C++ 中文周刊 2024-06-02 第159期
公众号

点击「查看原文」跳转到 GitHub 上对应文件,链接就可以点击了
qq群 点击进入
RSS https://github.com/wanghenshui/cppweeklynews/releases.atom
欢迎投稿,推荐或自荐文章/软件/资源等,评论区留言
本期文章由 HNY 404 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-05-29 第256期
P3292R0 Provenance and Concurrency
这个论文讲了一种场景,这个场景其实也不算啥问题,然后也没提出啥解决方案,也没有啥好解决的方案,当前场景对服用也不是不行
分享给大家浪费一下大家时间
文章
C++23: chrono related changes
chrono相关改动
- 修复缺陷:自动本地化
-
std::locale::global(std::locale("ru_RU")); using sec = std::chrono::duration<double>; auto s_std = std::format("{:%S}", sec(4.2)); // s == "04.200" (not localized) auto s_std2 = std::format("{:L%S}", sec(4.2)); // s == "04,200" (localized) std::string s_fmt = fmt::format("{:%S}", sec(4.2)); // s == "04.200" (not localized)
第四行c++20会挂,新版本强制自动本地化,如果你不想要这种行为,自己手动format
- 澄清本地化的编码格式兼容问题
- 对于语言,存在本地编码和文字编码不匹配的问题??
std::locale::global(std::locale("Russian.1251"));
auto s = std::format("День недели: {:L}", std::chrono::Monday);
这个就会乱码,因为俄语的星期一有两种符号一个是utf8的一个不是
很抽象
- 放松clock要求
现在只要支持now就行
An Extensive Benchmark of C and C++ Hash Tables
他这个压测场景和数据非常详细。非常不错
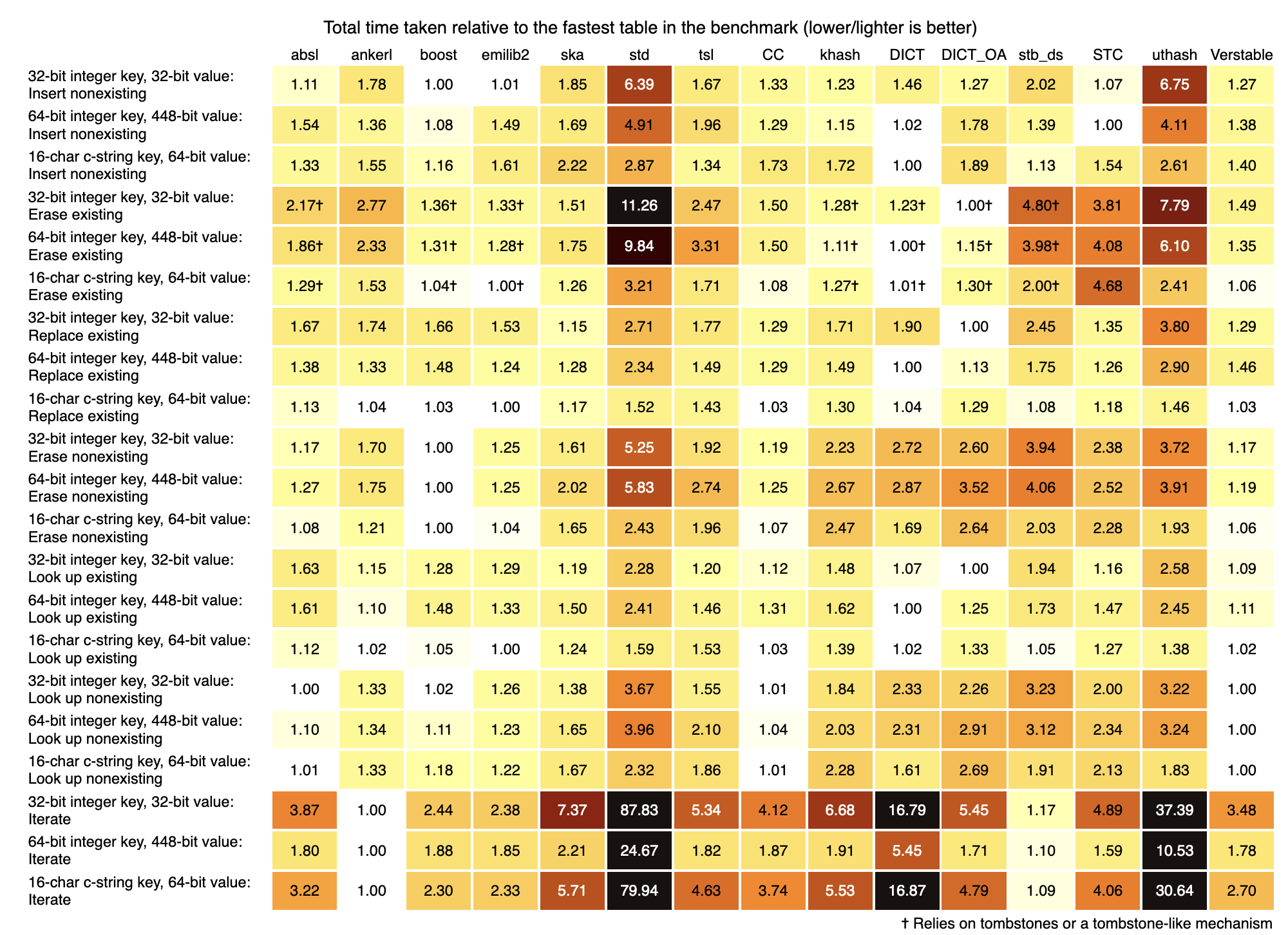
看图来说 boost unordered map性能不错
多线程的hashmap比如tbb boost concurrency unorderedmap folly map之类 的压测,没有
感觉这个还是挺值得测的
另外这里没有folly f14, 感觉可以加一下 (感谢mwish指出)
Quickly checking whether a string needs escaping
简单实现可能是这样
bool simple_needs_escaping(std::string_view v) {
for (char c : v) {
if ((uint8_t(c) < 32) | (c == '"') | (c == '\\')) {
return true;
}
}
return false;
}
优化一下,去掉分枝
bool branchless_needs_escaping(std::string_view v) {
bool b = false;
for (char c : v) {
b |= ((uint8_t(c) < 32) | (c == '"') | (c == '\\'));
}
return b;
}
更自然的,查表
static constexpr std::array<uint8_t, 256> json_quotable_character =
[]() constexpr {
std::array<uint8_t, 256> result{};
for (int i = 0; i < 32; i++) {
result[i] = 1;
}
for (int i : {'"', '\\'}) {
result[i] = 1;
}
return result;
}
();
bool table_needs_escaping(std::string_view view) {
uint8_t needs = 0;
for (uint8_t c : view) {
needs |= json_quotable_character[c];
}
return needs;
}
更更自然的,simd
inline bool simd_needs_escaping(std::string_view view) {
if (view.size() < 16) {
return simple_needs_escaping(view);
}
size_t i = 0;
__m128i running = _mm_setzero_si128();
for (; i + 15 < view.size(); i += 16) {
__m128i word = _mm_loadu_si128((const __m128i *)(view.data() + i));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(34)));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(92)));
running = _mm_or_si128(
running, _mm_cmpeq_epi8(_mm_subs_epu8(word, _mm_set1_epi8(31)),
_mm_setzero_si128()));
}
if (i < view.size()) {
__m128i word =
_mm_loadu_si128((const __m128i *)(view.data() + view.length() - 16));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(34)));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(92)));
running = _mm_or_si128(
running, _mm_cmpeq_epi8(_mm_subs_epu8(word, _mm_set1_epi8(31)),
_mm_setzero_si128()));
}
return _mm_movemask_epi8(running) != 0;
}
性能就不说了。看有没有必要吧,没有必要的话最多无分支版本哈,代码太多了,收益不大。当然性能肯定是simd最快
感兴趣自己玩一下 代码
Function Composition and the Pipe Operator in C++23 – With std::expected
实现shell管道用法
#include <iostream>
#include <functional>
#include <string>
#include <concepts>
#include <random>
#include <expected>
template < typename T >
concept is_expected = requires( T t ) {
typename T::value_type; // type requirement – nested member name exists
typename T::error_type; // type requirement – nested member name exists
requires std::is_constructible_v< bool, T >;
requires std::same_as< std::remove_cvref_t< decltype(*t) >, typename T::value_type >;
requires std::constructible_from< T, std::unexpected< typename T::error_type > >;
};
template < typename T, typename E, typename Function >
requires std::invocable< Function, T > &&
is_expected< typename std::invoke_result_t< Function, T > >
constexpr auto operator | ( std::expected< T, E > && ex, Function && f )
-> typename std::invoke_result_t< Function, T > {
return ex ? std::invoke( std::forward< Function >( f ),
* std::forward< std::expected< T, E > >( ex ) ) : ex;
}
// We have a data structure to process
struct Payload {
std::string fStr{};
int fVal{};
};
// Some error types just for the example
enum class OpErrorType : unsigned char { kInvalidInput, kOverflow, kUnderflow };
// For the pipe-line operation - the expected type is Payload,
// while the 'unexpected' is OpErrorType
using PayloadOrError = std::expected< Payload, OpErrorType >;
PayloadOrError Payload_Proc_1( PayloadOrError && s ) {
if( ! s )
return s;
++ s->fVal;
s->fStr += " proc by 1,";
std::cout << "I'm in Payload_Proc_1, s = " << s->fStr << "\n";
return s;
}
PayloadOrError Payload_Proc_2( PayloadOrError && s ) {
if( ! s )
return s;
++ s->fVal;
s->fStr += " proc by 2,";
std::cout << "I'm in Payload_Proc_2, s = " << s->fStr << "\n";
// Emulate the error, at least once in a while ...
std::mt19937 rand_gen( std::random_device {} () );
return ( rand_gen() % 2 ) ? s :
std::unexpected { rand_gen() % 2 ?
OpErrorType::kOverflow : OpErrorType::kUnderflow };
}
PayloadOrError Payload_Proc_3( PayloadOrError && s ) {
if( ! s )
return s;
s->fVal += 3;
s->fStr += " proc by 3,";
std::cout << "I'm in Payload_Proc_3, s = " << s->fStr << "\n";
return s;
}
void Payload_PipeTest() {
static_assert( is_expected< PayloadOrError > ); // a short-cut to verify the concept
auto res = PayloadOrError { Payload { "Start string ", 42 } } |
Payload_Proc_1 | Payload_Proc_2 | Payload_Proc_3 ;
// Do NOT forget to check if there is a value before accessing that value (otherwise UB)
if( res )
std::cout << "Success! Result of the pipe: fStr == " << res->fStr << " fVal == " << res->fVal;
else
switch( res.error() ) {
case OpErrorType::kInvalidInput: std::cout << "Error: OpErrorType::kInvalidInput\n"; break;
case OpErrorType::kOverflow: std::cout << "Error: OpErrorType::kOverflow\n"; break;
case OpErrorType::kUnderflow: std::cout << "Error: OpErrorType::kUnderflow\n"; break;
default: std::cout << "That's really an unexpected error ...\n"; break;
}
}
int main() { Payload_PipeTest(); }
揭秘C++:虚假的零成本抽象
标题党
Hydra: 窥孔优化泛化
看不懂
开源项目介绍
互动环节
