(T& result) {
while (true) {
auto head = mHead.load();
if (head.writeHead != head.readHead) continue;
if (head.readHead == 0) {
return false;
}
result = mVec[head.readHead - 1];
if (mHead.compare_exchange_strong(head, Head(head.readHead - 1, head.writeHead - 1)))
return true;
}
}
bool push(T element) {
auto head = mHead.load();
// Advance the write head by one
do {
if (head.writeHead == mVec.size()) {
return false;
}
} while (!mHead.compare_exchange_strong(head, Head(head.readHead, head.writeHead + 1)));
auto wHead = head.writeHead;
// Store the element
mVec[wHead] = element;
// Wait until the read head points to our write position
while (head.readHead != wHead) {
head = mHead.load();
}
// Advance the read head by one
while (!mHead.compare_exchange_strong(head, Head(wHead + 1, head.writeHead)));
return true;
}
/**
* @brief Number of elements in the stack
*/
size_t size() const {
return mHead.load().readHead;
}
/**
* @brief Maximum capacity of the stack
*/
size_t capacity() const {
return mVec.size();
}
};
原理比较简单,把index 原子化,我记得无锁circle buffer也是类似的技巧
这里不能用memory_order_relaxed 可能会有问题。默认就好
buffer_reader/buffer_writer
buffer_reader就是string_view buffer_writer就是rocksdb slice 带写拷贝
concurrent_map
实现思路 hash分段锁 ,然后内部 std::vector<Bucket>做value
Q 问题,个数怎么统计? 原子加减fetch_add/fetch_sub
实现的简单,主要是为了
Bucket实现
std::array<KeyValueElement, 1> arr;
std::vector<KeyValueElement, key_value_alloc> overflow;
arr保存kv overflow保存碰撞的数据
insert如果发生碰撞,返回false,统计计数对返回值做校验
这个map实现的非常cache friendly,就是不能大量碰撞,不然O1下降成On
现在越来越发现没有万能药,自己啥需求久实现什么容器
string
实现了个sso优化的string,类似libc++的实现。不多说
SingleConsumerQueue
类似fix_size_stack
std::array<Item, QueueSize> _data;
std::atomic_size_t _consumed;
std::atomic_size_t _insert_place;
主要就是移动这两个index,然后在array元素上placement new
bool isFull(size_t pos) {
auto size = pos - _consumed.load();
return size >= QueueSize;
}
template<class ...Args>
void writeItem(size_t pos, Args&&... recordArgs) {
auto real_pos = pos % QueueSize;
new(&_data[real_pos].value) T(std::forward<Args>(recordArgs)...);
_data[real_pos].is_valid = true;
}
bool read(T &out) {
size_t consume = _consumed.load();
if (consume + 1 >= _insert_place.load() || !_data[(consume + 1) % QueueSize].is_valid)
return false;
++consume;
Item &item = _data[consume % QueueSize];
item.is_valid = false;
out = std::move(item.value);
(item.value).~T();
_consumed.store(consume);
return true;
}
template<class ...Args>
bool write(Args && ... recordArgs) {
auto pos = _insert_place++;
while (isFull(pos)) {
usleep(1);
}
writeItem(pos, std::forward<Args>(recordArgs)...);
return true;
}
至于padding最佳模式没有研究,其实用alignas是不是可以
allocator
自己实现了个allocator用于hashtable分配内存
构成
std::atomic<std::atomic<uint64_t>*> active_cnt;
std::atomic<std::atomic<uint64_t>*> old_cnt;
std::atomic<std::atomic<uint64_t>*> oldest_cnt;
std::atomic<lists*> active_list;
std::atomic<lists*> old_list;
std::atomic<lists*> oldest_list;
借助构造函数和析构函数,这三个list来做阶梯式的回收,而不是立即回收,这样做有什么收益吗?碎片分布更均匀?
其中lists由list构成,就是一个数组 std::array<list, 64> lists_; 链表数组
具体的ptr怎么决定落在哪个index?
void allocator::free(void* ptr, std::function<void()> destruct) {
unsigned long long int t;
__asm__ volatile (".byte 0x0f, 0x31" : "=A" (t)); // rdtsc的汇编
active_list.load()->append(reinterpret_cast<uint8_t*>(ptr), t, destruct);
}
rdtsc拿到时间戳
题外话 不过现在拿都是直接用汇编, 比如dpdk里的实现
static inline uint64_t rte_rdtsc(void) { union { uint64_t tsc_64; struct { uint32_t lo_32; uint32_t hi_32; }; } tsc; asm volatile("rdtsc" : "=a" (tsc.lo_32), "=d" (tsc.hi_32)); return tsc.tsc_64; }比传统的写法快,和上面哪个.byte应该差不多 传统写法
static inline uint64_t rte_rdtsc(void) { uint32_t lo, hi; __asm__ __volatile__ ( "rdtsc" : "=a"(lo), "=d"(hi) ); return ((unsigned long long)lo) | (((unsigned long long)hi) << 32); }
然后去余数
void append(uint8_t* ptr, uint64_t mycnt, decltype(node::destruct) destruct) {
lists_[mycnt % 64].append(ptr, destruct);
}
如果想按照顺序回收,放在第一个槽,直接t=0就完了
void allocator::free_in_order(void* ptr, std::function<void()> destruct) {
active_list.load()->append(reinterpret_cast<uint8_t*>(ptr), 0, destruct);
}
在Table的PageManager用到了这个
也可以立即回收
void allocator::free_now(void* ptr) {
uint8_t* res = reinterpret_cast<uint8_t*>(ptr);
res -= sizeof(lists::node);
auto nd = reinterpret_cast<lists::node*>(res);
::free(nd->ptr);
}
pagelist hashtable用的这个
list由node构成std::atomic<node*> head_;
node就是基础的链表节点
std::atomic<node*> next;
void* const ptr;
std::function<void()> destruct;
own也是CAS,判定node是不是默认值,不是就要跳出去做insert,是就CAS标记
bool own(decltype(node::destruct) destruct) {
while (true) {
auto n = next.load();
if (reinterpret_cast<node*>(0x1) != n) {
return false;
}
if (next.compare_exchange_strong(n, nullptr)) {
this->destruct = destruct;
return true;
}
}
}
append也就是基础的链表加减操作
这里用了cas保证原子性
void append(uint8_t* ptr, decltype(node::destruct) destruct) {
ptr -= sizeof(node);
auto nd = reinterpret_cast<node*>(ptr);
if (!nd->own(destruct)) return; //判定是不是第一个,是第一个直接返回,不是就要CAS做链表的insert
do {
node* head = head_.load();
nd->next = head;
if (head_.compare_exchange_strong(head, nd)) return;
} while (true);
}
};
参考
- 论文地址 https://vldb.org/pvldb/vol10/p1526-bocksrocker.pdf
- https://zhuanlan.zhihu.com/p/393773578 小伙文章不错
