neon专题
最近看了很多文章,列出来并且介绍一下设计思路技术选取
整体设计与其说aurora,更像 论文Socrates: The New SQL Server in the Cloud (Sigmod 2019)
Architecture decisions in Neon
可以沉到对象存储
Neon - Serverless PostgreSQL - ASDS Chapter 3
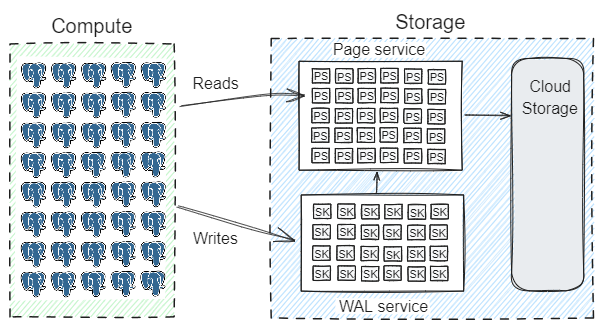
所谓的aurora架构都是这个德性,读 page server,要牛逼点查,还要牛逼scan,写wal 服务,wal服务自动刷page
本身pg架构也是类似的多进程架构,这样改自然,也更容易堆到创业目标索要的性能指标
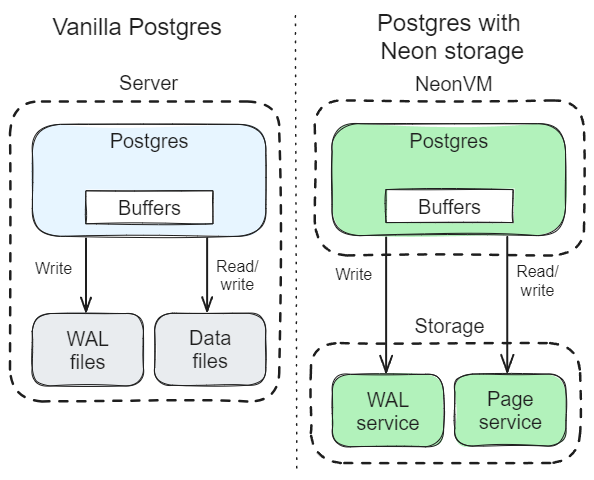
根本没啥区别
其他卖点
时空漫游 Point in time read point in time restore。这种场景还是非常需要的,多版本。
以前在华为某个mongo用户也要这种能力,给rocksdb加时间戳来达到类似的目的
怎么做到?LSN时间戳在LOG中
Why does Neon use Paxos instead of Raft, and what’s the difference?
这篇文章提到,用paxos不用raft,因为架构设计,要求wal服务能帮助复制,但raft没有这种东西
简单说就是raft的witness设计。这种witness其实就是抄的paxos的角色设计,只能说他们没有raft实践团队,选择搞paxos这种强度大的
Deep dive into Neon storage engine
主要设计
存储为了保持PITR,文件要存多版本,而不是快照级别的备份,文件版本是image+delta模式
pageserver只持有一部分,没有就从cloud拉,定期merge写回新的
存储还是LSM,只不过需要为了多版本,做LSN设计,特化一下,不合并版本
快照需求是短的周/月级别
- 存储不可变
两种数据 image和delta
- image : key-range - LSN - kvkvkvkvkvkvkv...
- delta : key - LSN-range - v1v2v3v4...
kudu也是这样的
- 写流程
safekeeper 的内存大部分都是日志,buffer长一些,异步刷数据给pageserver
是不是感觉有点眼熟,没错,当mq用,safekeeper拆出来就是利用paxos多写特性,不局限于pageserver个数。一般pageserver都是key-range模式
wal流刷到pageserver转成成delta文件,然后定期compact成image
- 读,直接走pageserver 指定LSN GetPage@LSN
如果page找不到从云上拉,然后image delta读一波
有点clickhouse read on merge那种感觉。读放大严重
但关系型基本上使用都是range,所以还好
我没有看代码,所以有点疑问:
- 怎么快速的定位image文件?内存中要维护所有key-range信息,然后二分/hash?
- hash slot可能快,但hash scan不友好吧
- 字典序的话,维护一个前缀bloom-filter?
- 二分?让我猜到了,还真是 BST
- 怎么维护delta文件?compact策略是什么?
- 如何快速定位到delta文件?感觉读性能很差啊
- 感觉要有单独的meta信息来维护delta 且能持久化,大概是hash(key) key-lsn-lsn-lsn-lsn这样,不然怎么快速定位到delta,挺好奇neon的解法。
- 一致性级别? 只读pageserver 不读wal 的话,肯定是stale读的,这种能接受吗?
- 还是说客户端指定bound read给一个LSN,读不到失败/等待
感觉有很多地方值得看看代码
Persistent Structures: Key to 2000x Speedup in Neon’s WAL Indexing
看起来有点抽象
黑条image 灰色长方形delta 红线表示读路径
读到黑条image算是快的,返回,读到delta比较复杂,要一直往下找,直到找到image为止,才能定位到具体的LSN,然后这个读,重建image
这显然涉及到一个delta叶子和image根的一个遍历问题
delta叶子是连续的,整个树是不可变只追加的,有点imm-hash-trie的感觉了
那就可以构造二叉搜索树,然后每次新文件都追加写一下二叉搜索树,这样每个版本都有一层bst
没错https://github.com/orium/rpds 他们用的就是这玩意
比如最上层可能是这样的
怎么构造的?
大概下面三个图的流程
这样做到针对LSN的漫游
我之前看到arangodb在raft上也使用immer flex-vector来做,应对log这种追加 寻根比对,确实是一个可以实践的方向
他们的探索
R-tree
最差ON 不可接受,这是内存计算啊
线段树
可能大家都不太懂线段树,能用,就是太复杂,
最终采用二叉搜索树了
https://github.com/neondatabase/neon/pull/2998
https://github.com/neondatabase/neon/blob/main/pageserver/src/tenant/layer_map.rs
感觉还可以仔细研究一下
