blog review 第十一期
看tag知内容 尴尬,每月总结也有todo了,todo越欠越多
[toc]
redis module, tairhash
https://github.com/alibaba/TairHash/blob/main/README-CN.md
【译文】将Restartable Sequcences (rseq)引入Linux的五年之旅
这东西有啥用?我看tcmalloc用上了
- (default) per-CPU caching, where TCMalloc maintains memory caches local to individual logical cores. Per-CPU caching is enabled when running TCMalloc on any Linux kernel that utilizes restartable sequences (RSEQ). Support for RSEQ was merged in Linux 4.18.
- per-thread caching, where TCMalloc maintains memory caches local to each application thread. If RSEQ is unavailable, TCMalloc reverts to using this legacy behavior.
核级别缓存,降低竞争啊,本来就是Thread Caching
cosmos-db的文档可能是云产品文档的标杆了
布隆过滤器
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
大Value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。
或者,用redisbloom,由这个模块来管理
基本实现,通过hash映射来做key的统计,多个hash来映射set,这样get的时候通过hash来判断是不是存在,0肯定不存在,1有可能是别的相同hash撞了
简单粗暴有覆盖性,但是数据不能删除,标记的是flag,有hash-flag一对多,不能简单的减掉
解决方案,Count Bloom filter,加个技术,就能减了,缺点,空间小了
引入新问题,空间浪费
CBF 虽说解决了 BF 的不能删除元素的问题,但是自身仍有不少的缺陷有待完善,比如 Counter 的引入就会带来很大的资源浪费,CBF 的 FP 还有很大可以降低的空间, 因此在实际的使用场景中会有很多 CBF 的升级版。
比如 SBF(Spectral Bloom Filter)在 CBF 的基础上提出了元素出现频率查询的概念,将CBF的应用扩展到了 multi-set 的领域;dlCBF(d-Left Counting Bloom Filter)利用 d-left hashing 的方法存储 fingerprint,解决哈希表的负载平衡问题;ACBF(Accurate Counting Bloom Filter)通过 offset indexing 的方式将 Counter 数组划分成多个层级,来降低误判率
有时间走读一下redisbloom的代码
为啥想到这个问题,主要是
- 最近同事用到了,我来复习一下,如果永远都是增量不删除,那么用最简单的就行了
- 看到了个学习型布隆过滤器 代码在这里 先用数据简单训练一波,然后再去评估。这个场景也是静态数据,训练最优的布隆过滤器。没啥工程参考价值
cookuo bloom filter?
Linux 进程状态浅析
一图流
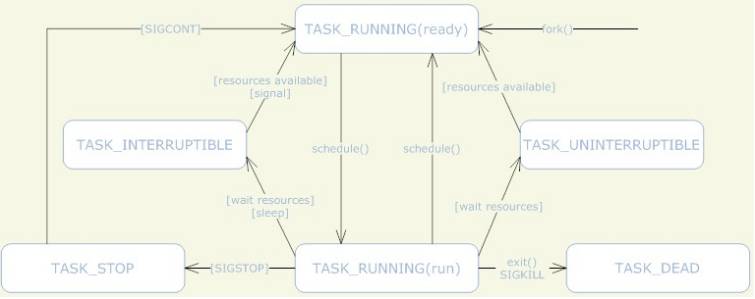
进程分析之IO
iostat -d -x:看各个设备的 I/O 状态,数据来源/proc/diskstatspidstat -d:看近处的 I/Oiotop:类似 top,按 I/O 大小对进程排序
Instat -> proc/io
[work@# ~]$ iostat
avg-cpu: %user %nice %system %iowait %steal %idle
3.70 0.34 6.23 0.03 0.00 89.70
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sdb 62.40 3247.81 5546.55 12637971586 21582874000
sda 6.95 67.44 197.56 262416346 768741064
//tps:设备的当前的每秒的数据传输次数,一次传输就是一个io服务
//Blk_read/Blk_wrtn/s 每秒的对写block次数,这里的blcok为扇区,即512Byte
//Blk_read/Blk_wrtn 累计的block读写次数
//
[work@# ~]$ iostat -x
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sdb 0.54 649.68 19.57 42.84 3247.83 5546.58 140.93 0.06 0.99 0.10 0.63
sda 0.09 15.80 1.11 5.85 67.44 197.56 38.12 0.07 9.56 0.90 0.63
//-x参数可以显示每个设备的详细的数据
//rrqm/wrqm:io读写会进入queue,并被合并,这里就被合并的次数
//rw/s:设备每秒的读写次数
//rwsec/s:设备每秒的读写扇区数目,基本与Blk_wrtn/s等保持相同
//avgrq-sz:设备读写块大小(扇区数),上面用8k进行dd测试的话,这个数字就是16=8×1024/512
//avgqu-sz:设备的queue平均大小,越大代表压力大
//await:io请求在queue中被堵塞的平均时长+io被处理完成的平均时长,相当于成功一次io的时间
//svctm:io被处理完成的平均时长,看await就可以
//%util:io利用率
[root@# ~]# cat /proc/20811/io
rchar: 133750354274 // 读出的总字节数,read或者pread中的长度参数总和
wchar: 1646551816314 // 写入的总字节数
syscr: 139026906 //read 系统调用的次数
syscw: 65789036 //waite 系统调用的次数
read_bytes: 79548416 //实际从磁盘中读取的字节总数
write_bytes: 1878315008 //实际从磁盘中读取的字节总数
cancelled_write_bytes: 20480 //由于截断pagecache导致应该发生而没有发生的写入字节数
进程分析之内存
free -> top -> cat /proc/20811/status cat /proc/meminfo
[work@# ~]$ cat /proc/20811/status
Name: scribed
State: S (sleeping)
Tgid: 20811
Pid: 20811
PPid: 1
TracerPid: 0
Uid: 500 500 500 500
Gid: 501 501 501 501
FDSize: 8192
Groups: 501
VmPeak: 20531460 kB //进程分配的虚拟内存峰值
VmSize: 18875052 kB //进程当前分配的虚拟内存大小
VmLck: 0 kB //进程当前加锁的内存大小,参考linux mlock
VmHWM: 1943192 kB //进程使用的物理内存峰值
VmRSS: 1357056 kB //进程当前使用的物理内存大小
VmAnon: 1350016 kB //匿名page大小,有些内存比如so占用内存都是有名称,参考meminfo的功能
VmFile: 7040 kB //so等文件占用内存大小,VmAnon+VmFile=VmRSS
VmData: 18711392 kB //进行数据段占用的虚拟内存大小
VmStk: 120 kB //进程堆栈段的虚拟内存大小
VmExe: 3652 kB //进程代码段的虚拟内存大小
VmLib: 12968 kB //进程所使用LIB库的虚拟内存大小
VmPTE: 4584 kB //占用的页表的大小.
VmSwap: 0 kB //交换分区大小
Threads: 56
SigQ: 0/385964
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000003
SigCgt: 1000000181005ccc
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: ffffffffffffffff
Cpus_allowed: fff
Cpus_allowed_list: 0-11
Mems_allowed: 00000000,00000003 //
Mems_allowed_list: 0-1 //表示进程可以使用的内存段,有点高端,就不解析含义了
voluntary_ctxt_switches: 3264080472
nonvoluntary_ctxt_switches: 794416
Work the Shell - Dealing with Signals | Linux Journal
kill实际上是发送信号,shell层发送信号其实是可以抓住的,除了kill -9
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGEMT 8) SIGFPE
9) SIGKILL 10) SIGBUS 11) SIGSEGV 12) SIGSYS
13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGURG
17) SIGSTOP 18) SIGTSTP 19) SIGCONT 20) SIGCHLD
21) SIGTTIN 22) SIGTTOU 23) SIGIO 24) SIGXCPU
25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH
29) SIGINFO 30) SIGUSR1 31) SIGUSR2
简单抓获
#!/bin/bash
trap 'echo " - Ctrl-C ignored" ' INT
while /usr/bin/true ; do
sleep 30
done
exit 0
同理,可以扩展一下
sigquit()
{
echo "signal QUIT received"
}
sigint()
{
echo "signal INT received, script ending"
exit 0
}
sigtstp()
{
echo "SIGTSTP received" > /dev/tty
trap - TSTP
echo "SIGTSTP standard handling restored"
}
trap 'sigquit' QUIT
trap 'sigint' INT
trap ':' HUP # ignore the specified signals
trap 'sigtstp' TSTP # ctrl z
echo "test script started. My PID is $$"
while /usr/bin/true ; do
sleep 30
done
新浪技术分享:我们如何扛下32亿条实时日志的分析处理
没啥说的,看图
Peeking into Linux kernel-land using /proc filesystem for quick’n’dirty troubleshooting
这个博客是大神tanel poder 写的,他的工具箱 仓库点这里
进程卡死了
ps -flp 27288
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
0 D root 27288 27245 0 80 0 - 28070 rpc_wa 11:57 pts/0 00:00:01 find . -type f
WCHAN是什么东西?
查看进程proc目录
[root@oel6 ~]# cat /proc/27288/wchan
rpc_wait_bit_killable
这通常意味着和别的进程打交道中,啥状态?
cat /proc/27288/status
Name: find
State: D (disk sleep)
Tgid: 27288
Pid: 27288
PPid: 27245
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 256
Groups: 0 1 2 3 4 6 10
VmPeak: 112628 kB
VmSize: 112280 kB
VmLck: 0 kB
VmHWM: 1508 kB
VmRSS: 1160 kB
VmData: 260 kB
VmStk: 136 kB
VmExe: 224 kB
VmLib: 2468 kB
VmPTE: 88 kB
VmSwap: 0 kB
Threads: 1
SigQ: 4/15831
SigPnd: 0000000000040000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000000
SigCgt: 0000000180000000
CapInh: 0000000000000000
CapPrm: ffffffffffffffff
CapEff: ffffffffffffffff
CapBnd: ffffffffffffffff
Cpus_allowed: ffffffff,ffffffff
Cpus_allowed_list: 0-63
Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001
Mems_allowed_list: 0
voluntary_ctxt_switches: 9950
nonvoluntary_ctxt_switches: 17104
disk sleep, 不可打断,注意这个switch,非常频繁
查看一下调度状态
[root@oel6 ~]# cat /proc/27288/sched
find (27288, #threads: 1)
---------------------------------------------------------
se.exec_start : 617547410.689282
se.vruntime : 2471987.542895
se.sum_exec_runtime : 1119.480311
se.statistics.wait_start : 0.000000
se.statistics.sleep_start : 0.000000
se.statistics.block_start : 617547410.689282
se.statistics.sleep_max : 0.089192
se.statistics.block_max : 60082.951331
se.statistics.exec_max : 1.110465
se.statistics.slice_max : 0.334211
se.statistics.wait_max : 0.812834
se.statistics.wait_sum : 724.745506
se.statistics.wait_count : 27211
se.statistics.iowait_sum : 0.000000
se.statistics.iowait_count : 0
se.nr_migrations : 312
se.statistics.nr_migrations_cold : 0
se.statistics.nr_failed_migrations_affine: 0
se.statistics.nr_failed_migrations_running: 96
se.statistics.nr_failed_migrations_hot: 1794
se.statistics.nr_forced_migrations : 150
se.statistics.nr_wakeups : 18507
se.statistics.nr_wakeups_sync : 1
se.statistics.nr_wakeups_migrate : 155
se.statistics.nr_wakeups_local : 18504
se.statistics.nr_wakeups_remote : 3
se.statistics.nr_wakeups_affine : 155
se.statistics.nr_wakeups_affine_attempts: 158
se.statistics.nr_wakeups_passive : 0
se.statistics.nr_wakeups_idle : 0
avg_atom : 0.041379
avg_per_cpu : 3.588077
nr_switches : 27054
nr_voluntary_switches : 9950
nr_involuntary_switches : 17104
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 72
nr_switches number (which equals nr_voluntary_switches + nr_involuntary_switches). 非常频繁
这个值也可以通过
[root@oel6 ~]# cat /proc/27288/schedstat
1119480311 724745506 27054
来查
到底卡在哪里了,strace gdb/pstack都抓不到?卡在内核里?
查内核
[root@oel6 ~]# cat /proc/27288/syscall
262 0xffffffffffffff9c 0x20cf6c8 0x7fff97c52710 0x100 0x100 0x676e776f645f616d 0x7fff97c52658 0x390e2da8ea
262是什么?
[root@oel6 ~]# grep 262 /usr/include/asm/unistd_64.h
#define __NR_newfstatat 262
这么麻烦?有没有更简单的查法?
[root@oel6 ~]# cat /proc/27288/stack
[] rpc_wait_bit_killable+0x24/0x40 [sunrpc]
[] __rpc_execute+0xf5/0x1d0 [sunrpc]
[] rpc_execute+0x43/0x50 [sunrpc]
[] rpc_run_task+0x75/0x90 [sunrpc]
[] rpc_call_sync+0x42/0x70 [sunrpc]
[] nfs3_rpc_wrapper.clone.0+0x35/0x80 [nfs]
[] nfs3_proc_getattr+0x47/0x90 [nfs]
[] __nfs_revalidate_inode+0xcc/0x1f0 [nfs]
[] nfs_revalidate_inode+0x36/0x60 [nfs]
[] nfs_getattr+0x5f/0x110 [nfs]
[] vfs_getattr+0x4e/0x80
[] vfs_fstatat+0x70/0x90
[] sys_newfstatat+0x24/0x50
[] system_call_fastpath+0x16/0x1b
[] 0xffffffffffffffff
有个常用的查系统的脚本
[root@oel6 proc]# for i in `pgrep worker` ; do ps -fp $i ; cat /proc/$i/stack ; done
UID PID PPID C STIME TTY TIME CMD
root 53 2 0 Feb14 ? 00:04:34 [kworker/1:1]
[] __cond_resched+0x2a/0x40
[] lock_sock_nested+0x35/0x70
[] tcp_sendmsg+0x29/0xbe0
[] inet_sendmsg+0x48/0xb0
[] sock_sendmsg+0xef/0x120
[] kernel_sendmsg+0x41/0x60
[] xs_send_kvec+0x8e/0xa0 [sunrpc]
[] xs_sendpages+0x173/0x220 [sunrpc]
[] xs_tcp_send_request+0x5d/0x160 [sunrpc]
[] xprt_transmit+0x83/0x2e0 [sunrpc]
[] call_transmit+0xa8/0x130 [sunrpc]
[] __rpc_execute+0x66/0x1d0 [sunrpc]
[] rpc_async_schedule+0x15/0x20 [sunrpc]
[] process_one_work+0x13e/0x460
[] worker_thread+0x17c/0x3b0
[] kthread+0x96/0xa0
[] kernel_thread_helper+0x4/0x10
新手阅读 Nebula Graph 源码的姿势
入门不错
参考资料也不错
Latency Sneaks Up On You
一个简单的系统
┌────────┐ ┌─────┐ ┌──────┐
│ Client │────▶│Queue│───▶│Server│
└────────┘ └─────┘ └──────┘
定义这个系统的利用率(Utilization)
进队列速率除以完成队列的速率,同理空闲率就是1-
说了一些概念来评估延迟
New Encodings to Improve ClickHouse Efficiency
clickhouse使用zstd和lz4来压缩,压缩的数据内容是不感知的,如果能感知数据类型形态,能有更好的压缩空间,这里,clickhouse引入了几种编码方式
Delta 这种更能呗lz4/zstd压缩
DoubleDelta 如果数据不经常改,这个速度更快
Gorilla 这个是facebook用的编码方案,也是不经常改的value,更好
前三种都是时序数据库使用的压缩手段,时序数据库有这种特点,数据的变化小,有很大的压缩空间
T64 这个是clickhouse独有的
文章后面介绍的是各种数据类型的压缩效果
Faster ClickHouse Imports
各种导入总结,和上面差不多其实
lark,一个python parser
这个我之前关注了一段时间,寻思学习一下,用c++写一遍,这里标记一下TODO
How a Read Query Can Write to Disk: a Postgresql Story
一个搞笑场景,select,居然写了磁盘?
we ran out of our connection’s allotted working memory, and started writing sorted chunks to disk.
简单说,每个connection都有一个内存使用限制 work_mem,超了,没地儿存数据,反而写了磁盘,调整work_mem就行了
