blog review 第十七期
看tag知内容
The Slotted Counter Pattern
数据库记录page view可能用一个counter,但是多个更新会卡,所以可以一个客户端更新一个slot对应的counter,然后做汇总
这不就是threadlocalcounter的技巧么。数据库上也适用
Segmented LRU替换算法
如果我们仔细对比了LRU和SLRU的代码,可以发现区别并不像之前我们说的这么多。如果我们将保护段和试用段连到一起,你就会发现,SLRU和LRU唯一的区别就是当一个不在缓存中的行进入缓存时,LRU算法将它放在了第0号位置,即Most Recently Used的位置,而SLRU算法将它放在了不那么高的一个位置,即保护段和试用段连接处的位置。这样SLRU算法就不会担心某一些特定代码段(比如短时间塞入了大量无用缓存行)会完全破坏缓存的有效性了。
区别就这
TinyLFU: A Highly Efficient Cache Admission Policy
这人博客不错

这玩意就是多一个记录统计,来判定谁更应该淘汰。由于时效性原因,还引入窗口机制。有点意思
mongodb数组更新运算符($、$[]、$[<identifier>])
线上有个业务表,非常猥琐的更新一个数组中某个文件记录的checksum,一层套一层
db.task.update({"request.taskid":"idxx","request.subtaskid":"sidxx", "files.backup.cosfiles.filepath":"/filexx"},{$set:{"files.backup.cosfiles.$.checksum":"checksumxx"}})
更改数组中filexx的checksum为checksumxx
太恶心了
小红书KV存储架构:万亿级数据与跨云多活不在话下
Proxy层由一个无状态CorvusPlus进程组成。它兼容老的Redis Client,扩缩容、升级对无Client和后端集群无感,支持多线程、IO多路复用和端口复用特性。对比开源版本,CorvusPlus增强了自我防护和可观测特性,实现了可在线配置的功能特性: Proxy限流 基于令牌桶的流控算法支持了对连接数、带宽和QPS多维度限流。在高QPS下,我们的Proxy限流防止了雪崩,如图2;在大带宽场景下,我们优化了时延 数据在线压缩 Proxy层本身只做路由转发,对CPU的消耗非常低。在大带宽的场景下,我们可以充分利用Proxy的CPU资源优化带宽和毛刺。在解析Redis协议时,使用LZ4算法对写入数据进行在线压缩,读取时在线解压。在推荐缓存的使用场景中网络带宽和存储空间压缩40%以上(如图4),总体时延并没有明显的下降。因为网络带宽和写入读取数据的减少,时延毛刺也变小了 线程模型优化 proxy的收发包有类似negle模式的优化,没有必要 backup-read优化长尾 大key检测
文章还有很多其他的点。proxy的我觉得有意思,单独说下
各种HashMap的性能对比
这个压测从基数(key重复程度)的角度比较,很有意思
比Bloom Filter节省25%空间!Ribbon Filter在Lindorm中的应用
这玩意rocksdb发布的,但是没见别人用过。lindorm可能是第一个落地的?
diskexploer
scylladb用的硬盘测试工具
https://github.com/microsoft/wil/pull/244/files
这个pr 看到个检测成员函数的猥琐用法
template<typename T> struct is_winrt_vector_like {
private:
template <typename U,
typename = decltype(std::declval<U>().GetMany(std::declval<U>().Size(),
winrt::array_view<decltype(std::declval<U>().GetAt(0))>{}))>
static constexpr bool get_value(int) { return true; }
template <typename> static constexpr bool get_value(...) { return false; }
public:
static constexpr bool value = get_value<T>(0);
};
https://github.com/leanstore/leanstore
https://www.cidrdb.org/cidr2021/papers/cidr2021_paper21.pdf
CockroachDB's Consistency Model
Strict-serializability, but at what cost, for what purpose?
严格一致性要求事务串行,实现也很复杂,业务很少用到,代价很大。spanner为啥会用到这个?因为schema变更需要保证?
spanner做法,True-Time,时间片
或者提供一个中心时间服务,这个服务同步时间,各个节点都同步一下,多数派同意之类的(Calvin)
还有什么业务需求需要这种级别的一致性?
A read-only transaction anomaly under snapshot isolation
Snapshot isolation SI保证事务看到的是当前db的一个快照版本
MemQ: An efficient, scalable cloud native PubSub system
It uses a decoupled storage and serving architecture similar to Apache Pulsar and Facebook Logdevice;
logdevice都没了 https://github.com/facebookarchive/LogDevice,据说是整了个新的
格式
Improving Distributed Caching Performance and Efficiency at Pinterest
设置SCHEDULE_FIFO达到这个效果 ` sudo chrt — — fifo
另外还有TCP Fast Open配置
RocksDB源码 - Cuckoo Hashing
最近有个点子,把fasterkv那套东西挪到rocksdb上。就类似blobdb,写的是index,追加的文件是HLOG文件。其实是很有搞头的,又能保证稳定性。
看代码看到cuckoo hash table 突然发现可能rocksdb已经做过。搜集了相关资料,发现做的比较粗糙,没人用。所以我这个点子还是非常可行的。
这个cuckoo hashtable实现讲真,感觉不是很靠谱啊
用blobdb,复用这个框架。可以吧无关的代码都去掉。已有的代码比较复杂
inuring介绍 https://kernel.dk/axboe-kr2022.pdf
Correctness Anomalies Under Serializable Isolation
| System Guarantee | 脏读 | 不可重复读 | 幻读 | Write Skew | Immortal write | Stale read | Causal reverse |
|---|---|---|---|---|---|---|---|
| RU | P | P | P | P | P | P | P |
| RC | N | P | P | P | P | P | P |
| RR | N | N | P | P | P | P | P |
| SI | N | N | N | P | P | P | P |
| SERIALIZABLE / ONE COPY SERIALIZABLE / STRONG SESSION SERIALIZABLE |
N | N | N | N | P | P | P |
| STRONG WRITE SERIALIZABLE | N | N | N | N | N | P | N |
| STRONG PARTITION SERIALIZABLE | N | N | N | N | N | N | P |
| STRICT SERIALIZABLE | N | N | N | N | N | N | N |
How the SQLite Virtual Machine Works
还算通俗易懂
Socrates: The New SQL Server in the Cloud (Sigmod 2019)
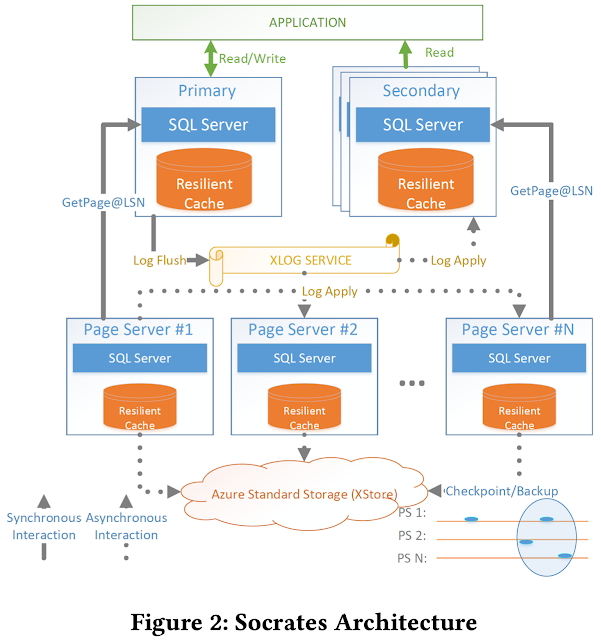
四层卧槽
第一层就是cache 无状态。挂了就挂了,预热过程怎么搞??击穿岂不是很恐怖?直接从page server查。本身cache也可dump。来规避这种场景
第二层xlog,log复制。这个要保证数据不丢。这个是重点
第三层page server,xlog刷到page server, pageserver 异步拷贝到cache里。
要是频繁改动这能受得了????Shared-disk,底层应该是分布式数据库,有快速路径访问的。所以无状态。应该有scheduler来规划路径吧。没说 这种挂了就挂了。再拉起来就好了。没啥影响。问题在于路径分片管理,扩容分裂。没说????
第四层是Azure Storage Service 硬盘。定时备份到这层。也偶尔从这个拉数据。也作为远程冷存使用
xlog
整体架构

xlog处理数据,写到Leading zone(LZ),写三分,用的是 Azure Premium Storage service (XIO) LZ你可以理解成一堆小块(说不定是PMEM)。LZ组成一个circle buffer,挨个写
同时也同步给副本和page server。page server / 副本拉取数据。所以要有个LogBroker。pageserver可能数量非常多
挺复杂 交互很多。这里有个讲的比我好的 https://zhuanlan.zhihu.com/p/401929134
看下来,组件复用程度比较高。复杂。精炼但是复杂。上面那个哥们说singlestore(memsql)类似。我不太清楚
Hekaton: SQL Server’s Memory-Optimized OLTP Engine
不如看这个 https://fuzhe1989.github.io/2021/05/18/hekaton-sql-servers-memory-optimized-oltp-engine/
一种通过 skip cache 加速重复查询的方法
AP能优化上
我在想,rocksdb的blobdb模式,为啥不加个hash index。加了是不是会快很多
