Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook
30 Mar 2020
|
|
根据ppt和论文总结一下
概述
如今KV应用非常广泛,然而
- KV数据集在不同的应用上有不同的表现。对现实生活中的数据集分析非常有限
- 同一个应用,数据集也是不断变化的,怎么采集分析这些变动?
- 基于上,如何分析真正的瓶颈在哪,如何提高性能?
方法和工具
- 方法 收集数据集,分析数据结构,简历数据集模型,对比,提高benchmark性能,调优
- 工具 trace collector, trace replayer, trace analyzer, benchmarks
论文基于三个rocksdb应用来分析
案例分析
UDB
facebook做的社交数据收集工具,底层是mysql on myrocks
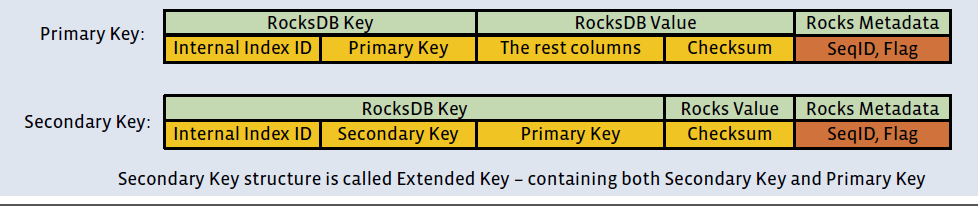
| rocksdb key | rocksdb value | |
|---|---|---|
| primary key | table index number + primary key | columns + checksum |
| secondary key | table index number + secondary key + primary key | checksum |
UDB的RocksDB通过6个ColumnFamily来存储不同类型的数据,分别是:
Object:存储object数据
Assoc:存储associations数据
Assoc_count:存储每个object的association数
Object_2ry,Assoc_2ry:object和association的secondary index
Non-SG:存储其他非社交图数据相关的服务
ZippyDB UP2X
rocksdb kv集群,用来保存AIML信息的
采集的数据类别
- 查询构成
- kv大小以及分布
- kv 热点以及访问分布
- qps
- 热key分布
- Key-space and temporal localities等等
由于上面的特性大多和业务相关,就不列举了。只列keysize
三个应用的 key size特点,都集中在一个范围 这不是废话吗
图太大不贴了,看ppt 15页
然后通过trace_replay重放数据集,自己构造一组类似的数据集,通过ycsb来模拟
具体怎么用的没有讲
ref
- 详细的论文描述看这里 https://www.jianshu.com/p/97d9bdd3cd4e 我只说了个大概
- https://www.usenix.org/system/files/fast20-cao_zhichao.pdf
- https://rockset.com/rocksdb/RocksDBZhichaoFAST2020.pdf?fbclid=IwAR0j6IpFrZ_hiYJOJLf5bMENUC2v86LUw69KWh_0ZBvQxMqWiDahyb0IYDw
- 文章中提到的工具在论文引用里介绍了,wiki 页面 https://github.com/facebook/rocksdb/wiki/RocksDB-Trace%2C-Replay%2C-Analyzer%2C-and-Workload-Generation 有机会可以试试
