blog review 第八期
08 Jul 2021
|
|
看tag知内容 [toc]
Random number generators for C++ performance tested
Xorshift最快,不过推荐用PCG的https://www.pcg-random.org/
看需求,没有严格要求随机数满足什么特征,那就xorshift
测试代码在这里https://github.com/thompsonsed/RandomNumberGeneration/blob/master/main.cpp
Do Low-level Optimizations Matter?
随机生成一堆数据,跑个sort
dd if=/dev/urandom count=100 bs=4000000 of=1e8ints
#include <sys/mman.h>
#include <fcntl.h>
#include <algorithm>
static const int size = 100'000'000;
int main(int, char**) {
int fd = ::open("1e8ints", O_RDONLY);
int perms = PROT_READ|PROT_WRITE;
int flags = MAP_PRIVATE|MAP_POPULATE|MAP_NORESERVE;
auto* a = (int*) ::mmap(
nullptr, size * sizeof(int), perms, flags, fd, 0);
std::sort(a, a + size);
return a[0] == a[size - 1];
}
基线时间
g++ -O3 -march=native sort_base.cc && time ./a.out
real 0m7.365
user 0m7.257
sys 0m0.108s
作者自己写了几个版本的radixsort,不行,被锤
Migrating Facebook to MySQL 8.0
facebook也迁移到8.0了,原本是5.6+myrocks的,看看他们升级做的准备工作
把内部使用的5.6分支代码全patch到8.0上,具体patch分类
- Drop: Features that were no longer used, or had equivalent functionality in 8.0, did not need to be ported.
- Build/Client: Non-server features that supported our build environment and modified MySQL tools like mysqlbinlog, or added functionality like the async client API, were ported.
- Non-MyRocks Server: Features in the mysqld server that were not related to our MyRocks storage engine were ported.
- MyRocks Server: Features that supported the MyRocks storage engine were ported.
为了myrocks加了很多特性
之前也介绍过他们怎么迁移到myrocks上的, 原文
这次迁移和上次是差不多的
- For each replica set, create and add 8.0 secondaries via a logical copy using mysqldump. These secondaries do not serve any application read traffic.
- Enable read traffic on the 8.0 secondaries.
- Allow the 8.0 instance to be promoted to primary.
- Disable the 5.6 instances for read traffic.
- Remove all the 5.6 instances.
使用Row-based replication
基于行的复制,以前都是基于语句的复制/binlog流水,这个收益在后面会体现
自动验证
facebook内部很多验证工具,解析日志之类的,需要适配mysql 8.0
遇到的一些问题
- 工具解析日志不可用,遇到一些解析错误之列的处理/适配
- The 8.0’s default utf8mb4 collation settings resulted in collation mismatches between our 5.6 and 8.0 instances. 8.0 tables may use the new utf8mb4_0900 collations even for create statements generated by 5.6’s show create table because the 5.6 schemas using utf8mb4_general_ci do not explicitly specify collation. These table differences often caused problems with replication and schema verification tools.
- 一些复制的错误码变了
- The 8.0 version’s data dictionary obsoleted table .frm files, but some of our automation used them to detect table schema modifications.
- We had to update our automation to support the dynamic privs introduced in 8.0.
应用验证
应该无感知切,但是会遇到mysql 8.0死锁,临时换回5.6
- 8.0加了很多关键字,有语句歧义,解决很简单,用 `` 套上就行
- A few REGEXP incompatibilities were also found between 5.6 and 8.0. 还是行为不一致
- 死锁问题 A few applications hit repeatable-read transaction deadlocks involving
insert … on duplicate keyqueries on InnoDB. 5.6 had a bug which was corrected in 8.0, but the fix increased the likelihood of transaction deadlocks. After analyzing our queries, we were able to resolve them by lowering the isolation level. This option was available to us since we had made the switch torow-based replication. - json不兼容Our custom 5.6 Document Store and JSON functions were not compatible with 8.0’s. Applications using Document Store needed to convert the document type to text for the migration. For the JSON functions, we added 5.6-compatible versions to the 8.0 server so that applications could migrate to the 8.0 API at a later time.
也发现了几个锁竞争问题,当前没有解决方案
- We found new mutex contention hotspots around the ACL cache. When a large number of connections were opened simultaneously, they could all block on checking ACLs.
- Similar contention was found with binlog index access when many binlog files are present and high binlog write rates rotate files frequently.
- Several queries involving temp tables were broken. The queries would return unexpected errors or take so long to run that they would time out.
Why you should learn just a little Awk
一个awk教程
logs.txt
07.46.199.184 [28/Sep/2010:04:08:20] "GET /robots.txt HTTP/1.1" 200 0 "msnbot"
123.125.71.19 [28/Sep/2010:04:20:11] "GET / HTTP/1.1" 304 - "Baiduspider"
echo 'this is a test' | awk '{print $3}' // prints 'a'
awk '{print $1}' logs.txt
07.46.199.184
123.125.71.19
echo 'this is a test' | awk '{print $NF}' // prints "test"
awk '{print $1, $(NF-2) }' logs.txt
07.46.199.184 200
123.125.71.19 304
awk '{print NR ") " $1 " -> " $(NF-2)}' logs.txt
1) 07.46.199.184 -> 200
2) 123.125.71.19 -> 304
awk '{print $2}' logs.txt
[28/Sep/2010:04:08:20]
[28/Sep/2010:04:20:11]
awk '{print $2}' logs.txt | awk 'BEGIN{FS=":"}{print $1}'
[28/Sep/2010
[28/Sep/2010
awk '{print $2}' logs.txt | awk 'BEGIN{FS=":"}{print $1}' | sed 's/\[//'
28/Sep/2010
28/Sep/2010
awk '{if ($(NF-2) == "200") {print $0}}' logs.txt
07.46.199.184 [28/Sep/2010:04:08:20] "GET /robots.txt HTTP/1.1" 200 0 "msnbot"
awk '{a+=$(NF-2); print "Total so far:", a}' logs.txt
Total so far: 200
Total so far: 504
awk '{a+=$(NF-2)}END{print "Total:", a}' logs.txt
Total: 504
What is the sorting algorithm behind ORDER BY query in MySQL?
- External merge sort (quick sort + merge sort) if data doesn’t fits into the memory
- Quick sort, if data fits into the memory and we want all of it
- Heap sort, if data fits into the memory but we are using LIMIT to fetch only some results
- Index lookup (not exactly a sorting algorithm, just a pre-calculated binary tree)
Adding peephole optimization to GCC
通过peephole来介绍gcc 的整体情况
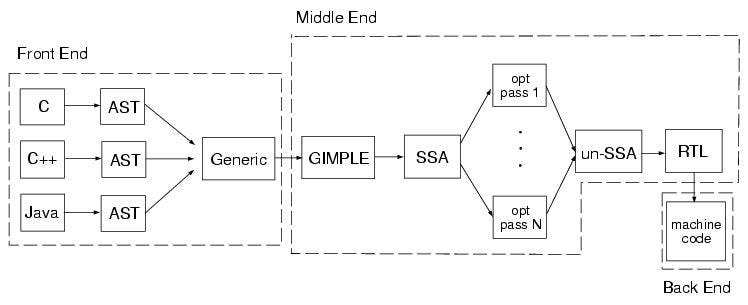
就记住了这个图了
Command Line Tricks For Data Scientists
主要是介绍各种one-liner
#格式转换
iconv -f ISO-8859-1 -t UTF-8 < input.txt > output.txt
#替换字符
tr "\t" "," < tab_delimited.txt > comma_delimited.csv
#分裂文件
split -l 500 filename.csv new_filename_
#排序
# Sorting a CSV file by the second column alphabetically Numerically Reverse order
sort -t"," -k2nr,2 filename.csv
# 去掉某行
cut -d, -f 1,3 filename.csv
# 简单join
paste -d ',' names.txt jobs.txt > person_data.txt
# 效果
# names.txt
adam
john
zach
# jobs.txt
lawyer
youtuber
developer
# Output
adam,lawyer
john,youtuber
zach,developer
#复杂join
# Join the first file (-1) by the second column
# and the second file (-2) by the first
join -t"," -1 2 -2 1 first_file.txt second_file.txt
# sed 各种行操作,比如删除
sed -i '' '/jack/d' data.txt
# awk打印
awk -F, '/word/ { print $3 "\t" $4 }' filename.csv
C++: Thoughts on Dealing with Signed/Unsigned Mismatch
一个坑
static_assert(-1<1U);//fails
static_assert( short(-1) < (unsigned short)(1) );//stands (if sizeof(short)<sizeof(int))!
static_assert( int64_t(-1) < 1U );//stands! - because converted to larger which is signed
static_assert( -1 < uint64_t(1) );//fails! - because converted to larger which is unsigned
How to Analyze Billions of Records per Second on a Single Desktop PC
locustDB的软文,根据Scuba论文来重新实现的,对表clickhouse/scuba
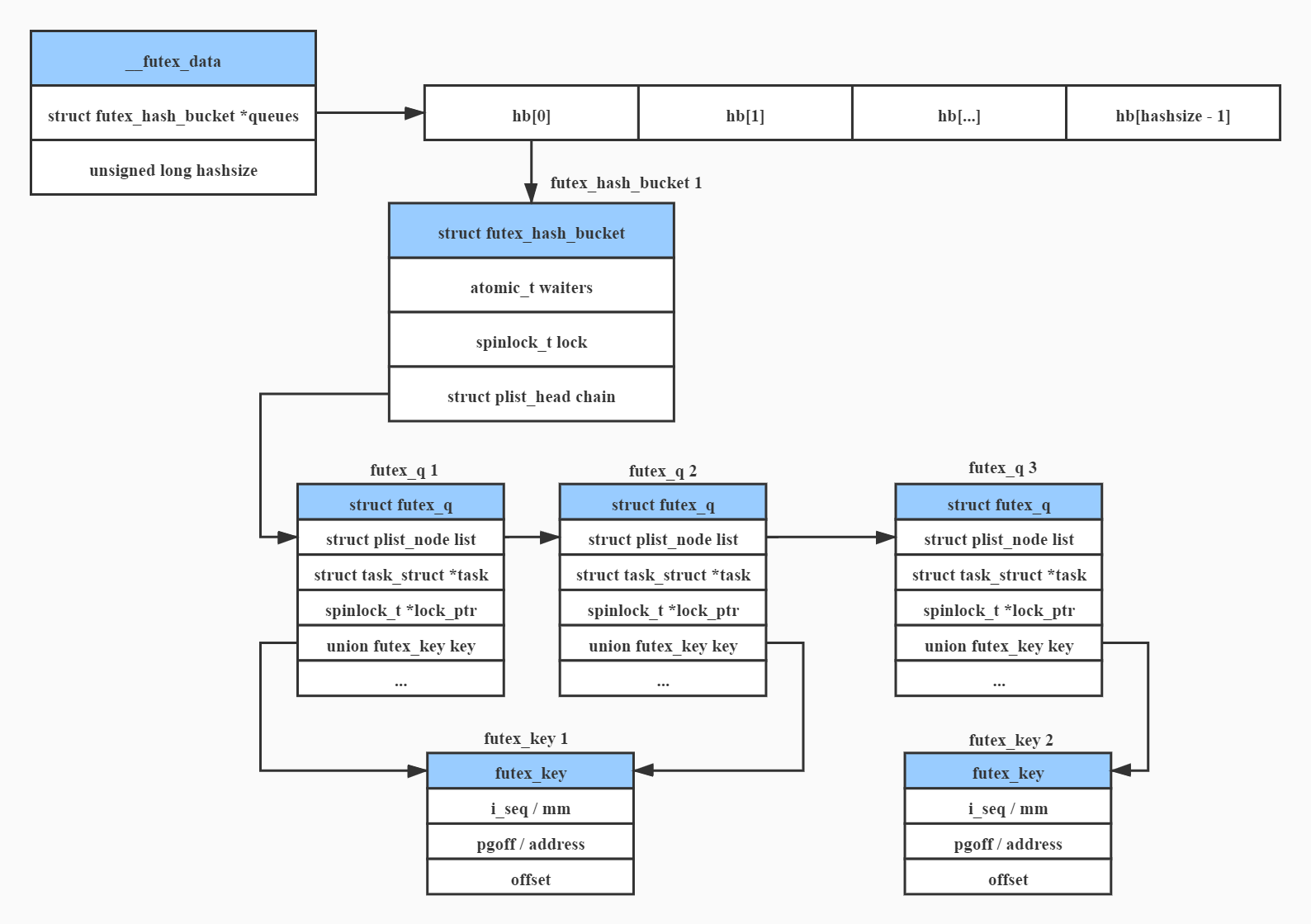
linux–futex原理分析
Basics of Futexes
基本api
//uaddr指向一个地址,val代表这个地址期待的值,当*uaddr==val时,才会进行wait
int futex_wait(int *uaddr, int val);
//唤醒n个在uaddr指向的锁变量上挂起等待的进程
int futex_wake(int *uaddr, int n);
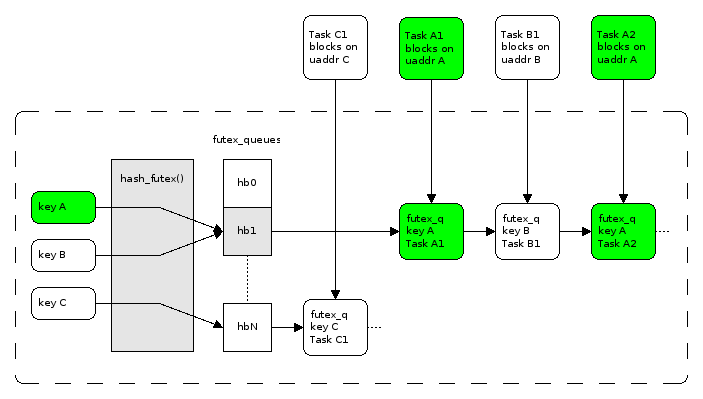
具体的数据结构关系
mutex就是用futex实现的。文章中也简单列里一个mutex实现
class Mutex {
public:
Mutex() : atom_(0) {}
void lock() {
int c = cmpxchg(&atom_, 0, 1);
// If the lock was previously unlocked, there's nothing else for us to do.
// Otherwise, we'll probably have to wait.
if (c != 0) {
do {
// If the mutex is locked, we signal that we're waiting by setting the
// atom to 2. A shortcut checks is it's 2 already and avoids the atomic
// operation in this case.
if (c == 2 || cmpxchg(&atom_, 1, 2) != 0) {
// Here we have to actually sleep, because the mutex is actually
// locked. Note that it's not necessary to loop around this syscall;
// a spurious wakeup will do no harm since we only exit the do...while
// loop when atom_ is indeed 0.
syscall(SYS_futex, (int*)&atom_, FUTEX_WAIT, 2, 0, 0, 0);
}
// We're here when either:
// (a) the mutex was in fact unlocked (by an intervening thread).
// (b) we slept waiting for the atom and were awoken.
//
// So we try to lock the atom again. We set teh state to 2 because we
// can't be certain there's no other thread at this exact point. So we
// prefer to err on the safe side.
} while ((c = cmpxchg(&atom_, 0, 2)) != 0);
}
}
// An atomic_compare_exchange wrapper with semantics expected by the paper's
// mutex - return the old value stored in the atom.
int cmpxchg(std::atomic<int>* atom, int expected, int desired) {
int* ep = &expected;
std::atomic_compare_exchange_strong(atom, ep, desired);
return *ep;
}
void unlock() {
if (atom_.fetch_sub(1) != 1) {
atom_.store(0);
syscall(SYS_futex, (int*)&atom_, FUTEX_WAKE, 1, 0, 0, 0);
}
}
private:
// 0 means unlocked
// 1 means locked, no waiters
// 2 means locked, there are waiters in lock()
std::atomic<int> atom_;
};
glibc中的代码可以去看 nptl/pthread_mutex_lock.c
Open-sourcing F14 for faster, more memory-efficient hash tables
代码的设计文档在这里
放在folly的总结里比较好一些
待看
https://github.com/cheshirekow/openbookfs
