## 为什么选择`FasterKV`引擎 - 业务场景 - 同行竞品 - 实践与探索
<!-- .element: style="font-size:75%;" --> ## 业务场景: 特征存储  <!-- .element height="70%" width="70%" --> - 离线导入/周期性增量导入 - 数据量大,内存型无法满足 - value大,可能有带宽问题和放大问题 - 读写性能要求高
<!-- .element: style="font-size:75%;" --> ## 特征存储业界方案 | 选型 | rocksdb | 完美hash|redis| | --- | --- | --- |--- | | 批量导入| 支持在线写/批量导入 | 批量导入,增量导入需要自己实现 |在线/离线| | 数据量大| 分片+SSD | 分片+SSD |分片+内存| | value大| 开启blobdb kv分离策略 +拉链|需要自己实现value分离 /拉链 |拆分大value拉链| | 读写性能高| O(log(N)) | O(1) |O(1)| - 选用rocksdb 国内大厂基本都是这个方案 - 选用redis 有钱的公司需要实时性比较高的场景 - 完美hash 腾讯featurekv facebook f3 能控制数据规模+控制增量逻辑,没有靠谱的开源实现
<!-- .element: style="font-size:70%;" --> ## 那么有没有一款引擎能满足我们的需求呢?  <!-- .element height="10%" width="100%" -->
<!-- .element: style="font-size:80%;" --> ## Faster,一个你来不及自己写可以对付用的支持磁盘存储的hashkv 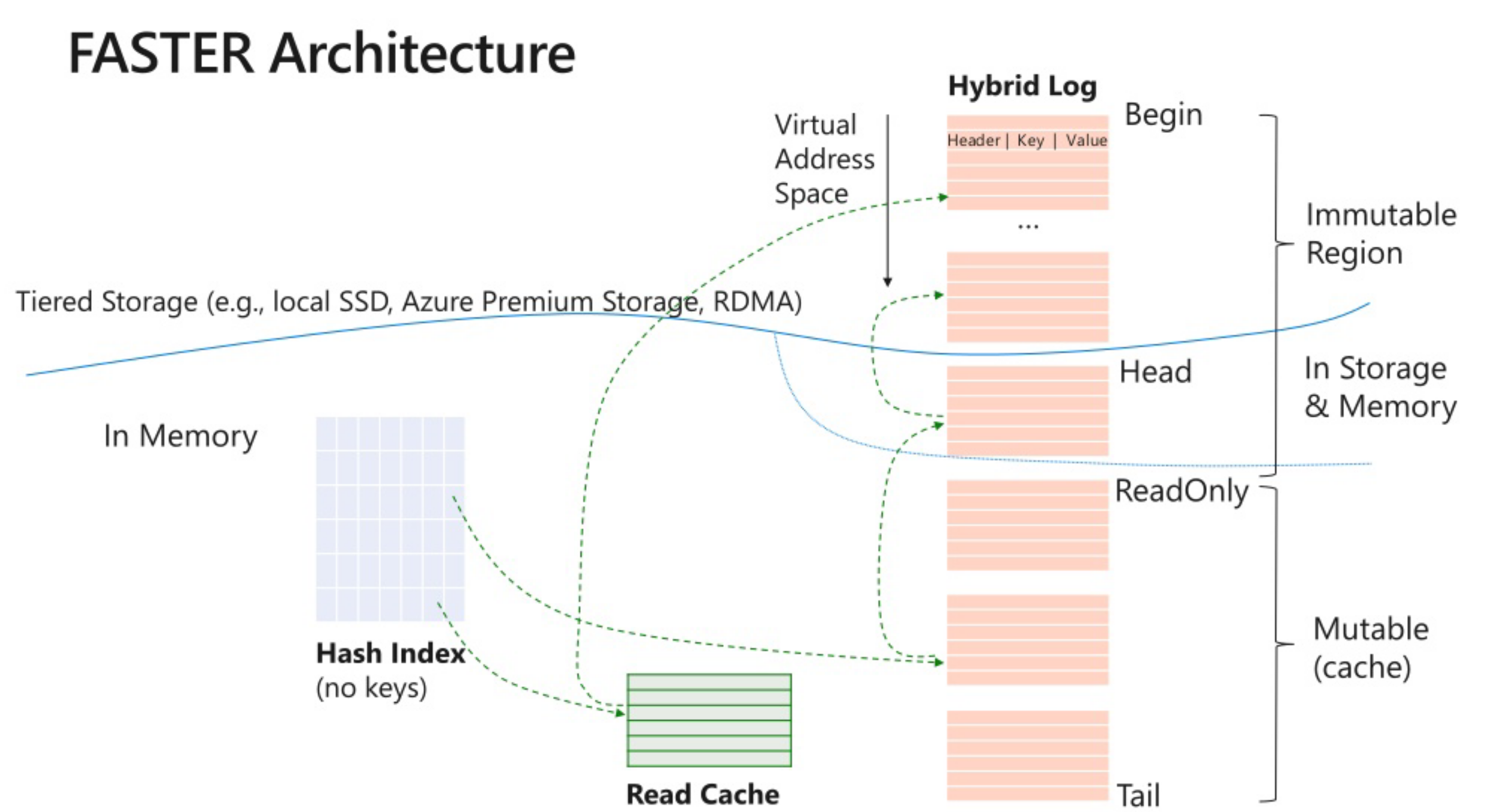 - 使用背景, 点读,in-place更新,热数据在内存,冷数据定期删除/存到azure云
<!-- .element: style="font-size:75%;" --> | 选型 | rocksdb | 完美hash|fasterkv| | --- | --- | --- |--- | | 批量导入| 支持在线写/批量导入 | 批量导入,增量导入需要自己实现 |在线/离线/增量| | 数据量大| 分片+SSD | 分片+SSD |分片+SSD| | value大| 开启blobdb kv分离策略 +拉链|拉链|拉链| | 读写性能高| O(log(N)) | O(1) |O(1)| - 看上去很美好,代价呢?
<!-- .element: style="font-size:75%;" --> ### Faster的缺陷以及需要改进的工作 - 社区开源的代码AIO的使用居然是错误的 - 遍历的代码也是错误的 - compact依赖遍历,所以compact也是错误的 - 分片log递增上线128T,追加写到一定程度就会用光,导致无法写入 - 导入组件来重写,规避 - 改代码 - value上限32M - 随机读问题非常大 - 文件预读 - hashindex内存占用非常大 - 不加载到内存,文件读
<!-- .element: style="font-size:75%;" --> ### 其他探索 - io_uring? - 测试环境linux 5.4 性能没有提升,内核局限 - fasterkv本身就是AIO,主要取决于随机读,随机读问题太严重了 - coroutine? - 10% 降低异步队列的开销 - 如何解决随机读?一次IO,没有冲突?  <!-- .element height="70%" width="70%" -->
<!-- .element: style="font-size:75%;" --> ### 导入相关的工作 - 为什么不选择已有的导入生态? | 选型 | spark| 自建DTS | | --- | --- | --- | | 调度策略|公共调度| 控制子任务粒度,机器资源利用率高 | | 成本 | 两种机型,机械盘便宜但性能不行,固态比自建要贵| 成本低 | | compaction卸载 | 增量任务的compact只能集成到spark jar包中做| 可以在机器空闲的时候单独生成任务 | - 用户可以用自己的spark算力接入,也可以用自建DTS - 算力卸载 - 把DTS的分区能力交给Hive导出阶段 - 把compaction交给空闲时间段来做
# 谢谢大家 ```c++ void conclude(auto greetings) { while(still_time() && have_questions()) { ask(); } greetings(); } conclude([]{ std::cout << "Thank you!"; }); ``` - 美团外卖特征平台的建设与实践 https://tech.meituan.com/2021/03/04/featureplatform-in-mtwaimai.html - vivo 大规模特征存储实践 https://mp.weixin.qq.com/s/u1LrIBtY6wNVE9lzvKXWjA - 列举了一些大厂架构 https://qiankunli.github.io/2022/06/27/feature_platform.html - https://github.com/microsoft/FASTER