ArchSummit上海2023 PPT速览
19 Jul 2024
|
|
ppt在这里 https://www.modb.pro/topic/640976
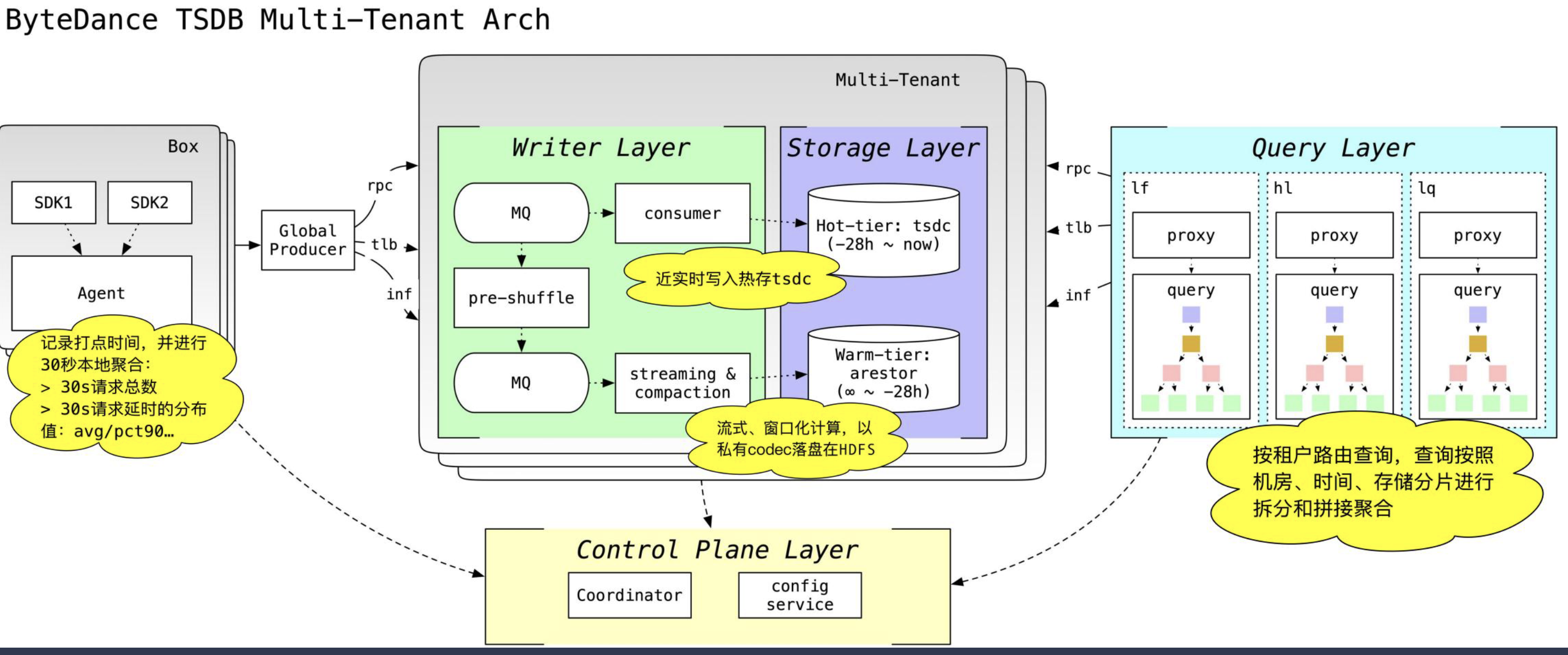
云原生存储CubeFS在大数据和机器学习的探索和实践
主要是提了个缓存加速
- 元数据缓存:缓存inode和dentry信息,可以大量减少fuse客户端的lookup和open读文件的开销。
- 数据缓存:数据缓存可以利用GPU本地云盘,无需申请额外存储资源,在保证数据安全同时提升效率。
其他的就是常规的东西,raft和分布式文件系统相关优化(raft,存储纠删码,NWR,攒批写(小文件聚集写)等等)
字节跳动时序存储引擎的探索和实践
Workload分析和对应的挑战
- 写远大于读,写入量非常大
- 线性扩展
- 查询以分析为主,点查为辅
- 面向分析查询优化的同时兼顾点查性能
- 超高维度
- 在单机亿级活跃维度情况下依然保证写入和查询性能
- Noisy Neighbours
- 租户间的隔离
- 防止个别超大metric影响整体可用性
如何线性扩展
- 二级一致性Hash分区
- 先按照Metric做一次Hash分区
- 再按照序列做第二次Hash分区
- Metrics级别的动态分区
- 不同维度的Metric可以拥有不同的二级Hash分片数
编码优化
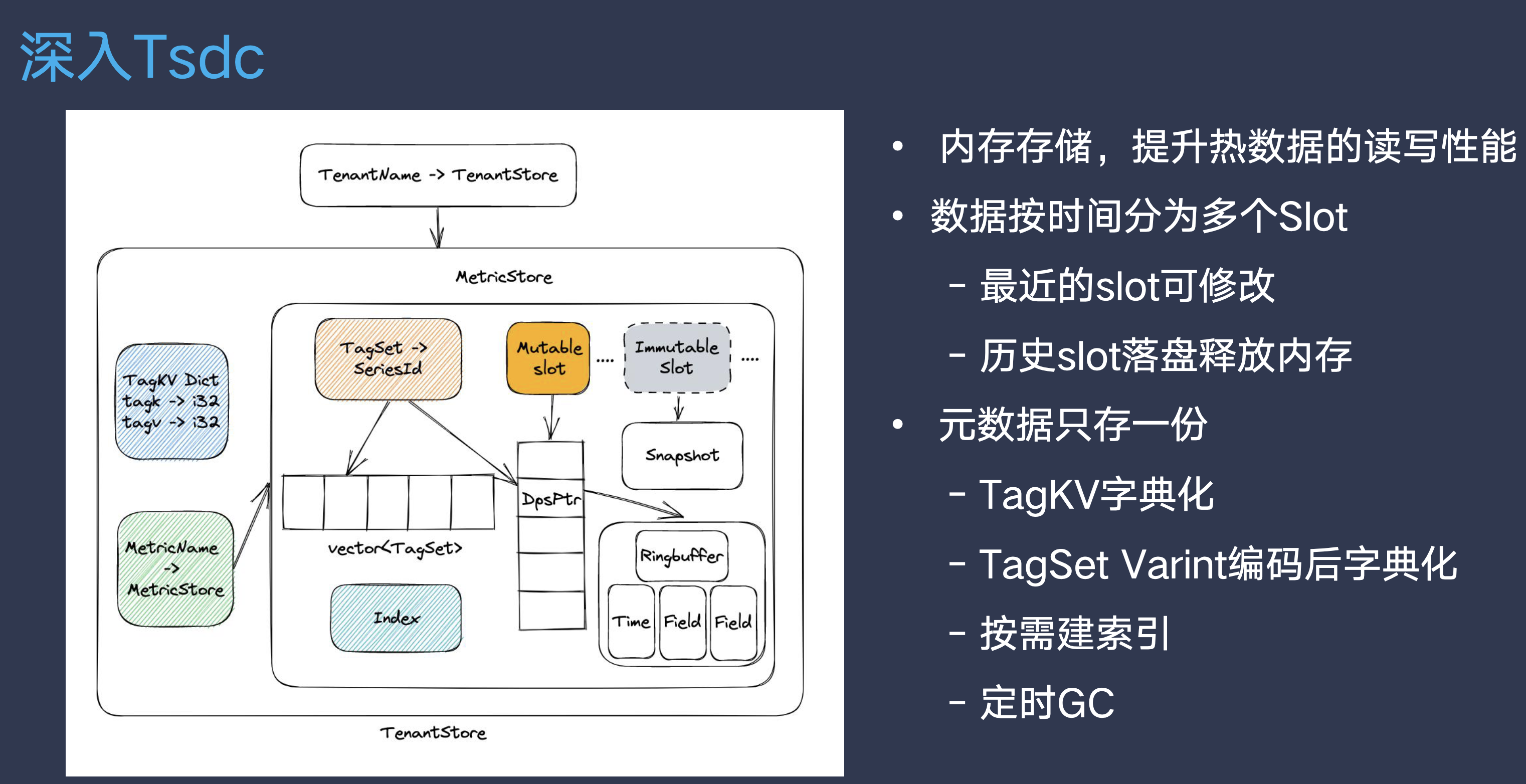
观察数据特征
- 大部分序列拥有相同的TagKeys 每个序列的所有TagKeys称为TagKeySet
- 直接编码整个TagKeySet
- TagSet中只存储一个id
- Encode时只做一次Hash
- 直接编码整个TagKeySet
Datapoint Set
- RingBuffer用于处理乱序写入,存储原始数据点
- 数据点划出RingBuffer后,写入TimeBuffer和ValueBuffer
- TimeBuffer使用delta of delta压缩
- ValueBuffer使用Gorilla压缩
- 乱序写入优化
- Question:
- RingBuffer容量有限
- Gorilla压缩算法只能append
- Answer:
- 反向Gorilla压缩,能够Popback
- 乱序很久的点不写入ValueBuffer,查询时合并
- Question:
查询优化
- 支持所有Filter下推,减少数据传输量
- 包括wildcard和regex,利用索引加速
- 自适应执行
- 根据结果集大小动态选择查询索引或者Scan
- 并行Scan
- 轻重查询隔离
- 轻重查询使用不同的线程池
- 根据维度和查询时长预估查询代价
Khronos存储引擎
- 降低内存使用,更低成本地支持单实例高维度数据
- 数据全部持久化,提升数据可靠性
- 保持高写入吞吐、低查询时延,提供高效的扫描,同时支持较好的点查性能
- 能够以较低的成本支持较长时间的存储,提供较高的压缩率以及对机械盘友好的存储格式
- 兼容Tsdc,最低成本接入现有集群
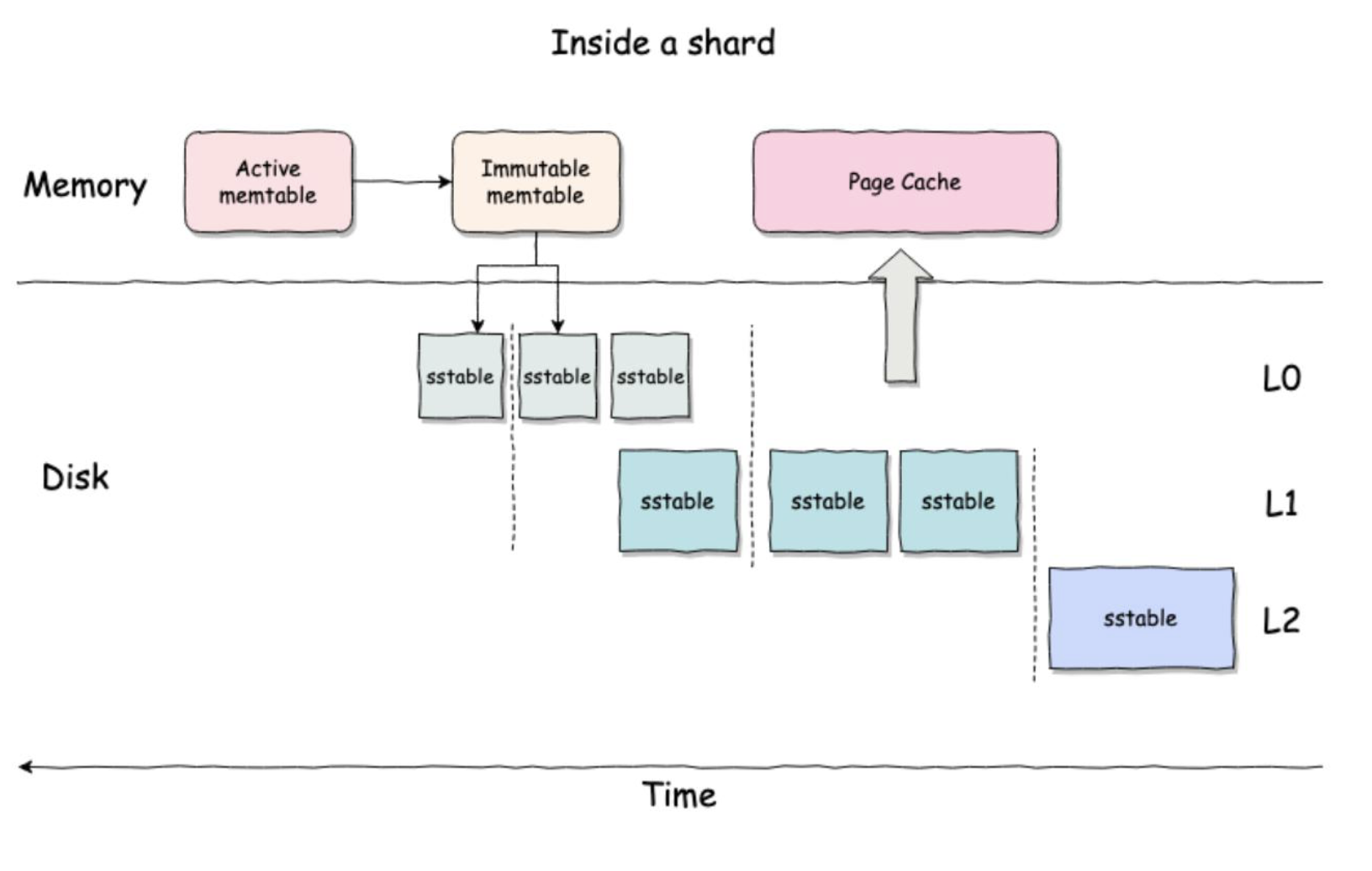
- 每个Shard内部都是一棵独立的LSMT
- 一共分为三层
- 每一层都有一个虚拟的时间分区
- sstable文件不会跨时间分区
- Compaction在分区内调度
- 乱序写入的场景减少写放大
Memtable
- 基本延用了Tsdc的内存结构
- SeriesMap采用有序结构,Compaction依赖Series有序
- SeriesKey = SeriesHashCode + TagSet
- 节省比较开销
- 快速拆分range,方便做分区内并行查询
SST
- 由于Metric数量非常多,所以将多个Metric数据混合存储在一个文件中
- 文件尾部有Metric Index指向Metric的位置
- MetricIndex是一个Btree
- Page内部使用前缀压缩
Metric格式
- 类Parquet格式,行列混存
- 每行一个序列
- 大Metric会划分为多个SeriesGroup,减少内存占用
- 字典/Raw/Bitshuffle encoding
- Page索引加速查询
Flush优化
- 大量小Metric
- 存储格式Overhead大
- write次数太多,性能差
- BufferWrite
- 预先Fallocate一段空间然后mmap
- 数据通过mmap写入,减少syscall
- PaxLayout
- 所有Column写在一个Page
- 减少IO次数,减少元数据开销
SSTable查询优化
- 延迟投影
- 先读取带过滤条件的列
- 每过滤一个列都缩小下一个列的读取范围
- 最后投影非过滤列
- 数量级性能提升
- PageCache
- Cache中缓存解压后的Page,避免重复的解压和CRC校验
- 更进一步,直接Cache PageReader对象,节省构造开销
他们的工作做的确实挺多
云原生数据库的架构演进
就是回顾架构设计
主从
- 架构痛点
- 弹性升降配困难 确实。规格钉死
- 只读扩展效率低延迟高 -> 这个可能就要根据一致性放松一点了
- 存储瓶颈 -> 路由分裂啊
- 业务痛点
- 提前评估规格资源浪费 -> 那就从最小集群慢慢扩容呗?
- 临时峰值稳定性问题 -> 确实,只好限流熔断/backup request
- 读扩展提前拆库 路由分裂确实存在运营压力
- 容量拆库 这个也是要结合路由分裂,存在运营压力/资源浪费
存算分离一写多读
- 架构痛点
- 弹性升降配 要断链
- 无法无感知跨机弹性?
- 只读节点延迟问题
- 业务痛点
- 业务不接受闪断
- 容量规划/突发流量处理?和主从一样没有解决
- 电商/微服务不接受读延迟
- 预留水位 资源浪费
阿里第二代serverless设计
- 无感弹性变更规格/跨机迁移
- 高性能全局一致性
- 跨机serverless
- 动态扩缩RO
- 存储资源降低80%,计算资源降低45%,TCO降低 40%
- 共享存储,RO无延迟
- 秒级扩缩容RW/RO,异常恢复速度快
- 运维工作量低
- 实现了一站式聚合查询和分析,提升数据向下游传送效率
- 秒级增删节点
- 透明智能代理实现智能读写分流
- 全局binlog向下游提供增量数据的抽取
- 全局RO支持汇聚业务,ePQ有效提高业务查询性能
- 用户通过多节点进行有效的资源隔离
其实阿里这么玩的前提是有一个资源池管理
