rocksdb-doc-cn
RocksDB迭代器
RocksDB迭代器允许用户以一个排序好的顺序向后或者向前遍历db。它还拥有查找DB中的一个特定key的功能,为此,迭代器需要以一个排序好的流来访问DB。RocksDB迭代器实现类名为DBIter,在这个wiki页,我们会讨论DBIter是如何工作的,以及他的构成。在下面的图片,你可以看到DBIter的设计和构成。
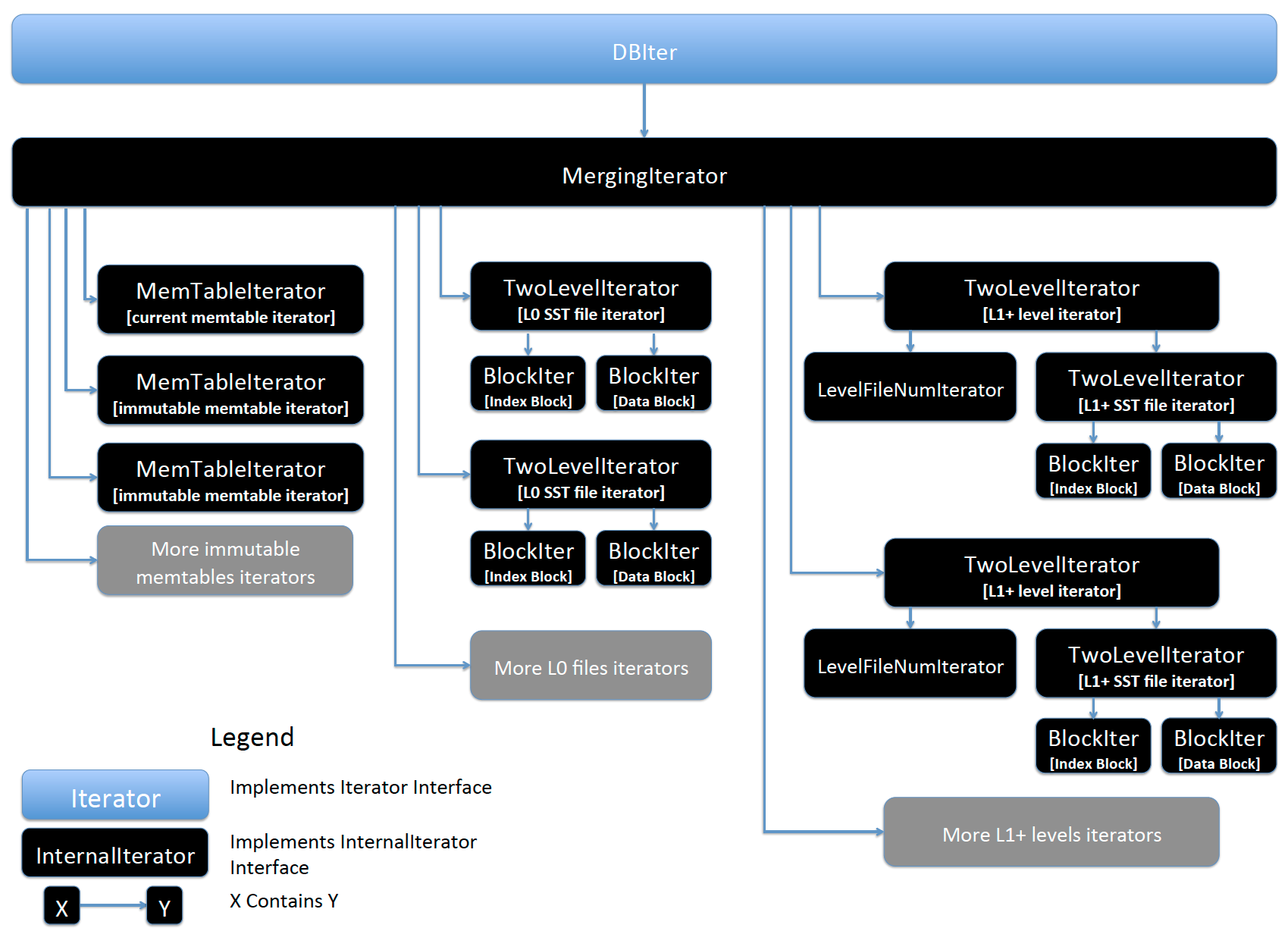
DBIter
实现: db/db_iter.cc 接口: Iterator
DBIter是InternalIterator(在这里是MergingIterator)的一个封装。DBIter的工作是解析InternalIterator返回的InternalKeys,然后把它们解开成用户key。
例子:
底层InternalIterator导出:
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
但是DBIter导出给用户的是
Key="Key1" | Value = "KEY1_VAL2"
Key="Key2" | Value = "KEY2_VAL2"
Key="Key4" | Value = "KEY4_VAL1"
MergingIterator
MergingIterator由非常多的子迭代器组成,MergingIterator基本就是一个迭代器的堆。在MergingIterator,我们把所有子迭代器放在一个堆里,以构成一个排序流。
例子:
底层子迭代器暴露
= Child Iterator 1 =
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
= Child Iterator 2 =
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
= Child Iterator 3 =
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
MergingIterator会把所有子迭代器保存在一个堆里,然后把它们按照一个排序流导出:
InternalKey(user_key="Key1", seqno=10, Type=Put) | Value = "KEY1_VAL2"
InternalKey(user_key="Key1", seqno=9, Type=Put) | Value = "KEY1_VAL1"
InternalKey(user_key="Key2", seqno=16, Type=Put) | Value = "KEY2_VAL2"
InternalKey(user_key="Key2", seqno=15, Type=Delete) | Value = "KEY2_VAL1"
InternalKey(user_key="Key3", seqno=7, Type=Delete) | Value = "KEY3_VAL1"
InternalKey(user_key="Key4", seqno=5, Type=Put) | Value = "KEY4_VAL1"
MemtableIterator
实现: db/memtable.cc
这是一个MemtableRep::Iterator的封装,每一个memtable分别实现自己的迭代器以导出memtable自己的kv排序流数据。
BlockIter
这个迭代器被用于读取SST文件的块,不管这些块是索引块还是数据块。由于SST文件块都是排序好的,并且不可变得,我们把这个块的数据加载到内存然后为排序好的数据创建一个BlockIter
TwoLevelIterator
实现:table/two_level_iterator.cc
一个TwoLevelIterator由两个迭代器构成:
- 第一层迭代器(first_level_iter_)
- 第二层迭代器(second_level_iter_)
first_level_iter_被用于找出需要使用的second_level_iter_,second_level_iter_指向实际读取的数据。
例子:
RocksDB使用TwoLevelIterator来读取SST文件,first_level_iter_指向SST文件的索引块的BlockIter,而second_level_iter_则是一个数据块的BlockIter。
来看一个简单的SST文件例子,我们有4个数据块和一个索引块:
[Data block, offset: 0x0000]
KEY1 | VALUE1
KEY2 | VALUE2
KEY3 | VALUE3
[Data Block, offset: 0x0100]
KEY4 | VALUE4
KEY7 | VALUE7
[Data Block, offset: 0x0250]
KEY8 | VALUE8
KEY9 | VALUE9
[Data Block, offset: 0x0350]
KEY11 | VALUE11
KEY15 | VALUE15
[Index Block, offset: 0x0500]
KEY3 | 0x0000
KEY7 | 0x0100
KEY9 | 0x0250
KEY15 | 0x0500
为了读这个文件,我们创建一个TwoLevelIterator:
- first_level_iter_ => BlockIter指向索引块
- second_level_iter_ => BlockIter指向数据块,会通过first_level_iter_来决定
比如,当我们要求TwoLevelIterator查找KEY8,他会先使用first_level_iter_(索引块的BlockIter)来找出那个块可能会包含这个key。这会找到对应的second_level_iter_(偏移0x0250的数据块的BlockIter)。我们会使用second_level_iter_来找到我们在数据块的key和value。
