blog review 第二十期
寒冬,阳了。
SQL + M4 = Composable SQL
他这个数据schema是星型结构的,然后这些sql很多聚合查找,很乱
举个例子
with
tender as (
select day, store, till, transaction, tender_type, amount
from tender_table),
item_desc as (
select item_id, item_category
from item_desc_table),
sales as (
select day, store, till, transaction, cashier, total,
from sales_table),
sales_items as (
select day, store, till, transaction, line_number,
s.item_id, price, discount, is_return
from sales_items_table s)
select
s.day,
d.item_category,
count(distinct
s.store,
s.till,
s.transaction) as transactions,
sum(case when t.tender_type = 'CARD'
then s.total
else 0 end) as card_total,
sum (s.total) as total
from sales s
join sales_items i on (
s.day = i.day AND
s.store = i.store AND
s.till = i.till AND
s.transaction = i.transaction)
join tender t on (
s.day = t.day AND
s.store = t.store AND
s.till = t.till AND
s.transaction = t.transaction)
join item_desc d on (d.item_id = i.item_id))
group by 1,2
怎么抽象成一个框架来维护呢?考虑宏替换。这里用了m4
最终代码是这个样子
common.m4
divert(-1)
changequote("|,|")
define(
"|M_tender_query|",
"|select day, store, till, transaction, tender_type, amount
from tender_table|")
define(
"|M_item_desc_query|",
"|select item_id, item_category from item_desc_table|")
define(
"|M_sales_query|",
"|select day, store, till, transaction, cashier, total,
from sales_table|")
define("|M_sales_item_query|",
"|select day, store, till, transaction, line_number,
s.item_id, price, discount, is_return
from sales_items_table s|")
define(
"|M_trans_fields|",
"|$1.day,$1.store,$1.till,$1.transaction|")
define(
"|M_sum_if|",
"|case when $1 then $2 else 0 end|")
define(
"|M_join_on_trans|",
"|$1 join on ($2.day = $3.day and
$2.store = $3.store and
$2.till = $3.till and
$2.transaction = $3.transaction)|")
divert(0)dnl
生成的模版
include(common.m4)
with
T as (M_tender_query),
I as (M_item_desc_query),
S as (M_sales_query),
L as (M_sales_item_query)
select
S.day,
I.item_category,
count(distinct M_trans_fields(S)) as transactions,
M_sum_if(T.tender_type='CARD', S.amount) as card_total,
sum(s.total) as total
from S
M_join_on_trans(inner, S, L)
M_join_on_trans(inner, S, T)
join I on (L.item_id = I.item_id))
group by 1,2
看上去简单了点,但是怎么说呢,除非这种sql特别特别特别多,否则引入m4增加难度了,尤其是懂的人屈指可数还得现学(虽然不难)
这里有个m4简明教程 https://mbreen.com/m4.html
Soft Deletion Probably Isn’t Worth It
标记删除,给数据库加一个删除字段 delete_at 如果不是NULL就没删
UPDATE foo SET deleted_at = now() WHERE id = $1;
SELECT *
FROM customer
WHERE id = @id
AND deleted_at IS NULL
这个字段引入其他问题:
- 外键关联问题,你这里标记删除,外键怎么搞?
- 如何彻底删除数据?
作者给的方案就是建立一个删除表
CREATE TABLE deleted_record (
id uuid PRIMARY KEY DEFAULT gen_ulid(),
deleted_at timestamptz NOT NULL default now(),
original_table varchar(200) NOT NULL,
original_id uuid NOT NULL,
data jsonb NOT NULL
);
删除就变成写入
WITH deleted AS (
DELETE FROM customer
WHERE id = @id
RETURNING *
)
INSERT INTO deleted_record
(original_table, original_id, data)
SELECT 'foo', id, to_jsonb(deleted.*)
FROM deleted
RETURNING *;
建立trigger自动化
CREATE FUNCTION deleted_record_insert() RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
EXECUTE 'INSERT INTO deleted_record (data, object_id, table_name) VALUES ($1, $2, $3)'
USING to_jsonb(OLD.*), OLD.id, TG_TABLE_NAME;
RETURN OLD;
END;
$$;
CREATE TRIGGER deleted_record_insert AFTER DELETE ON credit
FOR EACH ROW EXECUTE FUNCTION deleted_record_insert();
CREATE TRIGGER deleted_record_insert AFTER DELETE ON discount
FOR EACH ROW EXECUTE FUNCTION deleted_record_insert();
CREATE TRIGGER deleted_record_insert AFTER DELETE ON invoice
FOR EACH ROW EXECUTE FUNCTION deleted_record_insert();
如何真正删除数据也不用比较字段
DELETE FROM deleted_record WHERE deleted_at < now() - '1 year'::interval
没有维护字段的开销
遇事不决加一张表
Benchmark(et)ing RocksDB vs SplinterDB
点击查看
Results for cached Legend: * insert - inserts/second * point - point queries/second * range - range queries/second * wamp - write-amplification during the inserts 50M rows, 100-byte values ---- ops/second ---- insert point range wamp dbms 533584 246964 31236 1.3 splinterdb 483519 191592 76600 4.5 rocksdb, leveled 488971 180769 57394 2.9 rocksdb, universal 25M rows, 200-byte values ---- ops/second ---- insert point range wamp dbms 474446 261444 33538 1.1 splinterdb 495325 188851 75122 3.7 rocksdb, leveled 500862 201667 83686 2.8 rocksdb, universal Results for IO-bound The performance can be explained by the amount of read IO per query. IO reads per point query for 2B rows, 100-byte values: 1.29 - SplinterDB 0.98 - RocksDB, leveled 1.00 - RocksDB, universal, 1.5B rows IO reads per range query for 2B rows, 100-byte values: 7.42 - SplinterDB 2.34 - RocksDB, leveled 3.24 - RocksDB, universal, 1.5B rows 2B rows, 100-byte values ---- ops/second ---- insert point range wamp dbms 308740 6110 1060 3.7 2B rows, splinterdb 181556 8428 3056 14.1 2B rows, rocksdb, leveled 205736 8404 3029 12.7 1.5B rows, rocksdb, leveled 393873 8144 1889 6.0 1.5B rows, rocksdb, universal 1B rows, 200-byte values ---- ops/second ---- insert point range wamp dbms 221007 7175 908 3.7 1B rows, splinterdb 107692 8393 2436 13.0 1B rows, rocksdb, leveled 121519 8159 2519 11.7 750M rows, rocksdb, leveled 324555 8621 2763 5.3 750M rows, rocksdb universal
https://github.com/mdcallag/mytools/tree/master/bench/splinterdb.vs.rocksdb
Lucene核心技术
这个整理挺详细
凝望深渊,并发控制的尽头
2PL with Deadlock Detection (DL_DETE) 2PL with Non-waiting Deadlock Prevention (NO_WAIT) 2PL with Waiting Deadlock Prevention (WAIT_DIE): Basic T/O (TIMESTAMP)
Multi-version Concurrency Control (MVCC) Optimistic Concurrency Control (OCC): T/O with Partition-level Locking (H-STORE)
并发控制算法和 隔离级别是依赖关系,总是被误导
AC-Key: Adaptive Caching for LSM-based Key-Value Stores
现有系统的问题 一个系统只有KV Cache, KP Cache, Block Cache三种cache的一到两个cache规则无法适应所有的负载cache不能随着负载的变化而调整 作者的贡献 AC-Key将三种cache:KV Cache, KP Cache, Block Cache全部利用了起来,以应对不同的负载三种cache的大小可以动态调整设计了一种评价cache所带来的收益和开销的方法
KP key-pointer 感觉这种cache设计更适合fasterkv这种hashtable模式的。rocksdb没有暴露pointer/层级,怎么才能支持?
ARC强化版吧,2LRU + 2LFU
使用场景,点查
Greenplum:A Hybrid Database for Transactional and Analytical Workloads

基本概念
QD(Query Dispatcher、查询调度器):Master 节点上负责处理用户查询请求的进程称为 QD(PostgreSQL 中称之为 Backend 进程)。 QD 收到用户发来的 SQL 请求后,进行解析、重写和优化,将优化后的并行计划分发给每个 segment 上执行,并将最终结果返回给用户。此外还负责整个 SQL 语句涉及到的所有的 QE 进程间的通讯控制和协调,譬如某个 QE 执行时出现错误时,QD 负责收集错误详细信息,并取消所有其他 QEs;如果 LIMIT n 语句已经满足,则中止所有 QE 的执行等。QD 的入口是 exec_simple_query()。
QE(Query Executor、查询执行器):Segment 上负责执行 QD 分发来的查询任务的进程称为 QE。Segment 实例运行的也是一个 PostgreSQL,所以对于 QE 而言,QD 是一个 PostgreSQL 的客户端,它们之间通过 PostgreSQL 标准的 libpq 协议进行通讯。对于 QD 而言,QE 是负责执行其查询请求的 PostgreSQL Backend 进程。通常 QE 执行整个查询的一部分(称为 Slice)。QE 的入口是 exec_mpp_query()。
Slice:为了提高查询执行并行度和效率,Greenplum 把一个完整的分布式查询计划从下到上分成多个 Slice,每个 Slice 负责计划的一部分。划分 slice 的边界为 Motion,每遇到 Motion 则一刀将 Motion 切成发送方和接收方,得到两颗子树。每个 slice 由一个 QE 进程处理。上面例子中一共有三个 slice。
Gang:在不同 segments 上执行同一个 slice 的所有 QEs 进程称为 Gang。上例中有两组 Gang,第一组 Gang 负责在 2 个 segments 上分别对表 classes 顺序扫描,并把结果数据重分布发送给第二组 Gang;第二组 Gang 在 2 个 segments 上分别对表 students 顺序扫描,与第一组 Gang 发送到本 segment 的 classes 数据进行哈希关联,并将最终结果发送给 Master。
细节太多。比如全局锁检测,锁层级,join的调度等等。GP很复杂
一个compile time type str
https://gcc.godbolt.org/z/Kd8a77zez
Modern B-Tree Techniques https://w6113.github.io/files/papers/btreesurvey-graefe.pdf
Give Your Tail a Nudge
这个算法非常简单,请求是FIFO,把耗时高的放到耗时低的后面。这样延迟毛刺影响最小,延迟效果好
但是问题在于
- 怎么评估每个请求任务的耗时高低?任务又不是自描述的
- 交换CAS引起的延迟问题
TreeLine: An Update-In-Place Key-Value Store for Modern Storage
https://github.com/mitdbg/treeline
学习型索引在数据库中的应用实践
索引就是模型。
Range Index(以 B-Tree 为代表)可以看做是从给定 key 到一个排序数组 position 的预测过程;Point Index(以 Hash 为代表)可以看做是从给定 key 到一个未排序数组的 position 的预测过程;Existence Index(Bloom Filter)可以看做是预测一个给定 key 是否存在。因此,索引系统是可以用机器学习模型去替换的。
局限性: (1)仅支持只读场景; (2)线性模型不适用更复杂的数据分布; (3)不支持多维索引。
https://github.com/learnedsystems/RadixSpline/blob/master/include/rs/radix_spline.h
RS 索引的组成:Spline points 样条点和 Radix table。样条点是 key 的子集,经过选择后可以对任何查找键进行样条插值,从而在预设的误差范围内得出预测的查找位置。Radix table 有助于为给定的查找 key 快速定位正确的样条点。
在查找时,Radix table 用于确定要检查的样条点的范围。搜索这些样条点,直到找到围绕 key 的两个样条点。然后,使用线性插值来预测查找 key 在基础数据中的位置(索引)。因为样条插值是误差有界的,所以只需要搜索(小)范围的数据。
构建 Spline:构建模型 S (ki) = pi ± e,一种映射关系。
构建 Radix table:类似基树/trie,一个 uint32_t 数组,它将固定长度的 key 前缀(“radix bits”)映射到带有该前缀的第一个样条点。key 的前缀是基表中的偏移量,而样条点被表示为存储在基表中的 uint32_t 值(图中指针)
Order-Preserving Key Compression for In-Memory Search Trees
代码在这里 https://github.com/efficient/HOPE
##
笔记不错
https://zhenghe.gitbook.io/open-courses/cmu-15-445-645-database-systems/tree-indexes
一个gdb 的docker
https://github.com/danobi/gdb-scripts
学着怎么弄x.py怎么弄镜像
另外,了解一下podman https://podman.io/
C++ 静态反射与序列化
https://godbolt.org/z/TGaqKvoMz
https://github.com/eyalz800/zpp_bits
https://github.com/cbeck88/visit_struct#intrusive-syntax
https://github.com/MitalAshok/self_macro
Querying Parquet with Millisecond Latency
- Decode optimization
- Vectorized decode
- Streaming decode
- Dictionary preservation ?
- Projection pushdown
- Predicate pushdown
- RowGroup pruning
- Page pruning
- Late materialization
- I/O pushdown
Reduce Write Amplification by Aligning Compaction Output File Boundaries
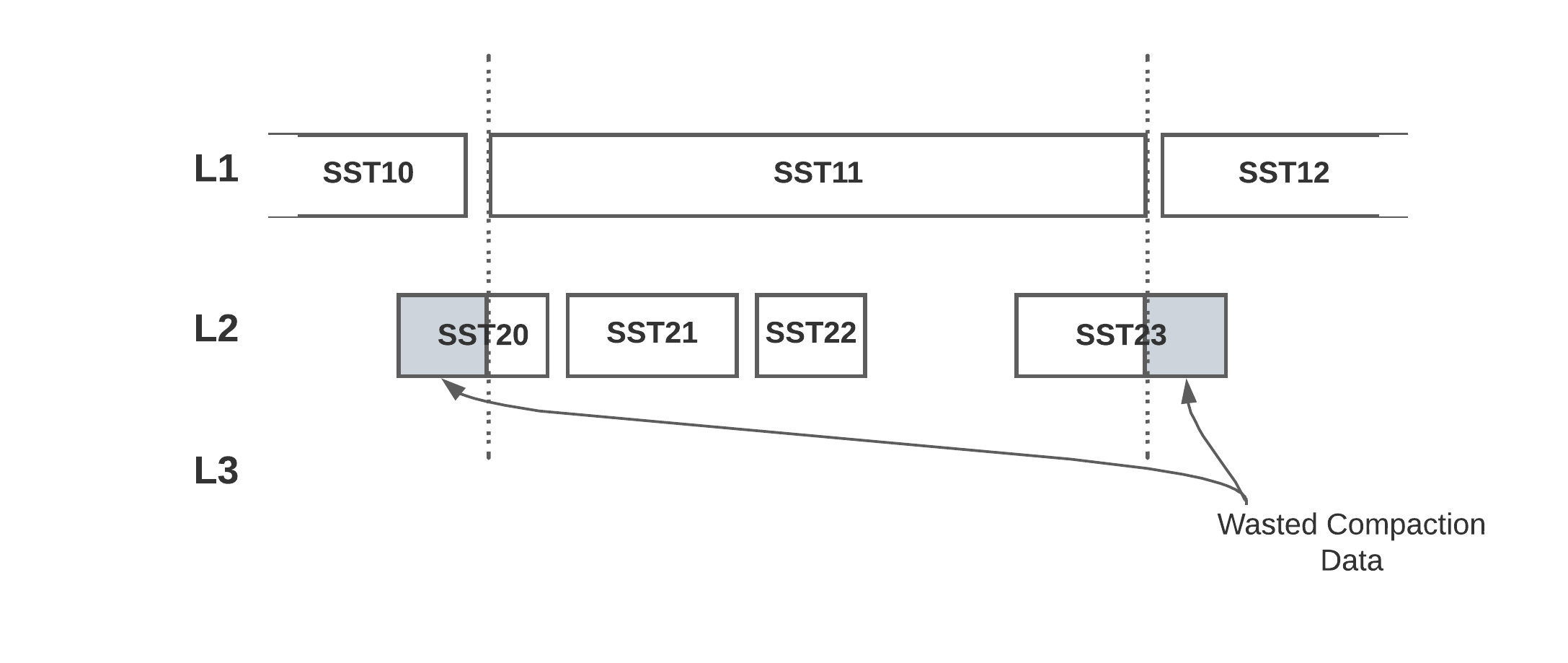
一张图概括
When to use materialized views?
复杂join物化视图加速
SELECT DISTINCT ON (images.id) external_uuid
FROM images
JOIN images_chapters qc ON images.id = qc.image_id
JOIN chapters c ON c.id = qc.chapter_id
JOIN images_sections qs ON images.id = qs.image_id
JOIN sections s ON s.id = qs.section_id
JOIN images_subjects qs2 ON images.id = qs2.image_id
JOIN subjects s2 ON s2.id = qs2.subject_id
JOIN images_topics qt ON images.id = qt.image_id
JOIN topics t ON t.id = qt.topic_id
WHERE s.name = 'ABSTRACT'
ORDER BY images.id
OFFSET <offset_page> LIMIT 10
这么复杂,确实值得物化一下
TODO
https://github.com/max0x7ba/atomic_queue
https://blog.csdn.net/XIao_MinK/article/details/119317058
https://www.modb.pro/db/430711
https://cloud.tencent.com/developer/article/2037556
https://zhuanlan.zhihu.com/p/420278969
https://critical27.github.io/c++/folly/future-defer/ https://critical27.github.io/page2/
https://mongoing.com/archives/26731
https://mongoing.com/archives/25302
https://mongoing.com/archives/38461
https://mongoing.com/archives/6102
https://zhuanlan.zhihu.com/p/166314742?utm_campaign=shareopn&utm_medium=social&utm_oi=1186410625499160576&utm_psn=1579863985591095296&utm_source=wechat_session
牢骚:
反正没人看到这里
没被毕业,但是感觉还不如毕业呢
