blog review 第十九期
双十一看了一下,电脑并没有降价。不过我还是下车了。详情看上一篇文章
和群友聊怎么提前升热一下,我感觉这种问题除了用流量预热之外比较无解,用只读 cache抗一下,群友给了个点子,proxy重放一下,确实可以,这个角度没有考虑过
主动预热,proxy记录key重放就相当于被动预热 。不过这个统计记录要有额外的开销。这种开销怎么均摊呢
这哥们博客不错,网络相关知识很多
可能是最完整的 TCP 连接健康指标工具 ss 的说明
TCP 连接健康最少包括:
TCP 重传统计,这是网络质量的风向标
MTU/MSS 大小,拥挤窗口的大小,这是带宽与吞吐的重要指标
各层收发队列与缓存的统计
# enter to the network namespace of that container, $HOST will be the name of the pod
sudo nsenter -n -u -t $PID
# nstat
current_time=$(date "+%Y.%m.%d-%H.%M.%S")
timeout 20m watch -n5 "nstat | tee -a /tmp/nstat-report-${current_time}-${HOST}"
输出
#kernel
IpInReceives 16256 0.0
IpInDelivers 16256 0.0
IpOutRequests 14269 0.0
TcpActiveOpens 234 0.0 #It means the TCP layer sends a SYN, and come into the SYN-SENT state. Every time TcpActiveOpens increases 1, TcpOutSegs should always increase 1.
TcpPassiveOpens 167 0.0 #It means the TCP layer receives a SYN, replies a SYN+ACK, come into the SYN-RCVD state
TcpEstabResets 222 0.0
TcpInSegs 16261 0.0
TcpOutSegs 14387 0.0 # 不包括重传
TcpRetransSegs 213 0.0 #重新传输的 TCP 包的总数
TcpOutRsts 154 0.0
UdpInDatagrams 10 0.0
UdpOutDatagrams 10 0.0
TcpExtTW 2 0.0
TcpExtDelayedACKs 93 0.0
TcpExtTCPHPHits 4901 0.0
TcpExtTCPPureAcks 516 0.0
TcpExtTCPHPAcks 5034 0.0
TcpExtTCPLostRetransmit 134 0.0 #A SACK points out that a retransmission packet is lost again.
TcpExtTCPTimeouts 213 0.0
TcpExtTCPBacklogCoalesce 12 0.0
TcpExtTCPAbortOnClose 151 0.0 #TCP非正常关闭
TcpExtTCPRcvCoalesce 140 0.0
TcpExtTCPSynRetrans 213 0.0 #连不上/SYN丢了
TcpExtTCPOrigDataSent 10674 0.0
TcpExtTCPDelivered 10817 0.0
IpExtInOctets 18794326 0.0
IpExtOutOctets 20261697 0.0
IpExtInNoECTPkts 16264 0.0
TCP包重传率 %retrans = (TcpOutSegs / TcpRetransSegs ) * 100
ss例子
sudo sysctl -a | grep tcp
net.ipv4.tcp_base_mss = 1024
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_max_tw_buckets = 262144
net.ipv4.tcp_mem = 766944 1022593 1533888 (page)
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_retries1 = 3
net.ipv4.tcp_retries2 = 15
net.ipv4.tcp_rfc1337 = 0
net.ipv4.tcp_rmem = 4096 131072 6291456
net.ipv4.tcp_adv_win_scale = 1 (½ memory in receive buffer as TCP window size)
net.ipv4.tcp_syn_retries = 6
net.ipv4.tcp_synack_retries = 5
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_wmem = 4096 16384 4194304
net.core.rmem_default = 212992
net.core.rmem_max = 212992
net.core.wmem_default = 212992
net.core.wmem_max = 212992
$ ss -taoipnm 'dst 100.225.237.27'
ESTAB 0 0 192.168.1.14:57174 100.225.237.27:28101 users:(("ssh",pid=49183,fd=3)) timer:(keepalive,119min,0)
skmem:(r0,rb131072,t0,tb87040,f0,w0,o0,bl0,d0) ts sack cubic wscale:7,7 rto:376 rtt:165.268/11.95 ato:40 mss:1440 pmtu:1500 rcvmss:1080 advmss:1448 cwnd:10 bytes_sent:5384 bytes_retrans:1440 bytes_acked:3945 bytes_received:3913 segs_out:24 segs_in:23 data_segs_out:12 data_segs_in:16 send 697050bps lastsnd:53864 lastrcv:53628 lastack:53704 pacing_rate 1394088bps delivery_rate 73144bps delivered:13 busy:1864ms retrans:0/1 dsack_dups:1 rcv_rtt:163 rcv_space:14480 rcv_ssthresh:64088 minrtt:157.486
#可见: rb131072 = net.ipv4.tcp_rmem[1] = 131072
###############停止接收端应用进程,让接收端内核层 Buffer 満####################
$ export PID=49183
$ kill -STOP $PID
$ ss -taoipnm 'dst 100.225.237.27'
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 0 0 192.168.1.14:57174 100.225.237.27:28101 users:(("ssh",pid=49183,fd=3)) timer:(keepalive,115min,0)
skmem:(r24448,rb131072,t0,tb87040,f4224,w0,o0,bl0,d4) ts sack cubic wscale:7,7 rto:376 rtt:174.381/20.448 ato:40 mss:1440 pmtu:1500 rcvmss:1440 advmss:1448 cwnd:10 bytes_sent:6456 bytes_retrans:1440 bytes_acked:5017 bytes_received:971285 segs_out:1152 segs_in:2519 data_segs_out:38 data_segs_in:2496 send 660622bps lastsnd:1456 lastrcv:296 lastack:24 pacing_rate 1321240bps delivery_rate 111296bps delivered:39 app_limited busy:6092ms retrans:0/1 dsack_dups:1 rcv_rtt:171.255 rcv_space:14876 rcv_ssthresh:64088 minrtt:157.126
#可见: 首次出现 app_limited
###################################
$ ss -taoipnm 'dst 100.225.237.27'
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 67788 0 192.168.1.14:57174 100.225.237.27:28101 users:(("ssh",pid=49183,fd=3)) timer:(keepalive,115min,0)
skmem:(r252544,rb250624,t0,tb87040,f1408,w0,o0,bl0,d6) ts sack cubic wscale:7,7 rto:376 rtt:173.666/18.175 ato:160 mss:1440 pmtu:1500 rcvmss:1440 advmss:1448 cwnd:10 bytes_sent:6600 bytes_retrans:1440 bytes_acked:5161 bytes_received:1292017 segs_out:1507 segs_in:3368 data_segs_out:42 data_segs_in:3340 send 663342bps lastsnd:9372 lastrcv:1636 lastack:1636 pacing_rate 1326680bps delivery_rate 111296bps delivered:43 app_limited busy:6784ms retrans:0/1 dsack_dups:1 rcv_rtt:169.162 rcv_space:14876 rcv_ssthresh:64088 minrtt:157.126
#可见:r252544 rb250624 在增长。Recv-Q = 67788 表示 TCP窗口大小是 67788(bytes)。因 net.ipv4.tcp_adv_win_scale = 1,即 ½ 接收缓存用于 TCP window,即 接收缓存 = 67788 * 2 = 135576(bytes)
###################################
$ kill -CONT $PID
$ ss -taoipnm 'dst 100.225.237.27'
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 0 0 192.168.1.14:57174 100.225.237.27:28101 users:(("ssh",pid=49183,fd=3)) timer:(keepalive,105min,0)
skmem:(r14720,rb6291456,t0,tb87040,f1664,w0,o0,bl0,d15) ts sack cubic wscale:7,7 rto:368 rtt:165.199/7.636 ato:40 mss:1440 pmtu:1500 rcvmss:1440 advmss:1448 cwnd:10 bytes_sent:7356 bytes_retrans:1440 bytes_acked:5917 bytes_received:2981085 segs_out:2571 segs_in:5573 data_segs_out:62 data_segs_in:5524 send 697341bps lastsnd:2024 lastrcv:280 lastack:68 pacing_rate 1394672bps delivery_rate 175992bps delivered:63 app_limited busy:9372ms retrans:0/1 dsack_dups:1 rcv_rtt:164.449 rcv_space:531360 rcv_ssthresh:1663344 minrtt:157.464
#可见: rb6291456 = net.ipv4.tcp_rmem[2] = 6291456
容器化 TCP Socket 缓存、接收窗口参数
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.core.optmem_max = 40960
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
How does RocksDB Memory Management work?
观察cache miss
TEST_TMPDIR=/dev/shm/ perf record -g ./db_bench -statistics -use_existing_db=true -benchmarks=readrandom -threads=32 -cache_size=1048576000 -num=1000000 -reads=1000000 && perf report -g --children
挑战
Memory is shared by multiple processes and also depends on persistent storage and processor access for many operations - congestion increases as usage increases
Moving more data in and out of the block cache increases overhead and can bring down system performance.
Increasing SST Files also means more bloom filters are loaded in memory and additional CPU overhead - balancing speed and efficiency for queries will impact the system memory and other processes.
Background processes (e.g. flushing to SST, compaction) also use system resources which may compete with active memory used by memtable.
Data architecture and operational processes (e.g. shared WAL, backups, snapshots) will affect overall memory usage and performance.
I/O hangs are more prevalent as database size increases and more data movement in and out of memory creates system congestion.
SSD lifespan will be impacted as data size and I/O increases because of how writes and rewrites impact how SSDs operate.
Reduce Write Amplification by Aligning Compaction Output File Boundaries
7.8.3降低compact写放大
压测命令
TEST_TMPDIR=/data/dbbench ./db_bench --benchmarks=fillrandom,readrandom -max_background_jobs=12 -num=400000000 -target_file_size_base=33554432
rate limiter
https://github.com/yugabyte/yugabyte-db/issues/13404
https://github.com/facebook/rocksdb/wiki/Rate-Limiter
http://rocksdb.org/blog/2017/12/18/17-auto-tuned-rate-limiter.html
hashkv
Entropy coding Trie ECT
Entropy coding – > 比如霍夫曼编码
https://ehds.github.io/2021/06/13/silt-entropy-encoding-explain/
https://github.com/silt/silt
https://github.com/efficient/mica
https://github.com/efficient/mica2
https://emperorlu.github.io/files/%E9%94%AE%E5%80%BC%E5%AD%98%E5%82%A8%E4%BC%98%E5%8C%96%E8%AE%BA%E6%96%87%E7%BB%BC%E8%BF%B0.pdf
https://github.com/emperorlu/Learned-Rocksdb
这个论文分享不错https://github.com/CDDSCLab/Weekly-Group-Meeting-Paper-List
Speeddb开源
使用了hash的memtable?和pair bloom filter。没测性能
Introducing Memsniff: A Robust Memcache Traffic Analyzer
抓网卡流量,拿流量做统计
Understanding the Snowflake Query Optimizer
Scan reduction
列存,读取快,扫描按照partitaion优化,用不到的直接跳过,对于table处理也是相同的,用不到就跳过
Query rewriting
推荐看这个 https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-Optimizer.html 卧槽这也太多了吧
比较常规,什么利用物化视图
常量函数内联
CREATE FUNCTION discount_rate(paid, retail_price)
AS
SELECT 1 - (paid / retail_price)
;
-- Before
SELECT
order_id
, discount_rate(order_value, total_sku_price) as discount_rate_pct
^^^^^^^^^^^^^
FROM orders
-- After
SELECT
order_id
, 1 - (order_value / total_sku_price) as discount_rate_pct
FROM orders
惰性求值
-- Before
SELECT
order_id
, parse_geolocation(address) as geolocation
^^^^^^^^^^^^^^^^^
FROM orders
WHERE
is_cancelled = TRUE
-- After
WITH cancelled_orders AS (
SELECT
order_id
, address
FROM orders
WHERE
is_cancelled = TRUE
)
SELECT
order_id
, parse_geolocation(address) as geolocation
FROM cancelled_orders
过滤无用的列
-- Before
WITH users AS (
SELECT *
^^^^^^^^
FROM users_raw
)
SELECT
user_id
FROM users
WHERE
account_type = 'paid'
-- After
WITH users AS (
SELECT
user_id
, account_type
FROM users_raw
)
SELECT
user_id
FROM users
WHERE
account_type = 'paid'
谓词下推
-- Before
WITH orders AS (
SELECT *
FROM orders_raw
)
SELECT
SUM(order_value) AS last_month_revenue
FROM orders
WHERE
order_date BETWEEN '2022-08-01' AND '2022-08-31'
^^^^^^^^^^
-- After
WITH orders AS (
SELECT *
FROM orders_raw
WHERE
order_date BETWEEN '2022-08-01' AND '2022-08-31'
)
SELECT
SUM(order_value) AS last_month_revenue
FROM orders
Join optimization
Join filtering
Transitive predicate generation,filter+重写
-- Before
SELECT *
FROM (
SELECT *
FROM website_traffic_by_day
WHERE traffic_date >= '2022-09-01'
^^^^^^^^^^^^
) AS traffic
LEFT JOIN revenue_by_day AS revenue
ON traffic.traffic_date = revenue.order_date
-- After
SELECT *
FROM (
SELECT *
FROM website_traffic_by_day
WHERE traffic_date >= '2022-09-01'
) AS traffic
LEFT JOIN (
SELECT *
FROM revenue_by_day
WHERE order_date >= '2022-09-01'
) AS revenue
ON traffic.traffic_date = revenue.order_date
Predicate ordering, 常规
-- Before
SELECT
FROM inventory
JOIN products
ON inventory.category = products.category
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AND inventory.stock_date = products.first_active_date
-- After
SELECT
FROM inventory
JOIN products
ON inventory.stock_date = products.first_active_date
AND inventory.category = products.category
Join elimination
根据外键限制来过滤
参考文档 https://www.scattered-thoughts.net/writing/materialize-decorrelation
https://www.youtube.com/watch?v=CPWn1SZUZqE&list=PLSE8ODhjZXjagqlf1NxuBQwaMkrHXi-iz&index=20
What Factors Affect Performance in RocksDB?
speeddb分享
Umbra: A Disk-Based System with In-Memory Performance
有点长
0x01 基本设计 UMbra选择的最小的page大小为64KB,比常见的page要大。而且会有多个不同的page大小,后面的大小按照2倍的方式增长,理论上一个page的大小可以和整个buffer pool一样大。不过实际上大小一般都是最小的几种大小。这些不同大小的page由一个统一的buffer pool来处理。在处理将这些磁盘上面的数据load到内存中的方式上面,Umbra使用mmap来映射一个内存区域,每个大小的size class都会使用一个单独的mmap映射的区域。一个buffer frame中会保存一个指向这个page的指针。这个buffer frame中的pointer保存的指针信息在数据库运行过程中是不会改变的。 为了将数据load到内存里面,需要读取一个page的数据库的时候,就使用pread这样的syscall将数据load到mmap映射的内存的位置。mmap映射的内存是在使用的时候才会实际分配。所以一开始为每个size class的page mmap可以放下整个buffer pool的内存区域也是可以的。在需要驱逐一个page的时候,如果是一个dirty page则需要写会磁盘。一个dirty page在数据写会磁盘的之后,使用madvise的MADV_DONTNEED来提示内核在必要的时候对应的内存可以回收。以此来保证buffer pool使用的内存在一个配置的size里面。这里映射是匿名映射,madvise with MADV_DONTNEED操作实际上没啥很大的开销。在page淘汰算法上面,使用的是LeanStore那样的思路。 Paper中认为仅仅是使用了变长的page不会解决所有的问题。为了继续优化,同样地,Umbra也引入了LeanStore中的Pointer Swizzling的思路。为了避免使用PID来管理在内存中的page,Umbra引用一个page的64bit值可以是内存中的一个地址,也可能是磁盘上面page的PID。区别通过最低的一个bit来表示。如果最低的bit为0,则为高63bit为一个pointer。否则,63bit分为两个部分,低位的6bit表示size class,高57bit表示PID。这样可以表示的size class数量为64种。在这种设计下面,需要保证一个page只会被一个pointer引用,以及使用的page eviction方式也需要修改,相关的思路在LeanStore的论文中[2]。 另外一个是Latch的优化。每个内存中的buffer frame会有一个64bit的versioned latch。这个latch可以是exclusive,shared或者是optimistic的方式来获取。64bit被分为5bit的state信息和59bit的version。state中记录了这个latch是否被获取,以及处理哪一种的模式之下。而version部分用于optimistic中访问数据是否还是有效的检查。exclusive模式下state被设置为1,而shared模式下面设置为n+1,n表示同时请求了这个latch的线程的数据。这个5bit的state可能在一些情况下这个不该用,这个时候就会使用一个额外的counter。另外,无论是latch是被获取为exclusive模式 or shared模式,都可以在optimistic的模式下面使用。optimistic模式只能是读取操作使用,读取之前需要获取version值,而读取完成之后需要检查这个version。由于这个数据可能已经被修改了,这样检查不对就需要重新读取操作。 在结构上面,Umbra使用B+tree来组织数据,而每个tuple使用一个8byte的ID来标识,这个ID是自增的(that tuple identifiers increase strictly monotonically),这样避免了一些麻烦。另外在分配新node的时候也等到目前的inner node和leaf node都满了才分配。Inner node总是使用最小的page size。Leaf page中的数据使用PAX格式来保存数据。Umbra使用的Recovery方式也是ARIES风格的方式。Paper中这里提到了要特别处理的一个问题就是,要保证在原来保存一个大size的page的位置去保存一个较小的page的课恢复性。比如一个128KB的空间开始存储了一个128KB的page,后面将其load到内存,一些操作之后这个page被删除。然后创建了2个新的64KB的page。如果这个时候系统crash,可以可能存在的情况是完成了些相关的log记录,而没有实际的page数据。这样可能导致读取到之前的旧数据。目前Umbra的方式是只会reuse同样size的disk space。 Paper中还提到了一些其它的优化,比如其string的结构。Umbra使用16byte header保存一个string的元数据,4byte表示长度,而如果string长度12以内的话,直接保存在这个header中。如果超过了12,则可能保存一个prefix,地址信息记录为offset值或者是一个pointer,根据是否在内存中来选择不同的方式。string保存out-of-line的数据会细分为persistent, transient, 以及 temporary几种, References to a string with persistent storage, e.g. query constants, remain valid during the entire uptime of the database. References to a string with transient storage duration are valid while the current unit of work is being processed, but will eventually become invalid. ... Finally, strings that are actually created during query execution, e.g. by the UPPER function, have temporary storage duration. While temporary strings can be kept alive as long as required, they have to be garbage collected once their lifetime ends. Umbra中也同样适用来查询编译的技术,不过这个团队前面开发的Hyper不同,其使用了一种自定义的IR,而不是使用LLVM,可以获取更加为查询编译优化的设计。另外查询编译也使用了adaptive编译的方式,在必要的时候才会编译执行。编译和在Hyper中将查询变为一个大的可执行的code fragment不同,Umbra将其编译为很多 fine-grained的部分,变现为一个modular state machines。比如select count(*) from supplier group by s_nationkey这样的查询被编译为如下图所示的部分。主要分为2个pipeline,第1个为scan操作,第二个为group操作。Pipeline有分为了多个step,每个step可以是单线程 or 多线程来执行。每个step编译为一个function。查询操作抽象为在这些step中的数据转化操作。多线程的时候使用morsel-driven的方式。分布式存储在B站的应用实践
面临问题——存储引擎
前面提到的compaction,在实际使用的过程中,也碰到了一些问题,主要是存储引擎和raft方面的问题。存储引擎方面主要是Rocksdb的问题。第一个就是数据淘汰,在数据写入的时候,会通过不同的Compaction往下推。我们的播放历史,会设置一个过期时间。超过了过期时间之后,假设数据现在位于L3层,在L3层没满的时候是不会触发Compaction的,数据也不会被删除。为了解决这个问题,我们就设置了一个定期的Compaction,在Compaction的时候回去检查这个Key是否过期,过期的话就会把这条数据删除。
另一个问题就是DEL导致SCAN慢查询的问题。因为LSM进行delete的时候要一条一条地扫,有很多key。比如20-40之间的key被删掉了,但是LSM删除数据的时候不会真正地进行物理删除,而是做一个delete的标识。删除之后做SCAN,会读到很多的脏数据,要把这些脏数据过滤掉,当delete非常多的时候,会导致SCAN非常慢。为了解决这个问题,主要用了两个方案。第一个就是设置删除阈值,超过阈值的时候,会强制触发Compaction,把这些delete标识的数据删除掉。但是这样也会产生写放大的问题,比如有L1层的数据进行了删除,删除的时候会触发一个Compaction,L1的文件会带上一整层的L2文件进行Compaction,这样会带来非常大的写放大的问题。为了解决写放大,我们加入了一个延时删除,在SCAN的时候,会统计一个指标,记录当前删除的数据占所有数据的比例,根据这个反馈值去触发Compaction。
第三个是大Value写入放大的问题,目前业内的解决办法都是通过KV存储分离来实现的。我们也是这样解决的。
Raft层面的问题有两个:
首先,我们的Raft是三副本,在一个副本挂掉的情况下,另外两个副本可以提供服务。但是在极端情况下,超过半数的副本挂掉,虽然概率很低,但是我们还是做了一些操作,在故障发生的时候,缩短系统恢复的时间。我们采用的方法就是降副本,比如三个副本挂了两个,会通过后台的一个脚本将集群自动降为单副本模式,这样依然可以正常提供服务。同时会在后台启动一个进程对副本进行恢复,恢复完成后重新设置为多副本模式,大大缩短了故障恢复时间。
另一个是日志刷盘问题。比如点赞、动态的场景,value其实非常小,但是吞吐量非常高,这种场景会带来很严重的写放大问题。我们用磁盘,默认都是4k写盘,如果每次的value都是几十个字节,这样会造成很大的磁盘浪费。基于这样的问题,我们会做一个聚合刷盘,首先会设置一个阈值,当写入多少条,或者写入量超过多少k,进行批量刷盘,这个批量刷盘可以使吞吐量提升2~3倍。
InnoDB:DDL(3)
不懂
Facebook开源的Velox,到底长什么样,浅读VLDB 2022 velox paper
不懂
ByteHTAP 论文阅读笔记
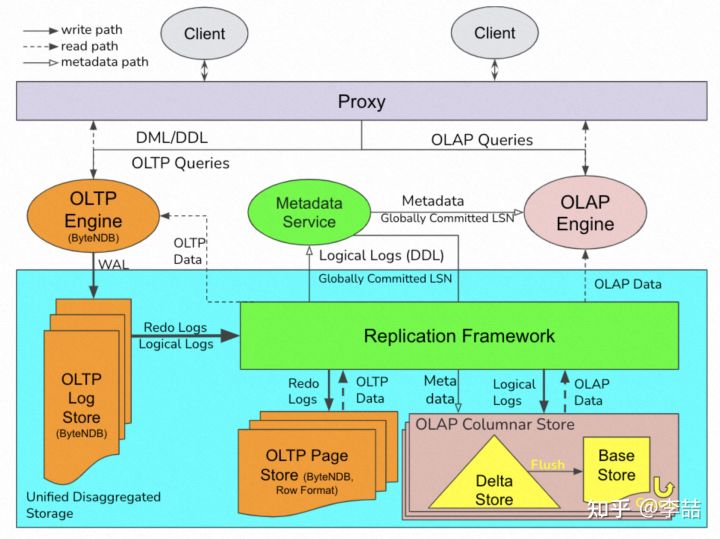
ByteHTAP 在此基础上进行扩展。将 log 复制到 page store 和 column store。Column store 即支持 OLAP 的存储格式,为了加速 join 目前只按照 hash 进行 partition。每个 partition 会被复制三份存放到不同节点。每个 partition 分为 in-memory delta store (可包含多个 version) 和 持久化的 base store (只有一个 version,即 flush 时的 version,与其对应的 in-memory delta store 位于同一节点)。
Delta store 维护一个 insertion list 和 delete list (为了加速查找使用了一个额外的 delete hash map)。Delta store 支持四种操作:
log apply:被复制的 insert log 和 delete log 会分别被 append (以 LSN 为序) 到 insertion list 和 delete list (并以 primary key 为 key 加入一条记录到 delete hash map)。flush:一个后台任务定期 切一段 Delta store 内的行存 数据出来(剔除已经被删除的),排序并转成 列存 并加入到 Base store,并根据 delete list 更新 base store 的 delete bitmap。// 所以刚写入 base store 的每个 block之间数据是可能有 overlap 的garbage collection:上面被切出来合并到 Base store 这部分数据,如果没有 active scan 正在使用,则所占用的内存可以被回收。注意这是目前唯一回收内存的方式,Delta store 内数据并不会被换入换出。scan:snapshot read,based on LSN(结果需要与 Base store 的结果合并后返回)
Base store 文件以 PAX 格式组织,包含多个 32MB 大小的 block,按 primary key 排序。每个 block 存有 meta data,包含 number of rows, key range, bloom flter for primary keys, and per-column statistics like min/max。Delete bitmap 使用 RocksDB 存储。Base store 实现了一个 groom 操作,其实就是 压缩 + garbage collection,目的在于真正删除 delete bitmap 里的数据以及 合并 从 Delta store flush 下来的多个 block。这是一个定期后台任务,它会根据 delete rate 和 primary key overlapping rate 自动挑选需要处理的 blocks(这和 Snowflake 有点像了)。
很复杂。运维压力?
公关关键字veDB
Kudu: Storage for Fast Analytics on Fast Data
小伙博客不错,结论,kudu有点不靠谱
不过facebook用 kudu做了个kuduraft
Lessons learned from 10 years of DynamoDB
PITR数据校验
元数据访问不能崩,多副本cache顶住
Code Engine - Powered by Wasm
我看redpanda也用,https://redpanda.com/blog/wasm-architecture
这个方向得注意一下,比如这个 https://github.com/WasmEdge/WasmEdge/blob/master/README-zh.md
公司也用了wasm,UDF加速
Welcome to InfluxDB IOx: InfluxData’s New Storage Engine
基于arrow??
PostgreSQL Performance Puzzle
todo
Postgres: Safely renaming a table with no downtime using updatable views
视图,没啥说的
BEGIN;
ALTER TABLE chainwheel
RENAME TO sprocket;
CREATE VIEW chainwheel AS
SELECT *
FROM sprocket;
COMMIT;
Storage engines, efficiency and large documents, rows, objects
从存储 write back 复制 redolog 部分更新这几个角度评估存储引擎
RocksDB RateLimiter解析与实践
怎么用rate limiter rate_bytes_per_sec:数据写入的总速率,它包括compaction和flush的速率 refill_period_us:token被更新的周期,默认为100ms; fairness:低优先级请求(compaction)相较高优先级请求(flush)获取token的概率。默认为10%; mode:限速的类型,读、写、读写,默认是对写请求进行限速; auto_tuned:是否开启auto_tune,默认为不开启
代码
static std::once_flag flag;
std::call_once(flag, [&]() {
_s_rate_limiter = std::shared_ptr<rocksdb::RateLimiter>(rocksdb::NewGenericRateLimiter(
FLAGS_rocksdb_limiter_max_write_megabytes_per_sec << 20,
100 * 1000, // refill_period_us
10, // fairness
rocksdb::RateLimiter::Mode::kWritesOnly,
FLAGS_rocksdb_limiter_enable_auto_tune));
});
_db_opts.rate_limiter = _s_rate_limiter;
崩溃思想
https://chromium.googlesource.com/breakpad/breakpad/
https://github.com/apple/foundationdb/tree/main/flow
https://github.com/ClickHouse/ClickHouse/blob/master/src/Common/ThreadFuzzer.h
Avoiding reads in write-optimized index structures
写优化的索引,怎么降低索引读?因为变更会引起失效
- rocksdb提供merge,可以推迟读到查/compact
- 读备份 ,比如 toku myrocks都提供
- Fast update tokudb 和 rocksdb merge差不多
- myrocks PK secondary index限制
- myrocks singleDelete优化,可以 提前清除tombstone
- innodb有change buffer,记录secondary index 变动 https://dev.mysql.com/doc/refman/8.0/en/innodb-change-buffer.html
- Diff-Index: Differentiated Index in Distributed Log-Structured Data Stores
其他
# ulimit
ulimit -a
#
sysctl -w "fs.file-max=6525651"
echo fs.file-max =6525651 >> /etc/sysctl.conf
sysctl -p
#
ulimit -HSn 65535
sed -i '/# End of file/ i\* soft nofile 65535' /etc/security/limits.conf
sed -i '/# End of file/ i\* hard nofile 65535' /etc/security/limits.conf
cat nf_conntrack_max
1048576
