ramcloud资料整理
ramcloud是一个典型的KV表格结构
针对这个表格,引入了很多设计,也有很多论文。这里整理列出这个文章
[toc]
基本架构
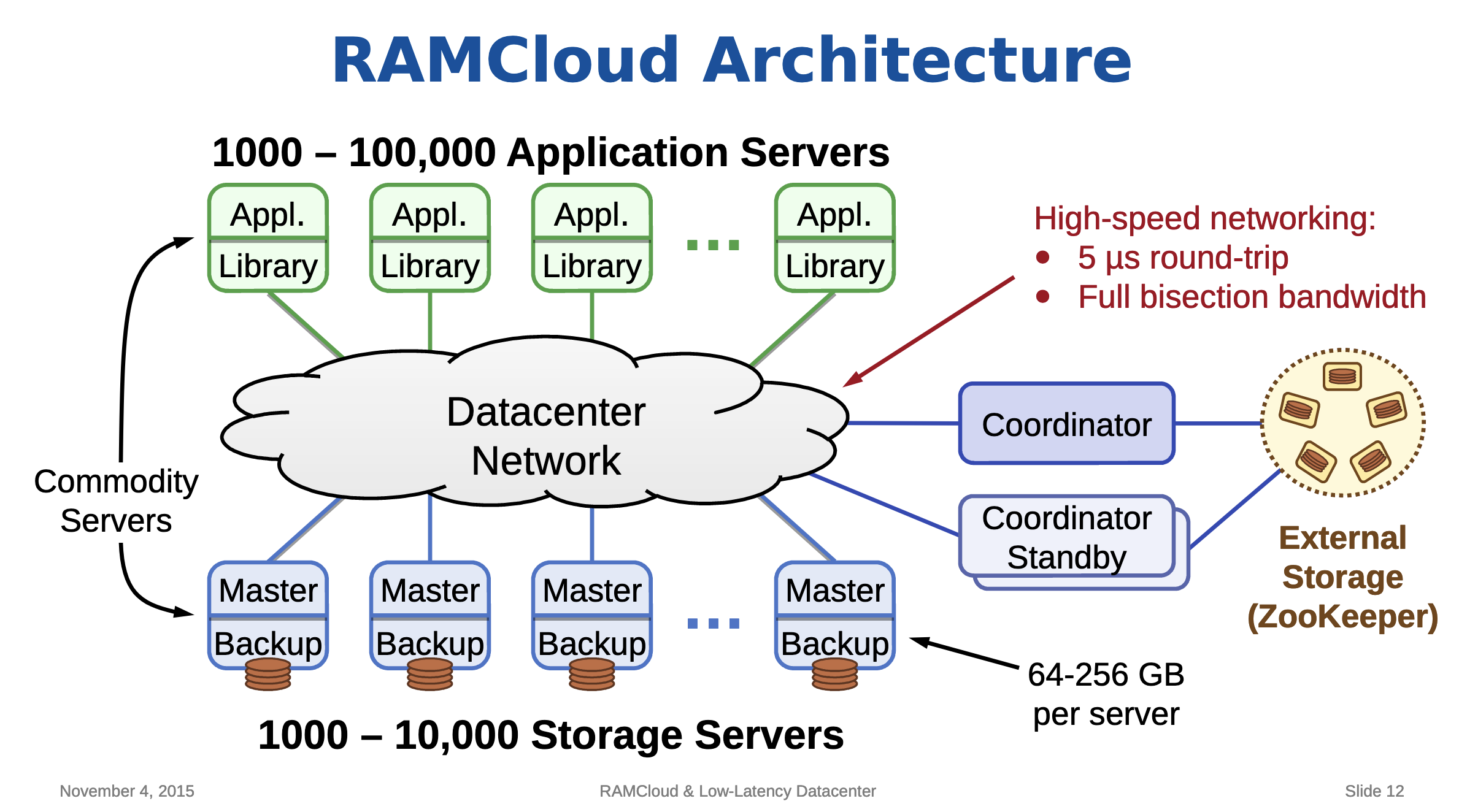
如图可见的四种服务类型
enum ServiceType {
MASTER_SERVICE,
BACKUP_SERVICE,
COORDINATOR_SERVICE,
ADMIN_SERVICE,
INVALID_SERVICE, // One higher than the max.
};
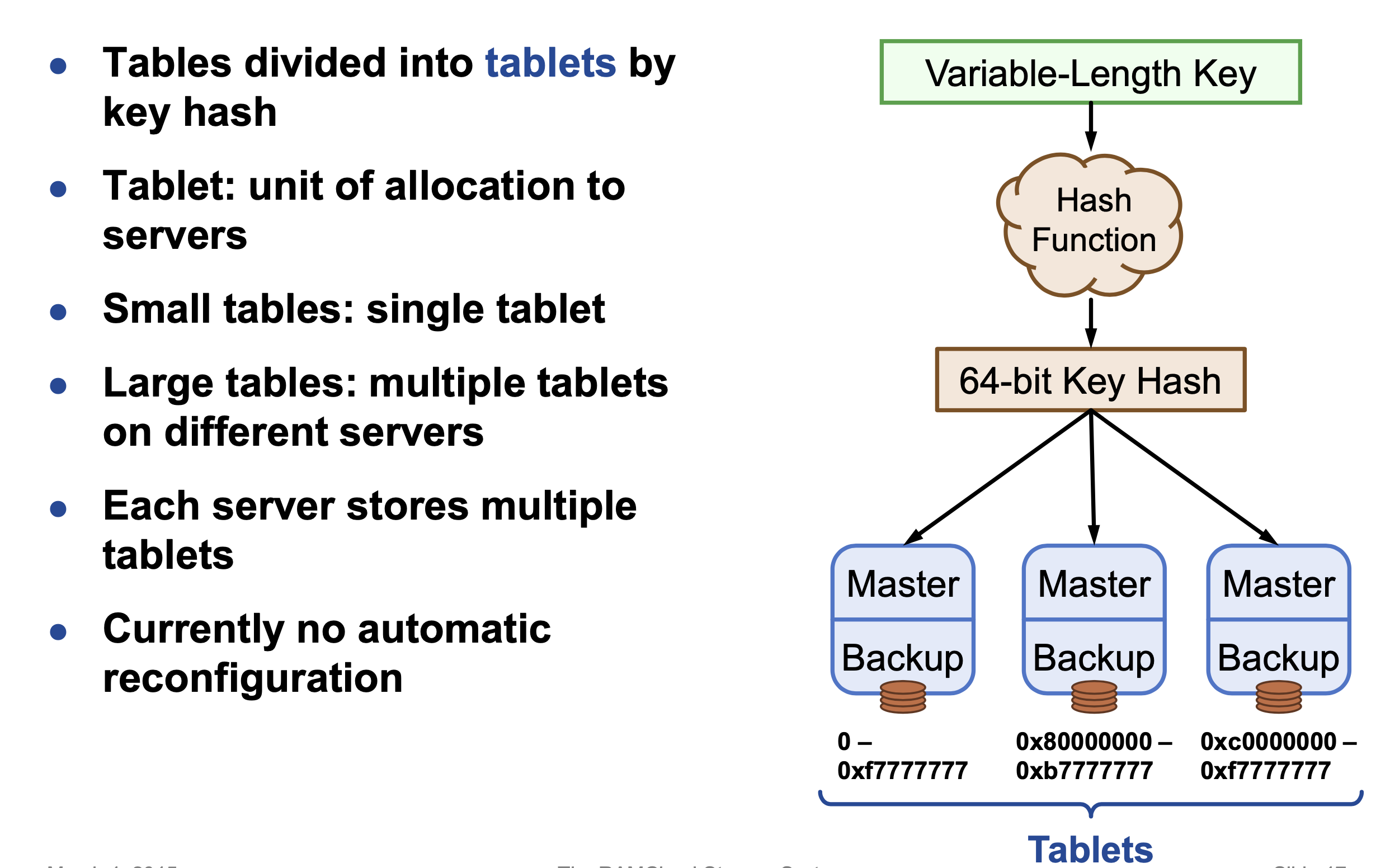
水瓶扩展?hash分片
基本的api
createTable(name) → id
getTableId(name) → id
dropTable(name)
read(tableId, key) → value, version
write(tableId, key, value) → version
delete(tableId, key)
multiRead([tableId, key]*) → [value, version]*
multiWrite([tableId, key, value]*) → [version]*
multiDelete([tableId, key]*)
enumerateTable(tableId) → [key, value, version]*
increment(tableId, key, amount) → value, version
conditionalWrite(tableId, key, value, version) → version
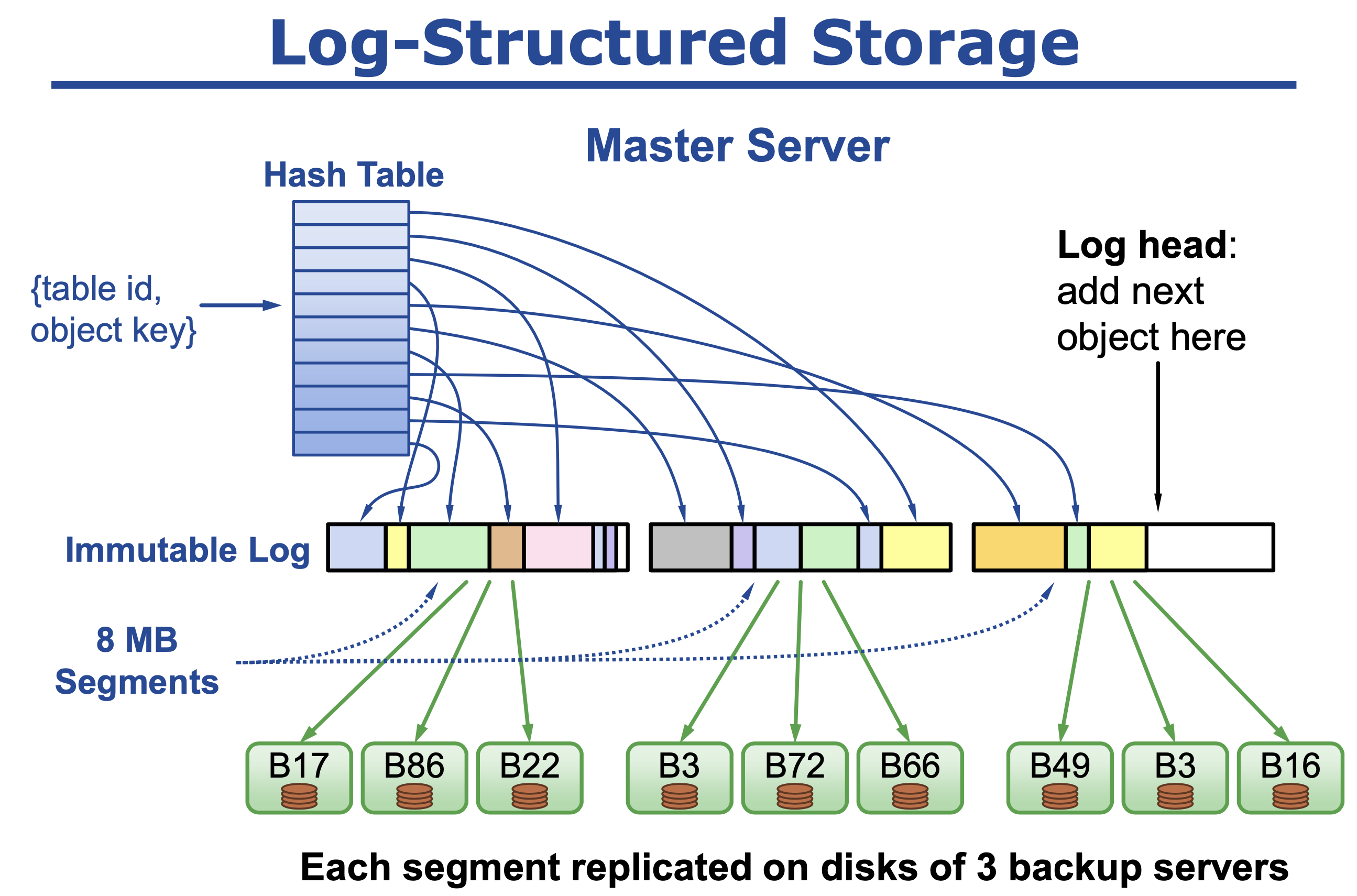
日志设计
日志也是LSM
- 内存分成8MB大小的段(Segment),分配的对象在上面进行
- 使用一个hashtable来记录申请的内存对象实际的内存地址
- 选择内存空闲程度高的段进行拷贝整理,整理后释放旧的段
- 整理时通过引用计数来判断对象是否存活
- 内存整理是并行的
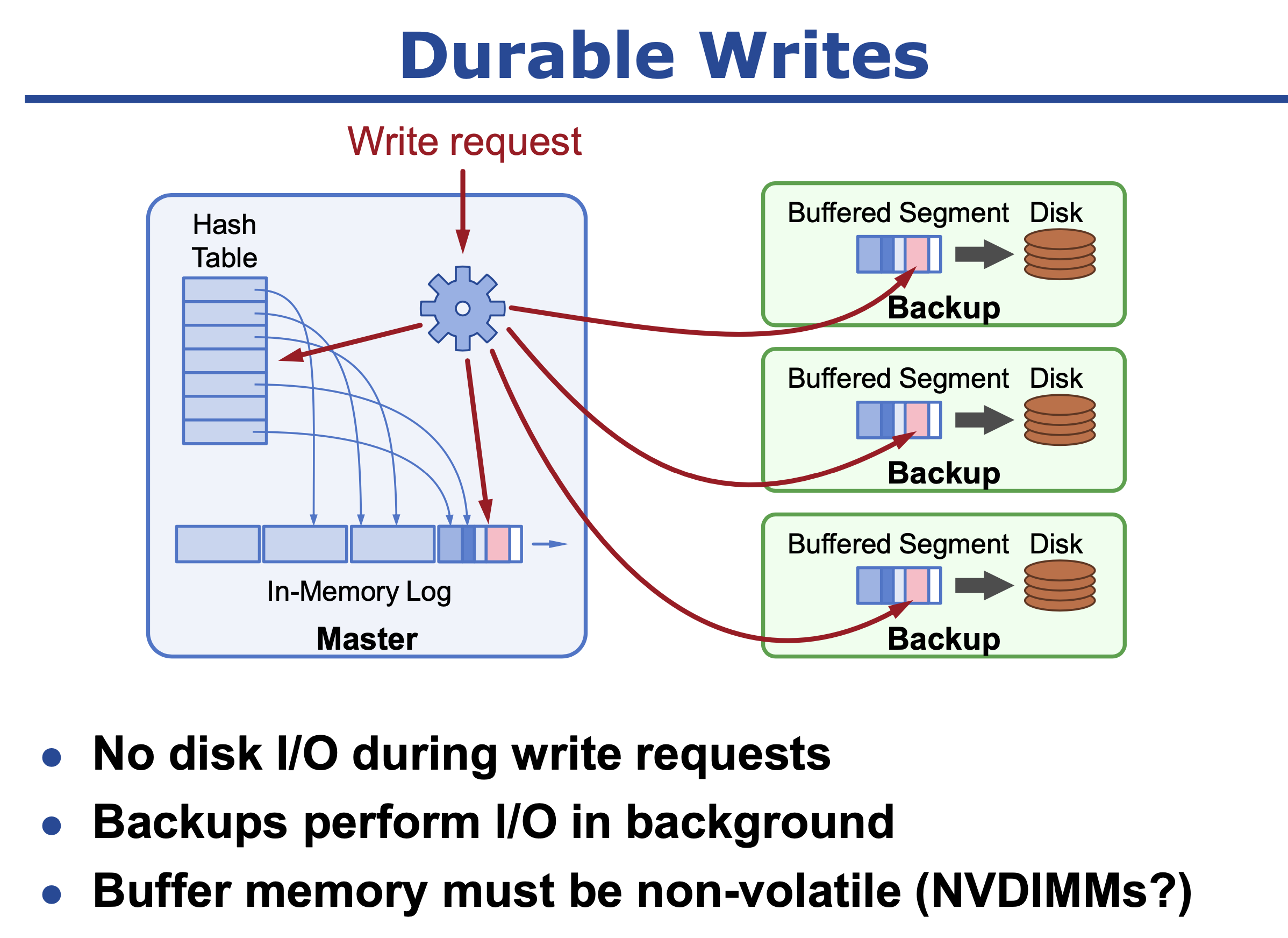
持久化保证
写入日志三副本分段保存到backups service上 append log
Tombstone 的概念也和rocksdb一样的
备份恢复
并发读日志,日志是按hash分的,无重叠
复制
大名鼎鼎的raft就出自这里
其他复制设计
Consistent Unordered Replication Protocol (CURP),这个方案比看起来要复杂的多
把binlog日志拆出来,保证日志的持久性,节省master机器的rtt
复制协议设计要点
-
顺序一致:若副本两个操作a, b顺序为(a,b),则没有任何客户端在看到b的时候,看不到a
-
持久化:一旦提交,进程崩溃后数据依旧不丢失
一般而言,传统复制协议延迟相对高一些,或有一些缺点:
- 主从复制:客户端→主节点(1 RTT),主节点→ 全部从节点(1 RTT)
类Paxos协议:客户端→主节点(1 RTT),主节点→超过半数从节点(1 RTT)
Faxos Paxos和Generalized Paxos:1.5 RTTs
NOPaxos和Speculative Paxos:接近1 RTT,但需要额外硬件支持,路由路径变长使得延迟会高一些
CURP的关键思路在于:对于可交换的操作,持久化顺序可以和操作顺序不一致,从而将延迟将为1 RTT
- 客户端往一个临时缓冲Witness写入请求,它不含顺序信息,客户端可并行向其写入
- 写入Witness同时,向主节点写入,然后立刻返回,只需要1 RTT
- 当主节点挂掉,Witness可用于重放和恢复
注意,操作可交换,不可交换直接拒绝。,如果一个客户端更新x=1一个客户端更新x=2, witness就要拒绝两个客户端
收到拒绝的客户端主动发起一次sync把这个不可交换的操作落地
两套措施。挺不自然的方案
- Crash Recovery 直接从backup中选+从witness中重放,这个重放可以乱序
重放数据时,可能造成重复执行的问题,违背线性一致性(Witness请求已经在主节点挂掉前被同步了,但还没被清除),其解决方法是使用RIFL:
- 它给所有的RPC赋上一个唯一ID
- 服务端存储该ID和请求的结果(与原子方式和更新的对象持久保存),来检测重复的请求
- 涉及到的rifl没有仔细研究 http://web.stanford.edu/~ouster/cgi-bin/papers/rifl.pdf
- witness会有各种同步日志协议同样的gc问题
- witness的可用性,witness本身要搞个高可用集群
当Witness挂掉:
- 配置管理器会给主节点移除挂掉的Witness,并赋上新的Witness,并通知主节点
主节点执行一次同步操作,保证f
- 副本容错,然后响应给配置管理器
- 客户端就可以使用新的Witness(从配置管理器获取)
为了防止客户端使用旧Witness进行操作,CURP给Witness表维护一个递增版本号
WitnessListVersion:
- 当Witness变更,主节点上该版本号都会递增
- 客户端请求会包含该版本号,主节点可检测版本号冲突并返回错误
- 当主节点返回Witness版本号错误,客户端会从配置管理器获取新版本的Witness列表
内存设计 Log-Structured Memory
为什么不用定制malloc -> 内存碎片
为什么不用GC -> STW不可忍受
Log-Structured Memory实际上也是一种GC模式不过基本无延迟,目标是不影响访问
这个设计scylladb也有类似的设计
https://zhuanlan.zhihu.com/p/25937990
实现在这里 https://github.com/scylladb/scylladb/blob/master/utils/logalloc.cc
compact
有Log类维护所有的append log,其中包括LogCleaner,LogCleaner后台起线程来做扫描,有balancer
balancer有两种类型,一种是按照删除key的比例TombstoneRatioBalancer,一种是固定比率FixedBalancer
后台线程做的都是cleanerThreadEntry -> doWork唯一区别 tid不同
doWork根据balancer->requestTask来决定做什么样的compact
这里也叫两阶段清扫
Two-level cleaning
最大的改动是将Segment改为变长的模式,将所有内存分成小段(Seglet),每个Seglet只有64KB大小,每个Segment可以由多个Seglet组成,可以不连续。其默认大小仍为8MB。将内存整理分为两部分:
- 压缩(Compaction):只涉及一个内存Segment变成更小的Segment,占用了更少的Seglet数目。
- 联合整理(Combined cleaning):与前文所述相同,同时会将磁盘上的backup进行整理。
前者的消耗比较小,后者的消耗比较大。策略上尽量多做前者少做后者,同时推迟后者的执行可以提高整体效率,因为整理时间越晚,越少的对象会存活,开销也就越小。
LogCleaner::Balancer::requestTask(CleanerThreadState* thread)
{
if (isDiskCleaningNeeded(thread))
return CLEAN_DISK;
if (!cleaner->disableInMemoryCleaning && isMemoryLow(thread))
return COMPACT_MEMORY;
return SLEEP;
}
-
isDiskCleaningNeeded-
线程id不是1,false,一个线程就足够了
-
cleaner->segmentManager.getSegmentUtilization() >= MIN_DISK_UTILIZATIONtrue -
isMemoryLow(thread)false 不到不得已不去清理,disableInMemoryCleaning同理 -
compactionFailures > compactionFailuresHandled有compact失败,那更得去compact -
TombstoneRatioBalancer最终逻辑-
const int U = cleaner->cleanableSegments.getUndeadTombstoneUtilization(); const int L = cleaner->cleanableSegments.getLiveObjectUtilization(); if (U >= static_cast<int>(ratio * (100 - L))) return true;
-
-
FixedBalancer最终逻辑 只要是磁盘访问比总数访问小于设定,那就compact把数据压一下,肯定是有很多被删的key了-
if (100 * diskTicks / totalTicks > cleaningPercentage) return false;
-
-
-
isMemoryLow
-
// We need to clean if memory is low and there's space that could be // reclaimed. It's not worth cleaning if almost everything is alive. int baseThreshold = std::max(90, (100 + L) / 2); if (T < baseThreshold) return false;
-
-
doDiskCleaning
-
getSegmentsToClean
- chooseSegmentFunction 两种算法 边界条件
objectCount > MAX_LIVE_OBJECTS_WRITTEN_PER_PASS- costBenefit 有个公式,根据各种代价来计算,可以是文件存活/文件创建时间/访问时间等, 排好序然后挑前面的,然后想家,直到满足条件为止
- gready,每次都找utilisation最大的,满足条件就放到结果里,然后判定是不是满足边界条件,不满足再搜一次,找倒数第二小的,加起来,再算
- 很难说这两种哪个更好,反正数据集比较小
- chooseSegmentFunction 两种算法 边界条件
-
getSortedEntries(segmentsToClean, outEntries, &localMetrics); 拿到活的数据
-
relocateLiveEntries(entries, survivors, &localMetrics);重新分配数据
- relocateEntry
- LogEntryRelocator relocator(survivor, buffer.size());
- ObjectManager entryHandlers.relocate(type, buffer, reference, relocator); log的构造是吧logentryhandler填的this
log(context, config, this, &segmentManager, &replicaManager) - relocateObject, 重新放回hashtable(服了,和fasterkv差不多)不过没有整体address的概念,所以可以大胆的删文件
- relocateEntry
-
segmentManager.cleaningComplete(segmentsToClean, survivors); 更新结果
// Update the previous version's ReplicatedSegment to use the new, compacted // segment in the event of a backup failure. assert(newSegment->replicatedSegment == NULL); newSegment->replicatedSegment = oldSegment->replicatedSegment; oldSegment->replicatedSegment = NULL; newSegment->replicatedSegment->swapSegment(newSegment); injectSideSegment(newSegment, NEWLY_CLEANABLE, guard); freeSegment(oldSegment, false, guard);
-
-
doMemoryCleaning 这个比较复杂
-
看代码实现,就是对segment循环两次
// Take two passes, writing out the tombstones first. This makes the // dead tombstone scanner in CleanableSegmentManager more efficient // since it will only need to scan the front of the segment. for (int tombstonePass = 1; tombstonePass >= 0 && !empty; tombstonePass--) { for (SegmentIterator it(*segment); !it.isDone(); it.next()) { LogEntryType type = it.getType(); if (tombstonePass && type != LOG_ENTRY_TYPE_OBJTOMB) continue; if (!tombstonePass && type == LOG_ENTRY_TYPE_OBJTOMB) continue;第一阶段就是把tombstones 已经删除的key跳出来,第二遍把其余的跳出来,relocate走不同的流程
这和一个循环做两件事有啥区别么?This makes the dead tombstone scanner in CleanableSegmentManager more efficient since it will only need to scan the front of the segment.
-
getSegmentToCompact
-
LogSegment* survivor = segmentManager.allocSideSegment(FOR_CLEANING MUST_NOT_FAIL,segment); -
循环 走relocateObject/relocateTombstone
- relocateObject 查引用,更新hashtable append,否则直接删掉
- relocateTombstone类似上面的算法,如果有引用,就更新hashtable append,否则就更新tablestat删掉
- TableStats::decrement
-
CleanableSegmentManager update,在调用get的时候就会更新,选出需要compact的对象
代码走读
开发者架构入门 https://ramcloud.atlassian.net/wiki/spaces/RAM/pages/6848729/For+New+Developers+-+Understanding+Reads+in+RAMCloud
// StatsLogger logger(context.dispatch, 1.0);
MemoryMonitor monitor(context.dispatch, 1.0, 100);
Server server(&context, &config);
server.run(); // Never returns except for exceptions.
参考资料
-
图来自https://ramcloud.atlassian.net/wiki/spaces/RAM/pages/6848659/RAMCloud+Presentations?preview=/6848659/42369038/RAMCloud%20LL%20Datacenter%20(Nov%202015).pptx
-
ramcloud的论文非常多https://ramcloud.atlassian.net/wiki/spaces/RAM/pages/6848671/RAMCloud+Papers 这里尽量总结
- CURP总结
- https://keys961.github.io/2020/05/18/论文阅读-CURP/
- https://zhuanlan.zhihu.com/p/59991142
- https://zhuanlan.zhihu.com/p/89598831
- 内存设计和两阶段清理 http://www.gemini-store.com/2020/04/02/log-structured-memory-paper/
