## `Microsoft Faster KV`引擎 介绍 - 架构 - 业务逻辑/原理 - 并发冲突处理 - 备份 - 其他
<!-- .element: style="font-size:80%;" --> ### 核心就是无锁`hashtable` + `log`文件 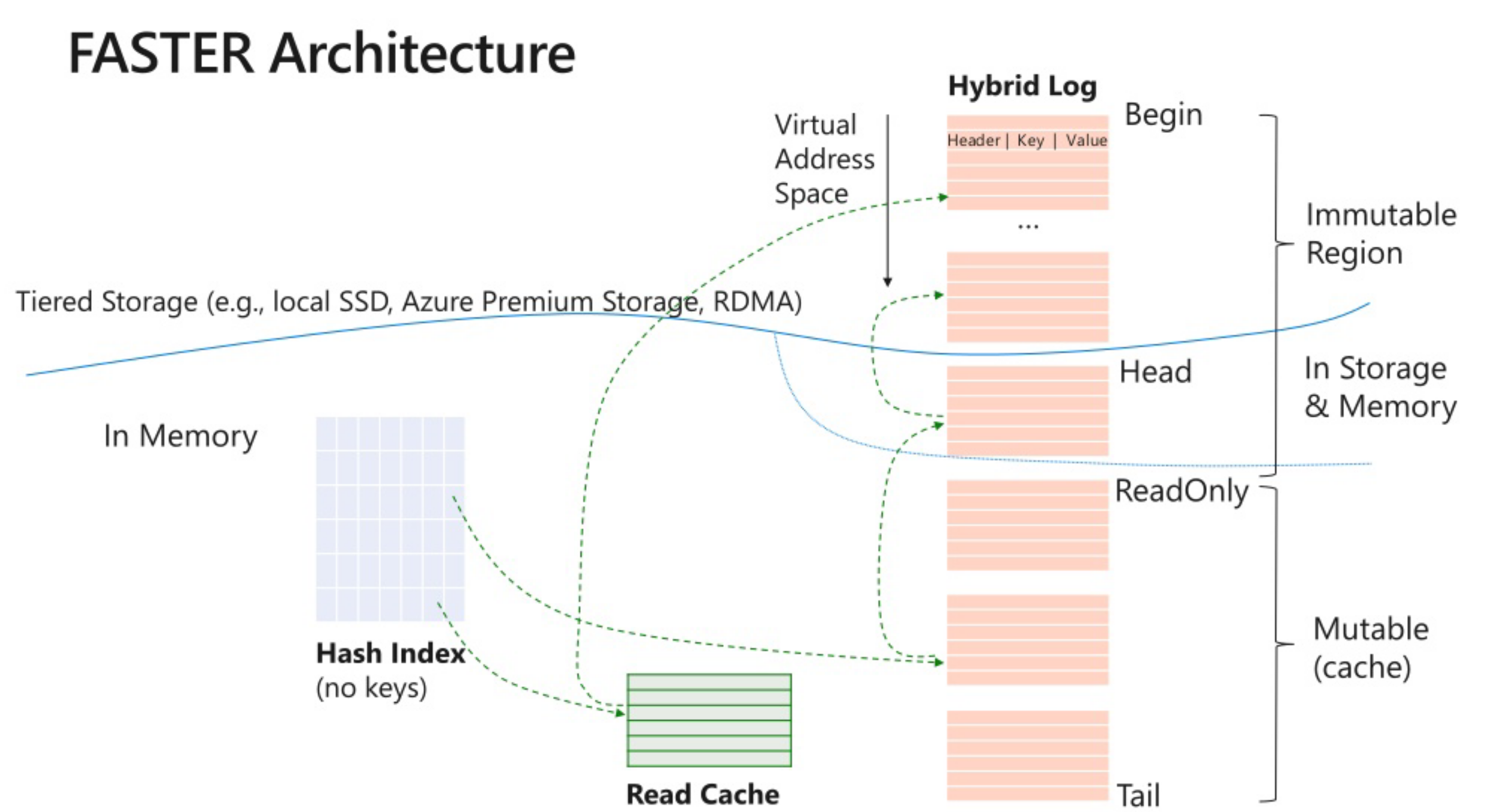 - 使用背景, 点读,in-place更新,热数据在内存,冷数据定期删除/存到azure云
<!-- .element: style="font-size:75%;" --> - hashtable的所有key都是64字节对齐,抵消 false-sharing影响 - hashtable 核心:无锁 原子操作,hashtable 的value是int64,可以CAS - 每个key算出hash定位到具体的位置,并且将一部分hash存在tag中。hashtable是索引,具体的key value打包在一起放到Hybird log中 - 乍一看有点像mmap,不过是无锁 ```c++ union { struct { uint64_t address_ : 48; // corresponds to logical address一般指针只用到48位 uint64_t tag_ : 14; //用来保存一段hash uint64_t reserved_ : 1; uint64_t tentative_ : 1; //如果是1,说明在外面 }; uint64_t control_; }; ```
<!-- .element: style="font-size:75%;" --> - 数据的存储格式 recordinfo + key - value - 所有的record也字节对齐排列到一起 ```c++ union { struct { uint64_t previous_address_ : 48; //冲突的key 链表节点 uint64_t checkpoint_version : 13; uint64_t invalid : 1; uint64_t tombstone : 1; uint64_t final_bit : 1; }; uint64_t control_; }; ``` - 这个recordinfo还是有扩展空间的,毕竟checkpoint_version用不了多少,比如实现ttl
<!-- .element: style="font-size:75%;" --> - Hybird log可以理解成一个追加写的文件  - 之所以叫hybird,本身有内存和文件两部分,内存区域分可变区和只读区,可变区写满就会主动刷到只读区,然后再刷到磁盘 类似 rocksdb 中的 memtable, immutable memtable, sstfile这三者的关系,不过hlog是hash对应文件,没有顺序信息 - 也可以理解成一个ring-buffer - 可读区和可变区的边界点比较重要,不同线程看到的可能不是同一个地址,引入fuzzy region,可以理解成一段边界,后面再决议出来 - 完全插件化设计,可定制hlog落盘的disk,实现WriteAsync/ReadAsync以及文件管理就可以,甚至可以直接写到对象存储,可定制文件读写API(aio/epool/iouring) - 比如[MR](https://github.com/microsoft/FASTER/pull/353) 直接写到azure - 不同disk需要的checkpoint recover能力需要补齐/调整。不同文件读写的能力也需要调整
<!-- .element: style="font-size:75%;" --> ### 存在的问题 - 需要定期checkpoint,不然遇到崩溃,距离上次快照的所有hash index都会丢失
<!-- .element: style="font-size:75%;" --> ### 文件`Device` `disk`设计 `FileSystemDisk`  - WriteAsync和ReadAsync完全能读写到具体的文件,文件handle的获取存在竞争,需要加锁 - 资源释放的动作(OpenSegment/TruncateSegment)挂在epoch上。完美解决更新竞争问题 - 文件也用统一的address来描述 checkpoint和recover没有多余的处理,只要更新好address边界就可以保证正确读取数据 - 如何回收?可以简单的做TTL直接删除,也可以走compact逻辑,扫描删除(社区版本有bug)
<!-- .element: style="font-size:75%;" --> ### `azure`存储作为`device disk`的方案  <!-- .element height="70%" width="70%" --> - WriteAsync和ReadAsync完全能读写到具体的文件,文件周期性淘汰到远端的磁盘上。此时读写远端存储 - 同样,更新的动作也挂在epoch上,推动evict/上传文件 - 文件也用统一的address来描述 没有多余动作 - 没有回收compact。直接指定address来删除
<!-- .element: style="font-size:75%;" --> ### 一个内存池`fake device`的方案 `MemoryPoolDisk` 
<!-- .element: style="font-size:75%;" --> ### 存在的问题 以及 如何解决 - checkpoint的问题同样存在,崩溃必丢数据。不过使用fasterkv主要是为了快以及当成能持久化的cache来用 - 如何保证刷盘与内存池一一对应? WriteAsync保证串行 - 内存池不能基于链表。不然持久化复杂。基于相对地址的page模式简单。碎片回收放在CURD的冲突检查中 - 如何回收?CURD给同hash的链上锁,清理(有延迟但都在内存中,可以接受 - checkpoint recover如何保证 - 提前flush
<!-- .element: style="font-size:75%;" --> ### 被毙掉的方案 - WriteAsync任务队列,队列信息可能会丢导致大量page没落盘。hlog page要落地一个index-mempool page。过于复杂 - Hlog本身hook WriteAsync。过于复杂,也不符合这个分离的设计 - 使用基于链表的内存池 落盘困难
<!-- .element: style="font-size:75%;" --> ### 无需同步的并发设计,`epoch`  <!-- .element height="70%" width="70%" --> - 每个线程绑定一个动作,持有一个epoch,当线程所持有的epoch是安全的,就发起绑定的动作,这个绝对没有冲突 - 所有线程也要决定可读区和可变区的边界  <!-- .element height="70%" width="70%" -->
<!-- .element: style="font-size:75%;" --> ### `epoch`原理文字版 - 系统维护一个原子全局计数器E,以记录当前epoch,它可被任何线程递增。 - 每个线程维护一个`thread-local`版本的E,即Et,它会周期性刷新。而Et保存在一个共享的epoch表中,每个线程使用1个`cache line`大小。 - 当epoch c是安全时,任意线程的`Et>c`。而系统会维护一个最大的安全`epoch Es`。因此有`Es<ET≤ E` - 当epoch变得安全时,框架可以通过触发器执行任意的全局操作。 - 当增加当前epoch时(如从c→c+1),线程可以绑定一个回调,当某个时刻c安全时,可以触发该回调操作。这个绑定维护在drain-list列表中,每一项为(epoch, action)。该表用小数组实现,并用CAS保证线程安全。 - 当前epoch改变时,Es会被重新计算,而该表会被扫描,回调会被触发。 - bw-tree用的也是这个方案
<!-- .element: style="font-size:75%;" --> ### 备份实现:基于`epoch` + 双`buffer`切换 - fasterkv引擎没有write ahead log,WAL本身是多线程写入的瓶颈之一,没有WAL,如何保证数据安全?还是依靠epoch框架 - 作者的测试,引入WAL,写入直接降低十倍 - 牺牲持久化能力。崩溃就全丢 - 根据epoch框架,打checkpoint也可以抽象成一个动作,只要满足做checkpoint的当前线程安全,就可以无阻塞的创建 - c#无阻塞。c++版本代码没合入 - 会主动把可变区的内存刷到磁盘。这个逻辑和rocksdb也是相似的 
<!-- .element: style="font-size:75%;" --> ### 如果用内存池作为`disk`,备份存在的问题 - checkpoint期间需要完全阻塞写入。不然会出现hash index 和内存池不对应 - checkpoint文件分为 hash index和内存池文件,不同于原来hlog address的统一处理,转到内存池,address不满足原有的递增逻辑 - 要绝对的保证hash index 和内存池一致,且在hlog buffer中的内存完全刷到内存池中,flush hlog buffer -> dump hash index -> dump memory pool
<!-- .element: style="font-size:75%;" --> ### 备份流程: 文字版 - **REST** Commit在数据处于rest phase状态的时候被请求。设这个时候数据的版本为v。这个阶段由Commit函数触发。这个函数中更新数据库的状态为prepare,并添加一个PrepareToInProg。这个tigger会在所有的线程进入prepare状态后触发。每个线程也会更新本地的保存的信息。之后进入prepare阶段 - **PREPARE** 准备版本推进 这里如果遇到了大于目前版本V的数据版本,这个事务的执行abort。这个线程会更新线程本地的信息 - **IN-PROGRESS** 执行版本推进 PrepareToInProg函数会在所有的线程进入prepare状态之后被触发。它会更新系统的状态为in-progress,然后添加另外的一个trigger,刷新本地的信息。一个In-Progress状态的线程在数据版本为v+1的状态下面执行事务。这个操作的时候,如果一个线程遇到去读写记录集合内,且版本小于v+1的,它会将这些记录的版本信息修改为v+1。这么处理的原因是为了其它线程防止读取到这些还没有提交的数据。为了相互操作的不Blocking。这里会将记录live的数据拷贝到stable部分中。 - **WAIT-FLUSH** 等待版本下盘 InProgToWaitFlush操作。这个操作会首先设置全局状态信息为wait-flush。如果对于版本信息为v+1的记录,收集起stable版本,否则收集live版本。这个时候进来的事务会按照在in-progress阶段中处理的方式一样处理,所有的记录被收集且持久化之后,更新状态为rest,并更新全局的版本信息为v+1
<!-- .element: style="font-size:75%;" --> ### `compact`涉及到的方案设计 - 社区方案的compact是重新写一个新的,旧的释放,改成多线程任务队列扫描写 - 统计Hlog空洞率,根据空洞率进行compact - compaction filter,自定义过滤策略 - 可以指定compact的策略,全部compact还是从旧到新逐个文件根据空洞率从高到低来compact - 比如整体空洞率50%,那最后一个文件可能空洞率要超过70%,才有compact的价值,compact一半文件,保证能减少整体文件的体积 - 和rocksdb类似,compact就是另一种写,所以要限制compact速度(可动态配置),引入rate limiter - 每个Hlog文件都应该统计一个空洞率信息,可以针对性的删除 - 目前的实现就是扫描log重写 - 针对不同的device要有不同的compact实现,比如memorypool disk,没有hlog文件,无法扫描,就得扫hashindex来做。基本等于重写hash index了,和扩缩容差不多
<!-- .element: style="font-size:75%;" --> ### `compact`存在的问题 - 开销很大,小key大量新数据可能需要很多compact,性价比低 - compact如果崩溃,可能就会有数据不一致的问题,数据删了,却没有落地
<!-- .element: style="font-size:75%;" --> ### 优点以及可以优化的点 - 所有的buffer分配都走内部的内存分配器,尽可能的复用读写buffer,降低内存碎片 - 除了hashtable的64位key对齐, hlog的数据块也是尽可能对齐的,使用libAIO以及iouring,有更好的吞吐 - 内部hash算法替换,冲突率过高 - 尽可能的减少复制 - Compact清理hashtable 延迟过高,代码fix,反馈给社区 - rehash只能扩容,不能缩小
<!-- .element: style="font-size:75%;" --> ### 性能数据 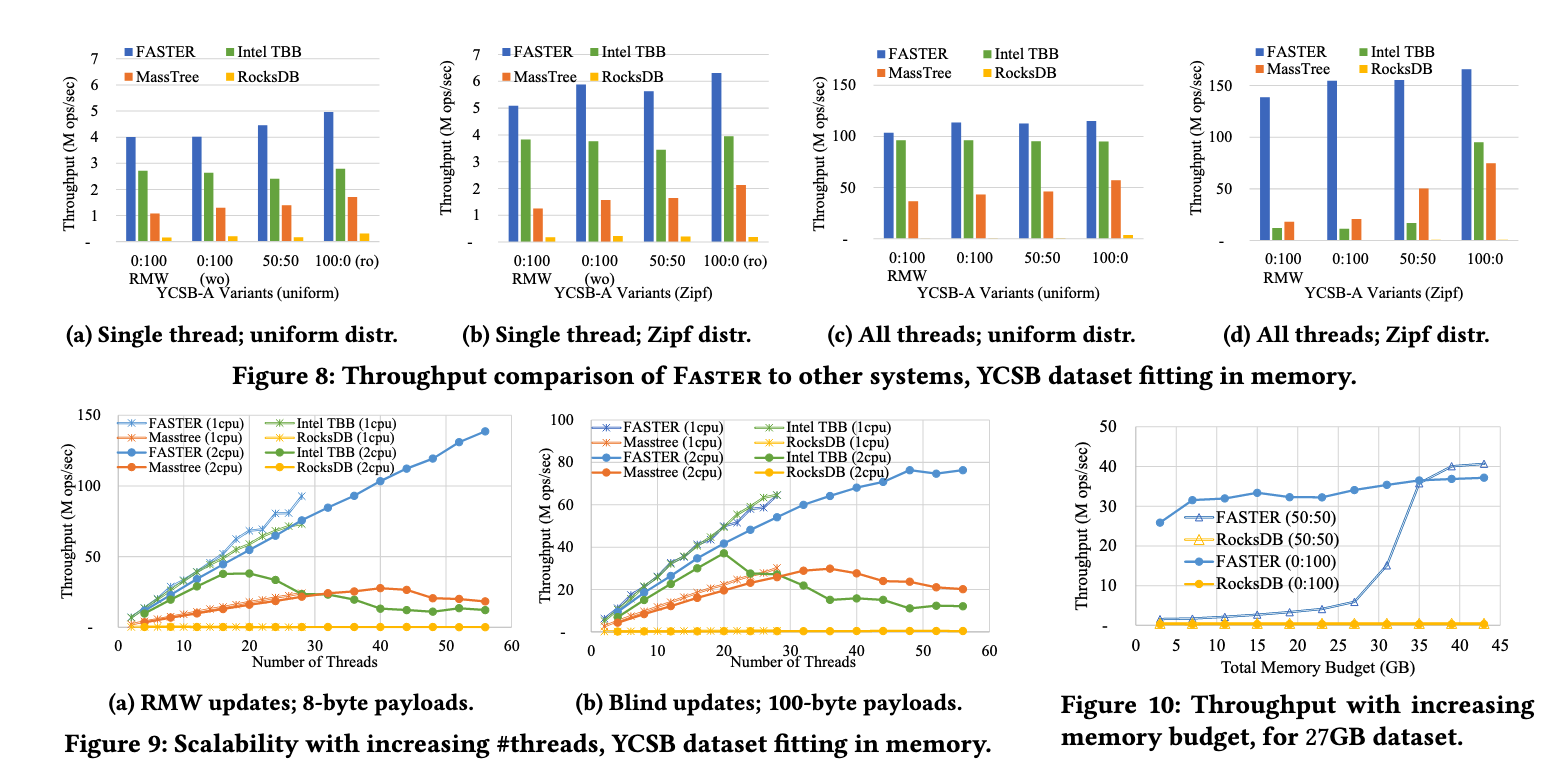
<!-- .element: style="font-size:75%;" --> ### 实际数据??
# Q/A
<!-- .element: style="font-size:75%;" --> - 参考资料 - https://github.com/microsoft/FASTER - https://www.microsoft.com/en-us/research/uploads/prod/2018/03/faster-sigmod18.pdf - https://zhuanlan.zhihu.com/p/111130238 - https://www.zhihu.com/question/291185867 - https://nan01ab.github.io/2019/05/FASTER.html - https://microsoft.github.io/FASTER/docs/td-slides-videos/ - https://www.youtube.com/watch?v=68YBpitMrMI 咖喱味太重了,基本听不明白,不建议看 他还做了个CMU的演讲,讲的比上面这个十分钟的多一些 https://www.youtube.com/watch?v=4Y0oNFud-VA - https://microsoft.github.io/FASTER/docs/td-research-papers/