深入理解计算机系统 读书笔记
csapp 不多说了。早就该读完了
计算机系统漫游
-
信息就是位 + 上下文
-
程序被程序翻译成不同的格式
-
了解编译系统
- 优化系统性能
- 看懂链接报错
- 避免安全漏洞
-
处理器读并解释存储在存储器中的指令
- 典型的系统硬件组织
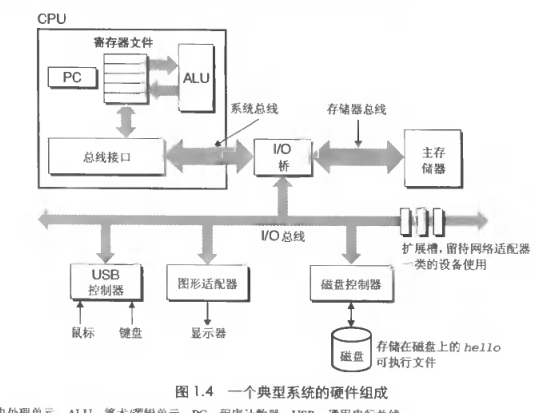
总线bus 传word
IO
内存 DRAM
cache SRAM
程序结构和执行
信息的表示和处理
信息存储
-
寻址和字节顺序
- 大端小端
01 05 64 94 04 08 add %eax, 0x8049464-
整数和浮点的不同表达

-
布尔袋鼠 ,布尔环,位运算
-
无符号与二进制补码 -128 127
- 无论哪种解码方式, 都是字节码的解释而已
-
扩展一个数字的位表示
- 零扩展
- 符号扩展
-
浮点
程序的机器级表示 基于IA32
-
反汇编
-
数据格式
-
字word 16位 double word 32位
-
三种GAS后缀,
movb字节movw字movl双字 -
操作指示符 operand
- 立即数 immediate $0x1F
- 寄存器 eax
- 存储器引用 地址
-
数据传送指令
- mov
movl $0x4050, %eax 立即数 ->寄存器 movl %ebp, %esp 寄存器->寄存器 movl (%edi,%ecx), %eax 内存->寄存器 movl $-18, (%esp) 立即数->内存 movl %eax, -12(%ebp) 寄存器->内存 - push %ebp
subl $4, %esp movl %ebp,(%esp)- pop
movl (%esp), %eax addl $4, %esp
-
-
算术和逻辑操作
-
加载有效地址 lea aka load effective address 我还以为是leave
-
xor %eax ,%eax赋0指令 效果 描述 leal S, D D = &S 加载有效地址 incl/decl/negl/notl D D=D@1 加一减一 add/sub/imul/xor/or/and S,D
-
-
控制
- 条件码
cmptestset
- 跳转
jmpjejgjljajb- 跳转表
- 条件码
-
过程
-
栈帧
-
转移控制
-
callleaveret;leave movl %ebp, %esp popl %ebp
-
-
寄存器使用惯例
%ebp%esp必须保存%eax%edx%ecx调用者保存寄存器caller save%ebx%esi%edi被调用者保存寄存器callee save
-
递归
-
-
数组?
-
movl (%edx, %eax, 4), %eax
-
指针运算 假设数组E的起始地址和索引i分别在
%edx和%ecx中表达式 类型 值 汇编 E int * xe movl %edx, %eax E[0] int M[xe] movl (%edx), %eax E[i] int M[xe + 4i] movl (%edx, %ecx, 4), %eax &E[2] int * xe+8 leal 8(%edx), %eax *(&E[i] + i) int M[xe+ 4i + 4i] movl (%edx, %ecx), %eax &E[i]-E int i movl %ecx, %eax -
数组循环
- 减少imul
- 优化递增变量
-
-
异类数据结构
- 编译时算好偏移
-
理解指针
- 越界
-
浮点算术
- 浮点寄存器
- 栈表达式求值用到的寄存器
-
c中嵌入汇编
处理器体系结构
-
定义一个简单的指令集,就叫它Y86吧
- %eax, %ecx $edx %esi $edi %esp %ebp
- 条件码 ZF SF OF
- 程序计数器PC
- 存储器,内存,数组代替
- 汇编设计
- mov按照mov的类别设计 irmovl(立即数 →寄存器) rrmovl(寄存器→寄存器) rmmovl(寄存器→内存) mrmovl (内存→寄存器)
- opl addd sub and xor
- jxx
- call ,ret
- pushl, popl
-
逻辑电路
- 布尔逻辑
- 存储器和时钟控制
- 集合关系
-
Y86的顺序实现
-
取指,fetch 从PC中拿到地址,从地址抽出指令指示符 icode ifun
-
解码decode 从寄存器里读
-
执行 execute 算术逻辑单元(ALU)执行指令指明的动作(ifun)或者移动栈指针或者跳转
-
访问内存memory
-
写回寄存器
-
更新PC
阶段 opl rA, rB subl %edx, %edx 取指 icode:ifun <- M[PC]
rA:rB <- M[PC+1]
valP <- PC+2icode:ifuicode:ifun <- M[0x00c] = 6:1
rA:rB <- M[0x00d] = 2:3
valP <- 0x00c+2 = 0x00e解码 valA <- R[rA]
valB <- R[rB]valA <- R[%edx] = 9
valB <- R[%ebx] = 21执行 valE <- valB op valA
Set CCvalE <- 21 - 9 = 12
ZF <- 0, SF <- 0 , OF <- 0访存 写回 R[rB] <- valE R[rB] <- valE = 12 更新PC PC <- valP PC <- valP=0x00e
其他流程类似,不过是获取值通过ALU实现
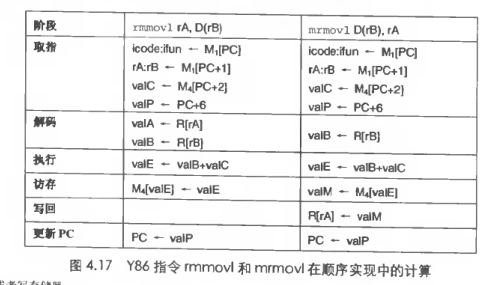
-
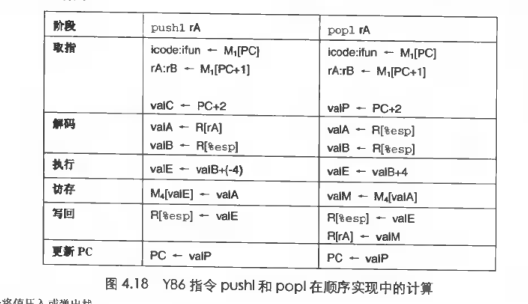
一种实现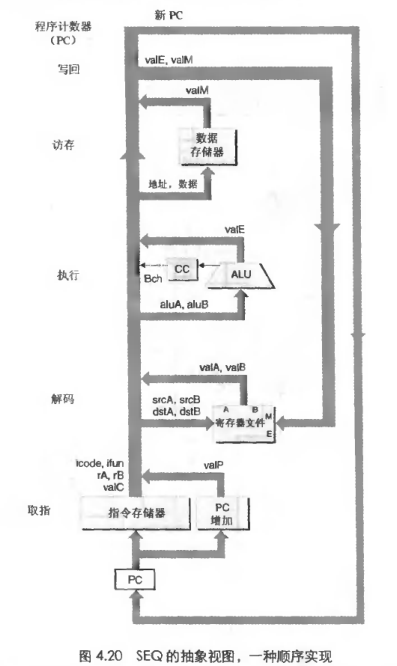
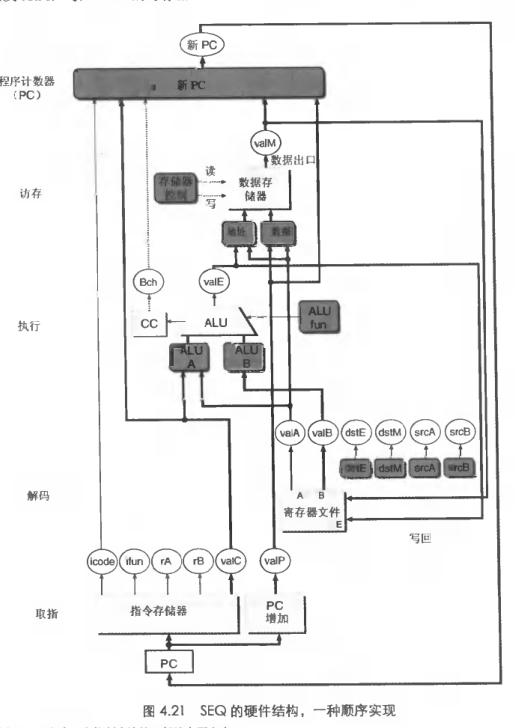
-
时序
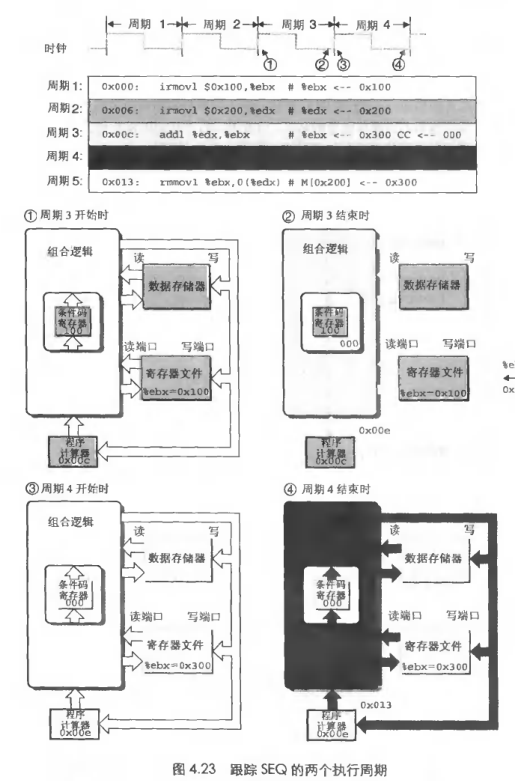
后面在设计电路了。理解PC
-
流水线的通用原理
- 时钟驱动组合逻辑
- 流水线过深,收益反而下降
- 指令控制
- 指令重排
- 预测PC
- 分支预测
- hazard
- data hazard
- 读写阶段不同造成寄存器错误
- 条件码
- PC
- 存储器写回
- control hazard
- 解决方案
- stall nop nop 吞吐降低
- 转发
- data hazard
第四章真是太他妈复杂了。讲cpu 指令集 流水线怎么设计
优化程序性能
-
优化编译器的能力和局限
*xp += *yp; *xp+=&yp;和*xp += 2* *yp在xp=yp时优化效果不同,因为编译器必须假定指针使用不同的寄存器memory aliasing- 表示程序性能,CPE
-
消除循环
- 循环不变量优化,经典问题了。
- 减少调用
- 消除不必要的寄存器引用
- 循环中访问指针可能不会被优化,导致多次访问指针。
- 降低循环开销
-
转换到指针代码
- 通过指针改善数组效率?
-
提高并行度
- 循环展开
- 这种优化的性能提升有上限。为什么?
- 循环展开
-
分支预测和预判错误处罚
-
理解内存性能
- save & load
- 设计。数据结构和算法影响性能
- 消除连续函数调用(浪费堆栈)以及计算放到循环外,不必要的寄存器引用以及引入临时变量保存中间结果
- 循环展开,迭代分割,数组换指针
-
确认和消除性能瓶颈
- profiling -pg
内存层次结构
-
存储技术
- DRAM 实现内存
- SRAM 实现cache 弥补cpu内存之间的的差距,带来局部性
-
局部性
- 利用局部性
-
内存层次结构
- cache 读成cash,卧槽,我一直读错了??
- cache的命中,缓存策略,置换策略LRU等等。这里的概念讲的很少。有专门的书讲这个
- cache 读成cash,卧槽,我一直读错了??
-
cache
- cache set, cache line
- direct-mapped cache
- 字选择,
- 行替换,击中直接替换当前行
- 这里细节比较复杂,还好有图说明。可以找出pdf来看。这里不解释了。看不懂。后面还有书来讲这个,到时候仔细看
- set associative cache组相联
- 行替换,LRU/LFU
- fully associative cache
- 做TLB
- 写
- 怎么写
- 写回write back 需要标志位dirty bit记录cache block是否被修改过
- 直写 write through
- 写不命中
- 写分配or写不分配
- L1 icache dcache L2 university cache
- 性能指标
- 命中率/不命中率
- 命中时间
- 不命中惩罚 miss penalty
- 影响因素
- cache越大越容易命中,但是增加命中时间
- 块儿越大命中率高一些,提高空间局部性,但是占用大,行数少,降低时间局部性
- 相连度,高相联度带来慢的速度,增加命中时间,但是高相联度冲突不命中影响低
- L1直接映射,L2组项联,L3直接映射
- 写策略,直写快但是浪费,写回带宽高但是复杂
- 下层cache多用写回
- cache-friendly
- cache 对性能的影响
- 怎么写
在系统上运行程序
链接
链接基本上都看过了。简单抽取新点子。不详细记录了
-
静态链接
- 符号解析
- 重定位
-
符号表
- bss 记成better save space
- name mangling,直译确实很糟糕。毁坏。。这个毁坏不是destroy,是把布压碎的那种毁坏。意译好一点或者别翻译了
- 全局符号处理,强弱符号。符号覆盖(hook)
- 符号依赖,注意库在后面。放在前面就被忽略
异常控制流
-
异常处理
-
异常表
类别 原因 异步? 返回行为 中断 IO设备的信号 异步 总是返回到下一条指令 陷阱 syscall 有意的异常 同步 总是返回到下一条指令 故障 缺页错误 潜在可恢复的错误 同步 可能返回到当前指令 终止 硬件错误 不可恢复的错误 同步 不会返回 异常号 描述 异常类型 0 除法错误 故障 13 一般保护故障 故障 14 缺页 故障 18 机器检查 终止 32~127 操作系统定义的异常 中断或陷阱 128 系统调用 陷阱 129~255 操作系统定义的异常 中断或陷阱
-
- 进程,多任务,抢占。时间片
- 用户模式和内核博士
/proc访问内核数据/proc/pid/maps老朋友 了
- 上下文切换
- 中断污染cache
- 用户模式和内核博士
- 系统调用和错误处理,错误会返回-1且标记
errno,记得处理 - 进程控制
- 创建/终止,获取pid等等
- fork细节
- 创建一次返回两次
- 并发执行
- 相同但是独立的地址空间,基于COW
- 文件共享,注意关闭
- fork细节
- 回收子进程
- 加载运行程序
- 创建/终止,获取pid等等
- 信号
- 信号处理问题
- 信号被阻塞,直接返回
- 待处理的信号不会排队等待
- 系统调用可以被中断
- 有的系统被中断不重新运行
- sigaction和setjmp处理信号。
- 信号处理问题
| 号码 | 名字 | 默认行为 | 相应事件 |
|---|---|---|---|
| 1 | SIGHUP | 终止 | 终端挂起 |
| 2 | SIGINT | 终止 | 键盘中断 |
| 3 | SIGQUIT | 终止 | 键盘退出 |
| 4 | SIGILL | 终止 | 非法之灵 |
| 5 | SIGTRAP | 终止并dumping core | 跟踪陷阱 |
| 6 | SIGABRT | 终止并dumping core | abort函数信号 |
| 7 | SIGBUS | 终止 | bus err |
| 8 | SIGPFE | 终止并dumping core | 浮点异常 |
| 9 | SIGKILL | 终止 | 杀死程序 |
| 10 | SIGUSR1 | 终止 | 用户自定义 |
| 11 | SIGSEGV | 终止并dumping core | 段错误 |
| 12 | SIGUSR2 | 终止 | 用户自定义 |
| 13 | SIGPIPE | 终止 | 向一个没有读的pipe里写,broken pipe |
| 14 | SIGALRM | 终止 | alarm函数信号 |
| 15 | SIGTERM | 终止 | 软件中指 |
| 16 | SIGSTKFLT | 终止 | 栈故障 |
| 17 | SIGCHLD | 忽略 | 子进程暂停or终止 |
| 18 | SIGCONT | 忽略 | 继续进程如果被暂停或终止 |
| 19 | SIGSTOP | 停止,直到下一个SIGCONT | 不来自终端的暂停 |
| 20 | SIGTSTP | 停止,直到下一个SIGCONT | 来自终端的暂停 |
| 21 | SIGTTIN | 停止,直到下一个SIGCONT | 后台从终端读 |
| 22 | SIGTTOU | 停止,直到下一个SIGCONT | 后台向终端写 |
| 23 | SIGURG | 忽略 | socket紧急 |
| 24 | SIGXCPU | 终止 | CPU时间限制超出 |
| 25 | SIGXFSZS | 终止 | 文件大小限制超出 |
| 26 | SIGVTALRM | 终止 | 虚拟定时器期满 |
| 27 | SIGPROF | 终止 | 剖析定时器期满 |
| 28 | SIGWINCH | 忽略 | 窗口大小变化 |
| 29 | SIGIO | 终止 | 某个描述符上可执行IO操作 |
| 30 | SIGPWR | 终止 | 电源故障 |
- 操作进程工具
strace分析调用ps看进程top看资源/proc
测量程序执行时间
主要介绍了采集数据的方法 counter,多次测量,基于gettimeofday精确时间等。非常粗略
虚拟内存
-
虚拟寻址 MMU做转换
-
VM 虚拟地址数组 映射VP
- VP三个状态,未分配,缓存,未缓存
-
DRAM比SRAM慢十倍,相比缓存不命中要昂贵很多
- 全相联,任何虚拟页VP可以放在任何物理页PP中
- 替换策略很重要,替换错虚拟页代价(处罚)非常高
- 总是写回
-
页表
-
在上面的场景下,VP都在分配磁盘,可能缓存在内存中,(在内存中也可能有对应的物理页也有可能没有),管理各种VP,需要页表
- 子概念,页表项。注意下图的包含关系
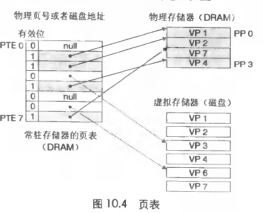
- 子概念,页表项。注意下图的包含关系
-
页命中,上图中击中DRAM页,就会分配物理页,也就是命中
-
不命中,就是缺页,page fault,假如上图中击中vp3,就会牺牲一个vp,上面场景,没被访问的vp4倍淘汰,更新vp3
-
局部性,良好工作机不会产生磁盘流量,以及内存颠簸thrashing,频繁换入换出
-
-
VM 管理功能
- 多进程不同页表,物理页可共享
- 简化链接,简化共享代码段,简化内存分配,简化加载
-
VM作为内存保护工具
- 页表,页表项标志位控制,以及段错误保护
-
地址翻译
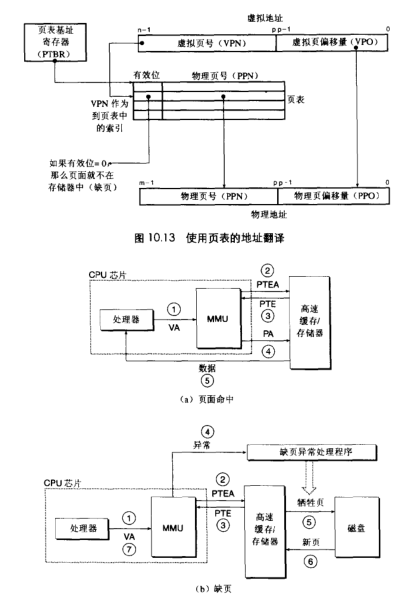
- 结合cache和VM内容较细,不讨论
-
利用TLB(translation lookaside buffer,不是透明大页)加速地址翻译,缓存一波vpe,代替走l1 cache
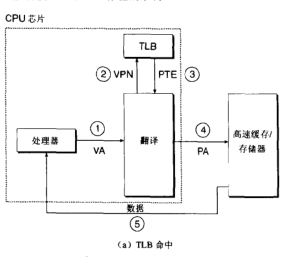
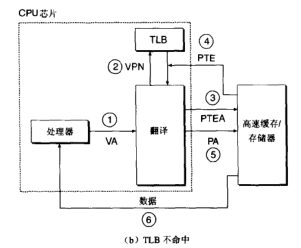
-
多级页表
-
内存映射
-
动态内存分配,以及碎片
- 分配器设计
- 伙伴系统
-
垃圾收集
- 标记清除法
- 有向可达图
- 标记清除法
-
常见内存错误
- 写错误地址,读未初始化内存,栈溢出,指针引用错误,误解指针运算,引用不存在的对象, 内存泄漏等等
程序间的交互与通信
这部分内容和一些书重复。简单列举一些没注意过的/重要的点
系统级IO
- 一切都是文件
size_tssize_t系统函数多用ssize_t, 错误处理返回值是-1- read write的正确用法,这段代码很常见了
ssize_t readn(inf fd, void *usrbuf, size_t n){
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) {
if (errno = EINTR)
nread = 0;
else
return -1;
} else if(nread == 0)
break;
nleft -= nread;
bufp += nread;
}
return (n - nleft);
}
ssize_t writen(inf fd, void *usrbuf, size_t n){
size_t nleft = n;
ssize_t nwritten;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nwritten = write(fd, bufp, nleft)) < 0) {
if (errno = EINTR)
nwritten = 0;
else
return -1;
} else if(nread == 0)
break;
nleft -= nwritten;
bufp += nwritten;
}
return n;
}
- 读取元数据
- 共享文件
- 描述符表 文件表 vnode表
- 子进程集成fd,注意关闭
- IO重定向 dup2
网络编程
- cs模型
- 网络api
- socket api
- socket拿到fd
- connect阻塞 对应tcp哪个阶段?
- bind server端绑定
- listen,server使用,等着
- accept,server端真正的接受了client。accept返回前在tcp哪个阶段?
- web服务器以及http事务
- 状态码
- get post 等api
并发编程
- 基于进程的并发模型
- 进程间IPC
- 慢
- 处理子进程
- 处理SIGCHILD,在handler里waitpid
- fork之前的fd需要关闭两遍
- 进程间IPC
- 基于IO多路复用的并发模型
- select
- while select, 也不高效
- 事件驱动,写好handler,缺点是比较分散比较复杂
- select
- 基于线程的并发模型
- 创建线程,detach干活。浪费
- 共享变量?需要线程之间同步,信号量,锁等等
- 基于线程的IO多路复用
- 并发性问题
- 线程安全
- 共享变量保护
- 不可重入函数
- 静态变量指针?
- 竞争
- 死锁
- 线程安全
