(译)针对 Redis on Flash 优化RocksDB
原文 Optimization of RocksDB for Redis on Flash 作者Keren Ouaknine, Oran Agra, Zvika GuzCCS Concepts Information systems → Key-value stores; Database performance evaluation; Keywords: Databases, Benchmark, Redis, Rocksdb, Key-Value Store, SSD,NVMe
0. 概述
RocksDB是一个热门的KV存储引擎,针对高速存储设备做了优化,随着SSD变得流行prevalent,RocksDB获得了广泛的使用(widespread adoption)现在在生产环境中很常见is now common in production settings,尤其是许多软件栈嵌入RocksDB作为存储引擎来优化访问块存储。不幸的是,调优RocksDB是一个复杂的任务,涉及到许多不同依赖程度的参数involving many parameters with different degrees of dependencies. 在我们这篇论文中,一个调优好的配置可以使性能比基线配置参数的表现提高一个数量级by an order of magnitude
在这篇论文中,我们将描述我们在优化RocksDB在Redis on Flash(RoF)上的经验。RoF是一个Redis用SSD作为内存拓展的商业实现,用以动态提高每个节点的容量效率。RoF用来存储载内存中的热数据,利用RocksDB存储管理SSD上的冷数据。我们将描述我们在调优RocksDB参数使用上的方法,展示我们的的经验和发现(包括调优结果的利弊),使用两个云,EC2和GCE,综上,我们会展示如何调参RocksDB提高RoF数据库的复制实践11倍以上。我们希望我们的经验能帮助到其他使用,配置和调优RocksDB来认识到RocksDB的全部潜能
1. 介绍
RocksDB是一个持久化KV存储特定面向告诉存储,主要是SSD而设计[1]。从LevelDB[2]分支出来,RocksDB提供了更好的性能[3],被设计成高度灵活来方便嵌入高层应用的一个存储引擎,事实上,许多大规模产品使用RocksDB来管理存储,Leveraging借助它的高性能来mitigate缓和日益增长的存储系统的压力[4]
不幸的是RocksDB的灵活性和高性能也有代价:调优RocksDB是一个复杂的任务牵扯到上百个参数且有varying不同程度的内部依赖,此外,“然而最近的改动使RocksDB变得越好,比起levelDB它配置就越困难”;表现差的场景太多是错误的配置造成的。[5]
当使用RocksDB,经常被问到的问题主要有
- 哪些配置参数使用在哪个硬件或那种工作场景下的?
- 这些参数的最佳
optimal参数是什么 - 这些参数是内部独立的吗(比如说,调优参数a只在参数b,c,d有特定值的事后才生效)
- 两个不同的调优是累积
cumulate正优化还是负优化? - 如果有的话,这些参数调优后的副作用是什么?(
last but not least最后但不是不重要)
这篇论文试图回答这些问题,通过分享我们在RoF上优化RocksDB的经验[6,7]–这是一个Redis内存KV存储的一个商业拓展[8]。RoF用SSDs作为内存RAM的拓展来提供可媲美内存Redis变小的性能,在动态增长扩容数据集的时候数据也能存在一个单点服务器上。在ROF,热数据存储在内存中,类数据存储在SSDs中,由RocksDB来管理。RocksDB能处理所有ROF访问存储,它的性能在整个系统性能中占了主要角色。尤其是低访问的局部场景。因为ROF致力于提供可以媲美纯内存Redis表现的性能,调优RocksDB便成了首要挑战
在调优RocksDB适配ROF的过程中,我们分析了大量的参数并且测试了它们在不同工作模式下对性能的影响。数据库复制,只写模式,1:1读写模式。为了验证我们配置在不同硬件环境下的健壮性,我们测试了Amazon Elastic Compute Cloud (EC2)和Google Compute Engine(GCE),综上,我们的调优减少了复制一个节点的时间(11倍)这篇论文来描述方法,调优过程和产生效果的参数设置
在第三段,我们将描述我们的方法并解释我们的实验过程。第四段,我们会列出载性能上有最大正相关的参数。我们也列出了一些我们期望提高性能但实际上降低了或者you其他副作用的参数。我们相信这些信息会帮助到他人。然而我们的经验只限于RoF场景中,我们期望相似的系统用相似的配置,希望我们的方法和结果会帮助减少调优的时间
综上,这篇论文会有下面的产出
-
我们发表我们在EC2和GCE上 在一系列工作集下 RocksDB benchmark的结果和分析
-
我们描述了我们的条有过程,对性能有有最大影响的的参数,和最佳参数;并且
-
我们描述了调优的负面结果,或不成功,降低了性能,或有非直观的副作用
2. 背景
这段简要回顾下Redis,Redis on Flash,和RocksDB,描述这些系统的上层架构,提供简要北京以帮助理解这篇论文的细节
2.1 Redis
Redis[8]是一个热门的开源内存KV村春提供了高级键值抽象,Redis是单线程的,只能在同一时间处理同一个玲玲。不像传统的KV系统(键只是个简单的数据类型,通常是字符串),Redis中的键can function as可以是复杂的数据类型,像hash,list,set,或者sorted set,furthermore此外,Redis可以使用复杂的原子操作,像是对列表的入队出队操作,在sorted set插入一个新值等等
事实证明,Redis的抽象和高速在许多延迟敏感的场景中特别有用,因此,Redis得到了广泛的使用,越来越多公司在生产环境中使用redis[9]
Redis支持高可用和持久化,高可用通过主从节点同步复制来实现,故障转移(failover),当主程序挂了,子程序能相应的接管过来。持久化可以通过以下两种方法配置
- 实时快照文件(RDB)
- 使用log文件(AOF)
要注意这三种机制(AOF重写,RDB快照,复制)都依赖于fork进程来处理一个时间点上的快照,(与此同时主程序继续处理客户端命令)
2.2 Redis on Flash (RoF)
像Redis这种内存数据库通常把数据保存在内存中,数据库快了但是也很贵,因为1内每个节点的内存容量有一定限制2每GB内存价格很贵。Redis on Flash(RoF)是一个Redis的商业拓展,用SSDs来作为内存的拓展,来高效的动态增加单个服务器上数据集大小。RoF完全兼容Redis并实现了所有的Redis命令和特性,Rof用和Redis相同的机制来保证高可用和持久化且依赖于SSD(非易失性闪存)
RoF把热数据保存在内存中,把冷数据持久化到固态硬盘上。它使用RocksDB作为存储引擎,所有的固态硬盘通过RocksDB来管理,通过RocksDB接口来访问硬盘上的值。当一个客户端请求一个冷的数据,请求会被临时阻塞直到designated指定的RoF I/O线程 将I/O请求提交到RocksDB,在此期间,Redis的主线程继续处理其他客户端的请求。
2.3 RocksDB
RocksDB[10] 是一个C++实现的开源的KV存储,它提供get/put/delete/scan 键值的操作。RocksDB可以保存大量的数据,它使用sst(sorted static table)来将数据保存到NVMes,SATA SSDs,或者机械磁盘上,尽可能的降低延迟。RocksDB使用布隆过滤器来判定键在哪个sst文件中。为了避免随机写,它将数据积累到内存中的memtable中,然后一次性刷写到硬盘中。RocksDB的文件是不可变的,一旦生成就不会继续写该文件。记录不会被更新或者删除,会生成一个新文件。这会在硬盘生成一些多余的数据,会需要数据库Compaction(压缩),Compaction文件会移除冗余的键值对并腾出空间,如图所示
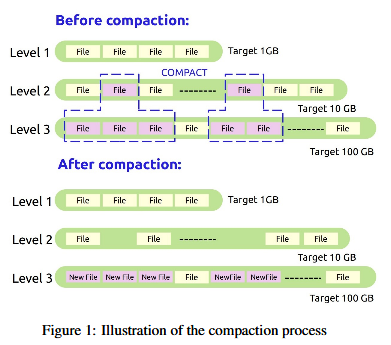
2.3.1 RocksDB架构
RocksDB用不同的排列组织数据,也就是层level,每层都有个目标大小,每层的目标大小增长倍数是相同的,默认是10倍,因此,如果第一层目标大小1g,那么2,3,4层大小就是10g,100g,1000g,一个键可能出现在不同的层,随着compaction,但是越新的值层越高,越旧的值层越低
RocksDBinitially首先将新的写入存储在内存memtable中,当memtable写满了,他会被转成不可写的memtable,并插入到落盘流程(flush pipeline)中,同时,分配一个新的memtable给后面的写,第0层就是memtable,当第0层满了,数据就会被compact,挪到下面的层中,compaction流程应用到所有的层,将文件从层n合并到层n+1
2.3.2 放大因子
我们通过检测各种工作负载实验下的吞吐量和持续时间来测评优化带来的影响。此外,我们基于以下RocksDB定义的放大因子定义来监测副作用
读放大是从硬盘中(包括数据compaction中的读)读的数据 比 从KV存储中的读的数据写放大是总的硬盘中的写入数据 比写入KV存储中的数据空间放大是硬盘上总的数据文件比 KV存储的大小
2.3.3 memtier benchmark
Memtier benchmark[11]是一个benchmark工具,我们用它测量Redis流量。这是Redis实验室[12]开发并开源的, 它可以发送各种比例的读写,实现了不通模式的流量模式,比如连续,随机,高斯分布等。这个工具维护了一个一个Redis命令的pipeline,保证当回复响应时发送一个新的请求。这个命令行工具也提供堆请求流的各种程度的控制,比如操作数,读写比率,工作线程数,客户端数量,值大小等等。在每次运行的结尾,他会报告所有读写吞吐量的平均值和他们的延迟。
3. 方法
当我们优化RocksDB,我们首先的动机,以及我们首要的优化目标是减少ROF数据库复制的时间。复制流程在保证主节点高可用是必要的,且包含以下两个步骤,1从主节点服务区读取整个数据集并发送到网络中的其他从节点,2从节点服务器写入数据集。一旦首次复制流程完成,所有的后续的反动都会从主节点发送到从节点来保持和主节点的同步。当(假如)主节点挂掉了,从节点会成为新的主节点,新的从节点进行复制,这样整个数据库保持容错。因此,复制事件是很重要的,因为1复制流程期间由于主节点开始忙碌的读和发送数据,整个集群在一个低性能的状况中,且2这会有数据丢失的风险,因为当前主节点挂了,无法进行数据复制。
使用默认的RocksDB设置,复制50g数据,内存:固态比10:90的情况下会使用whoping特别长的212分钟。对我们的场景来说这是不可容忍的时长,应该降低到30分钟以内,在第四段中,我们将描述我们在配置中所处的更改,降低复制时间到18分钟。因为真正的生产环境通常单个Redis服务器有50g左右的数据,所以我们用50g数据来实验。
当我们首要的目的是减小数据库复制的时间,保证我们的系统稳定性能是十分必要的imperative,因此,每次每次优化,我们都会测量四种工作负载场景
-
只写,写50m key,1k value,总共50g,这个压力代表所当前常用的数据库规模
-
只读,读10%的数据集
-
benchmark,混合读写,50-50
-
数据库复制,从主节点读50g写入从节点
使用这些工作模式,当我们的优化效果能显著提高第四个并且没有降低其他三个,我们接受这个结果。
优化流程第一步是确定瓶颈。因为数据库复制主要是主读从写,我们只分析这两种操作。我们跑两个实验,1主节点书全部存在内存,硬盘写只发生在从节点(这个实验叫纯内存主节点),2所有从节点数据都存在内存,硬盘压力都在主节点的读上(这个实验教纯内存从节点),比较两种场景的持续时间。帮助我们更好的优化,来达到减少复制时间的目的
我们也分析服务器的活动:我们统计每次调优过程中的运行时间,吞吐量和延迟。我们也检测各项系统指标,Redis和RocksDB的线程负载,IO状态,RocksDB的每层的状态,放大因子,放慢速度和写停止the slowdowns, and the write stalls.这些指标帮助我们去测量评估每次优化后的副作用,选择不使用opt-out那些降低性能的调优参数(见第四段)
硬件:我们所有的实验都泡在EC2和GCE云上,EC2是广泛使用的云服务器,我们使用i2.8x Large 32vCPU 244GB内存,8x800GB SSD,10g加强型网络带宽,此外我们使用的GCE用的是EC2上用不到的NVMe硬盘,同样采用32vCPU,Intel Xeon 2.20GHz, 208g RAM,8x375gb NVMe。
4. 测试和结果
这小节描述我们的测试过程和我们在优化期间的发现。首先 4.1小节我们通过实验详细的介绍了显著提高性能的两个参数和一个本以为能提升性能却带来负面影响的参数,这些实验是在EC2伤实验的,在4.3我们重复该实验在用NVMe的GCE上
在Throughout这节中,粗体字是RocksDB调优实验, 引用是RocksDB配置项的名字(knob name),它们的影响列在下表中
| 参数parameter | 名字 | 初始值 | 改过的新值 | 性能影响 |
|---|---|---|---|---|
| Compaction threads | max_background_compactions |
8 | 64 | 24% |
| Slowdowns | level0_slowdown_writes_trigger |
12 | 24 | 10% |
| Stops | level0_stop_write_trigger |
20 | 40 | 10% |
| Compaction readahead | compaction_readhead_size |
0 | 2MB | 300% |
| Redis IO threads | Redis IO threads | 8 | 64 | 500% |
| RAID chunks | chunk | 512k | 16k | 68% |
| filter for hits | optimize_filters_for_hits |
0 | 1 | 7% |
| bulk mode | prepare_for_bulk_mode |
0 | 1 | 500% |
| Block size | block_size |
4k | 16k | 60% |
| Synchronization | bytes_per_sec |
0MB | 2MB | 0% |
4.1 在EC2 上使用SATA接口SSD
我们的RocksDB基线配置用的RocksDB4.9和几个和默认参数不同,列在下表中
| Parmeter | value |
|---|---|
| memtable budget | 128MB |
| Level 0 slowdown | 12 |
| max open files | -1 |
| WAL | disabled |
| OS buffer | disabled |
| Cache | disabled |
这些在开始阶段就设定了,是有一定的原因的,因为Redis on Flash用内存来缓存,所以我们禁用了RocksDB的cache,没有必要同一个值缓存两次。我们也禁用了OS缓冲(buffer)来保证写在内存缓冲或者直接写入硬盘。另外一个有效的改动是禁用WAL通过(rocksdb_writeoptions_disable_WAL),在我们这个场景下WAL有消耗但是用不到,Redis on Flash本身就保证了一致性,无需使用WAL。
4.1.1 最大化并行来消除瓶颈
开始优化,我们先降低每个线程上的负载来降低高CPU利用率high CPU utilization
我们让RocksDB后台县城和Redis I/O线程一样多,增加他们的并行性来防止他们成为瓶颈
RocksDB后台线程主要是两个函数,compaction 工作和刷到硬盘(flush job),在图片2可以看到, 使用max_background_compaction从把compaction 线程8改到64,性能提高24%,我们观察到compaction越并行化,compaction周期就越短,写就有更高的吞吐量。我们也针对flush线程(拷贝数据从memtable写到硬盘)做了测试,他们的并行化并没有显著的提高性能。
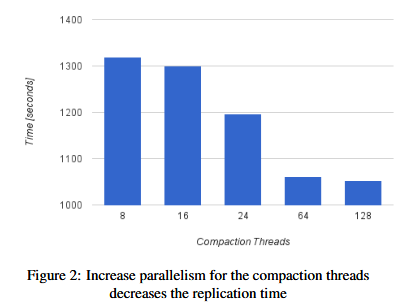
4.1.2 稳定吞吐量和延迟
下一步,我们尝试稳定系统的性能,即(namely)在吞吐量和延迟方面降低服务器性能差异variance。在图三,我们能观察到服务器吞吐量上断断续续stop-start的现象,每十秒有着50k ops/sec低于10k ops/sec。这个表现也显示出长尾延迟,即少量请求造成长时间的响应
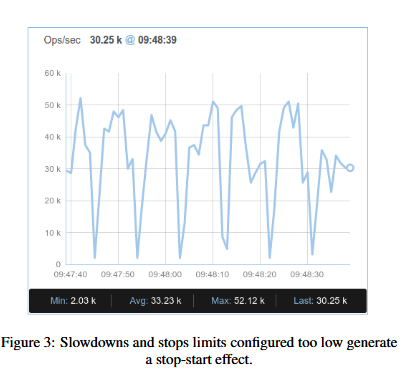
正如预期,是compaction周期造成这种流量。这有由于level 0 文件到达上限产生的。比如说level0_slowdown_writes_trigger(默认12),当这个上限很低,compaction就会很频繁,就会扰乱流量,就像在图三中看到的那样。在另一方面,如果这个上限过高,我们积累的需要compaction的量(debt)就比较多,最终会造成RocksDB触发level0_stop_write_trigger 阻塞所有流量数秒。对于ROF,她最好有较慢但稳定的吞吐量载整个期间避免stop-start和写阻塞,一个例子,在图4中显示了一个稳定的吞吐量几乎没有出现1-2k ops/sec的情况
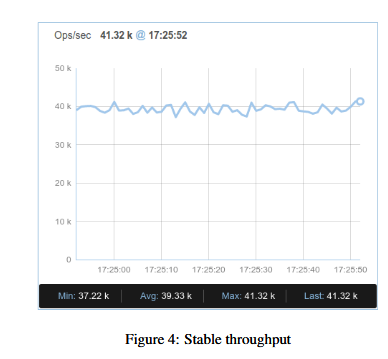
我们实验了不同的参数来调优slowdown和stop,我们观察到了很高的吞吐量,当我们继续提高这个参数的时候,又造成了负优化导致积累了太多的compaction debt,结果在图5中显示,最优的参数是slowdown=24和stop=40,给我们带来了10%的性能提升。Compaction参数后面的值(slowdown=40,stop=60)表现出更快的复制但是在只读工作集种对于吞吐量带来了负面影响。在延迟的compaction的场景下,访问时间会变长,因为bloom filter页更大,数据也没压缩。
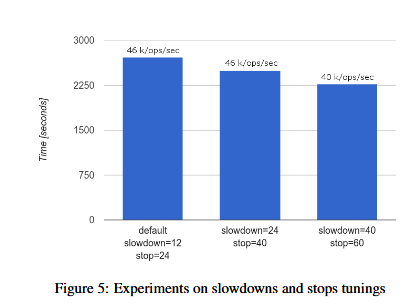
4.1.3 产生更大的吞吐量
compaction预读选项(compaction_readahead_size)起用能在compaction过程中 读取大的compaction inputs。默认RocksDB不使用预读(0MB),我们使用2MB readahead进行实验获得了缩短三倍复制时间的效果。前文提到,compaction效率受到RocksDB吞吐量的影响。此外,我们通过调整RedisIO线程数获得了更好的输出,因为RocksDB的API是同步的,我们使用多路IO线程模型来提高IO并行化,我们发现提高RedisIO页提高了读请求的延迟,但是这个提高也带来了memtable的争用,导致显著降低了写请求的性能。
因此我们决定用单线程IO来处理写,用其余的IO线程来处理并发读(一写多读 , one writer),这个提升提高了五倍。
因为RoF会部署在多个存储器组合的设备来增加存储带宽,我们也在各种RAID设置的环境中做了实验。RoF使用(employ)RAID-0来压缩卷,我们在不同的压缩块大小的环境中测试比较了性能。见图6,RAID 越小的块chunk越能提高硬盘的并行程度以及性能,因此,我们将默认的512kb改成16kb,从而提高了68%。注意RocksDB调优指南建议使用大的块大小(chunk size)[14],我们的实验结果正好相反,越小的块性能越好
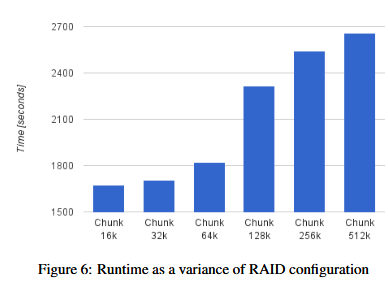
最后,因为RoF 把所有key和他们的位置放在了内存中,向RocksDB的请求不会错过(miss),请求不可用的key会被ROF处理,只有请求已知在硬盘上的数据才会转发到RocksDB子系统,因此,我们开启了RocksDB特定designated的bloom filter配置项来优化这个场景, optimize_filters_for_hits。RocksDB实现的布隆过滤器对于每个SST文件会快速检查搜索的key是否在该文件中存有一份,这个优化去掉了对最底层的过滤,因为一旦请求来到这层,那值肯定就在这层。这个优化会对复制性能带来7%的提升。
4.1.4 读速度
当复制一个数据库,主节点发送数据集的一个副本给从节点,主节点需要把硬盘和内存中的值都读出来。这有两种方法来从硬盘中读数据,第一种就是使用RocksDB的迭代器来按照顺序读RocksDB数据库文件,第二种方法就是读那些值不在内存中的,这降低了总的读但是增加了随机读。我们主要根据下面两个条件来对这两种方法进行取舍
- RocksDB在两种场景下的性能
- 顺序读和随机读下的硬盘速度
图7 画出了在复制过程中剩余的keys在内存中还有多少来比较这两种方法。x轴越长表示数据在闪存硬盘中(不在内存中)的比例越高。在顺序读RocksDB数据集的场景下,所有实验场景下,复制时间很稳定(大致保持不变stays roughly constant)(蓝线),相反,随机读只向硬盘访问必要的数据的方法下,复制时间随着闪存硬盘中数据的比例而线性上升。图中可以看到,随机读仅在内存中有85%数据以上的场景下表现较好,顺序读载配置了预读后有效果提升,读取大的块(chunk)能加速顺序读,上述结果在不同的数据集合对象大小表现是一致的。我们采用顺序读作为复制方案。
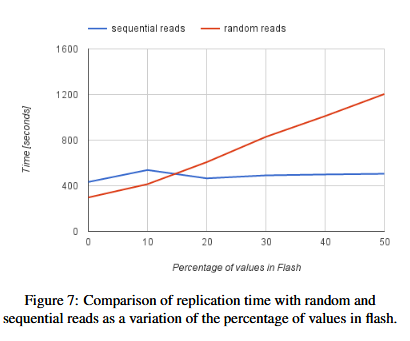
4.2 负优化结果
许多参数我们试验后决定不采用,不仅是因为他们没有减少肤质是件,反而还有副作用,在这个小结,我们列举三个调优过程中反直觉counter-intuitive或造成意外副作用的几个场景
我们开始在(批量写?)bulk load模式上开始调优(prepareforbulkload),开启这个模式提高了复制时间五倍,然而,bulk load 模式有副作用,会使读变得特别慢(prohibitively slow),因为这个模式禁止了压缩,如果数据集不压缩,就会有非常多的SST文件,需要非常多的读取。我们在复制结束试着关掉bulk load启动手动compaction来恢复数据库可用,但是手动compaction是一个单线程处理,会花费很长时间来完成,比复制时间还要长,我们采用自动compaction,多线程,但是后续subsequent的读仍然很慢。
意外的是,这两种compaction最终结果不一样,第一种花费较长时间,第二种产生较低的读取,此外也没有权利compaction。还记得4.1.2我们遇到的类似的compaction debt问题吗。Bulk mode(13)是有许多不同的调优参数组成的is composed of,我们分别测试各种参数来试试能不能带来好处。然而,禁用compaction被证明是性能提升背后的主要原因,我们就放弃了这个配置选项。
全同步在RoF不是必须,因为我们使用闪存硬盘作为内存扩展,因此,我们针对全同步消耗来进行调优,我们配置了2MB同步一次,bytes_per_sync,意外的是,我们没观察到任何提升,我们用dd写数据到硬盘,我们比较了写入50g数据不开启同步的时间,发现性能提升了2倍,在复制实验中没有类似表现,我们有点困惑。我们猜测写被缓存了(cached)因此我们看不到同步的优化(saving),但是查看meminfo我们观察到数据没被缓存 ,我们也看了其他设备RAID和他们的iops,也没有降低。最后我们用strace确定确实没有同步动作。这个反直觉的现象仍然是个谜。
最后,我们调了block_size参数,每个SST文件包含索引和他自己的block,增加块(block)大小可以减少每个文件中索引的数量。但是块大了读取会变多(见2.3.2读放大),增加了block大小也减少了内存使用,因为内存中的索引更大了(?),默认的块大小是4kb,当我们block调到16kb,我们观察到了60%的降低,不像其他参数可以在运行时动态调节,block大小修改不能撤销(编译进去的)所以我们观测到了在读性能上的负面影响后我们就结束了这个调优。
4.3 在GCE NVMe SSD上的实验
在EC2上的调优经验也帮助我们在GCE上进行试验,首先我们调整RAID优化,我们把之前的在chunk 大小上的经验直接搬过来(a sweep of),证实了16kb确实是最优参数,能将复制时间提高41%。
默认的level0_slowdown(12)和stop(20)延迟写是不必要的。当我们达到12个文件后,延迟写在吞吐量上面的表现非常明显,从60k降到600 ops/sec 直到compaction工作结束才恢复。为了避免系统的这种stop-start现象,我们增加了这两个参数到20 24,观察到性能提升了15%(类似EC2)
此外,我们加上了其他调优,比如优化filter等等,我们也加了RocksDB compaction线程和Redis IO线程,配置了一个写者 (one writer),增加了数据预读。这些改动累积效果,复制时间缩短到12分50秒,相同的数据规模在EC2上同样参数配置用了18分钟。不过硬件参数也不同,SATA-SSD和NVMe SSD,我们认为GCE本应该有更快的复制时间
5. 相关工作
虽然也有其他可用的存储引擎[15,16,17],RocksDB有着更好的性能而得到了广泛的使用,RocksDB调优指南[18]提供了RocksDB[10]基本的配置指引,也是我们测试中的基本配置。在我们的这篇论文中,更进一步的调优带来了可观considerably的性能提升(我们的例子中是11倍)
krishnamoorthy和Choi[19]做了在NVMe SSD上调优RocksDB的工作,据我们所知,这是最接近我们论文展示的工作,然而,他们的分析是在RocksDB压力测试场景下的,我们的优化是在工业实践(用RocksDB做后端引擎)场景下的。所以,两者的调优过程和结论也有所不同。
类似Redis on Flash,也有一些Redis的拓展使用了闪存硬盘为Redis提供拓展能力,在Intel的项目[20],也是Redis分支,依赖SSD来提供持久化,动机是消除eliminate硬盘备份写硬盘的同步代价而采用了AOF策略,如果有个节点故障,机器会通过固态硬盘上的数据来修复。这个方法不能用在云设备上,因为机器不能复用/修复。Redis原生硬盘存储(Naive-Disk-Store)使用LMDB[17]来管理硬盘上的数据,数据是周期性的刷到硬盘上的,如果一旦故障仅会丢失最后一次没刷盘的数据。它不会把key存到内存中也不支持持久化复制,定期删除,scan。
6. 结论
随着使用RocksDB作为存储引擎的应用越来越多,Rocksdb也是选型存储引擎的首选,然而,灵活和高性能是有代价的,调优RocksDB是个复杂的工作,在我们这篇论文中,调优好的配置要比基本配置表现好出一个数量级
在这篇论文中我们使用Redis on Flash 一个热门Redis KV存储的一个商业拓展,作为调优RocksDB的研究用例,我们描述条有方法,调优过程,和RocksDB设置上的改动点,使得RoF性能提升11倍以上,实验还展示了可能会导致负面效果或预料之外副作用的的配置。然而不同的使用场景有不同的最优配置,我们希望我们的经验会帮助其他人来优化RocksDB,提高新更能,减少研发时间。高度调优的Rocksdb的性能提升绝对值得付出这些工作。
7. 援引
[1] Siying Dong. RocksDB: Key-Value Store Optimized for Flash-Based SSD.https://www.youtube.com/watch?v=xbR0epinnqo. [2] RocksDB and LevelDB. http://rocksdb.org/blog/2016/01/29/compaction_pri.html. [3] Paul Dix. Benchmarking LevelDB vs RocksDB. https: //www.influxdata.com/benchmarking-leveldb-vs-rocksdbvs-hyperleveldb-vs-lmdb-performance-for-influxdb/. [4] RocksDB users. https: //github.com/facebook/rocksdb/blob/master/USERS.md. [5] Mark Callaghan blog. http://smalldatum.blogspot.co.il/2014/07/benchmarking-leveldb-family.html, July 7, 2014. [6] Redis on Flash documentation. https://redislabs.com/redis-enterprise-documentation/rlecflash. [7] Redis on Flash. https://redislabs.com/rlec-flash. [8] Redis. http://redis.io/. [9] Redis Users. http://techstacks.io/tech/redis. [10] RocksDB website. http://rocksdb.org/. [11] Memtier benchmark. https://redislabs.com/blog/memtier_benchmark-a-highthroughput-benchmarking-tool-for-redis-memcached. [12] Redis Labs. https://redislabs.com/. [13] Gartner. Magic Quadrant. https://www.gartner.com/doc/reprints?id=1-2G2O5FC&ct=150519. [14] RocksDB FAQ.https://github.com/facebook/rocksdb/wiki/RocksDB-FAQ. [15] Kyoto Cabinet. http://fallabs.com/kyotocabinet/. [16] LevelDB. http://leveldb.org/. [17] Lightning Memory Mapped Database.https://lmdb.readthedocs.io. [18] Facebook. RocksDB Tuning Guide. https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide. [19] Praveen Krishnamoorthy and Choi Changho. Fine-tuning RocksDB for NVMe SSD. https://www.percona.com/live/data-performance-conference2016/sites/default/files/slides/Percona_RocksDB_v1.3.pdf. [20] Intel. Redis with persistent memory. https://github.com/pmem/redis#redis-with-persistent-memory. [21] Redis Naive Disk Storage.https://github.com/mpalmer/redis/blob/nds-2.6.
