Map Reduce整理
03 May 2021
|
|
参考资料
https://lvsizhe.github.io/course/2020/03/mapreduce.html
https://zhuanlan.zhihu.com/p/34849261
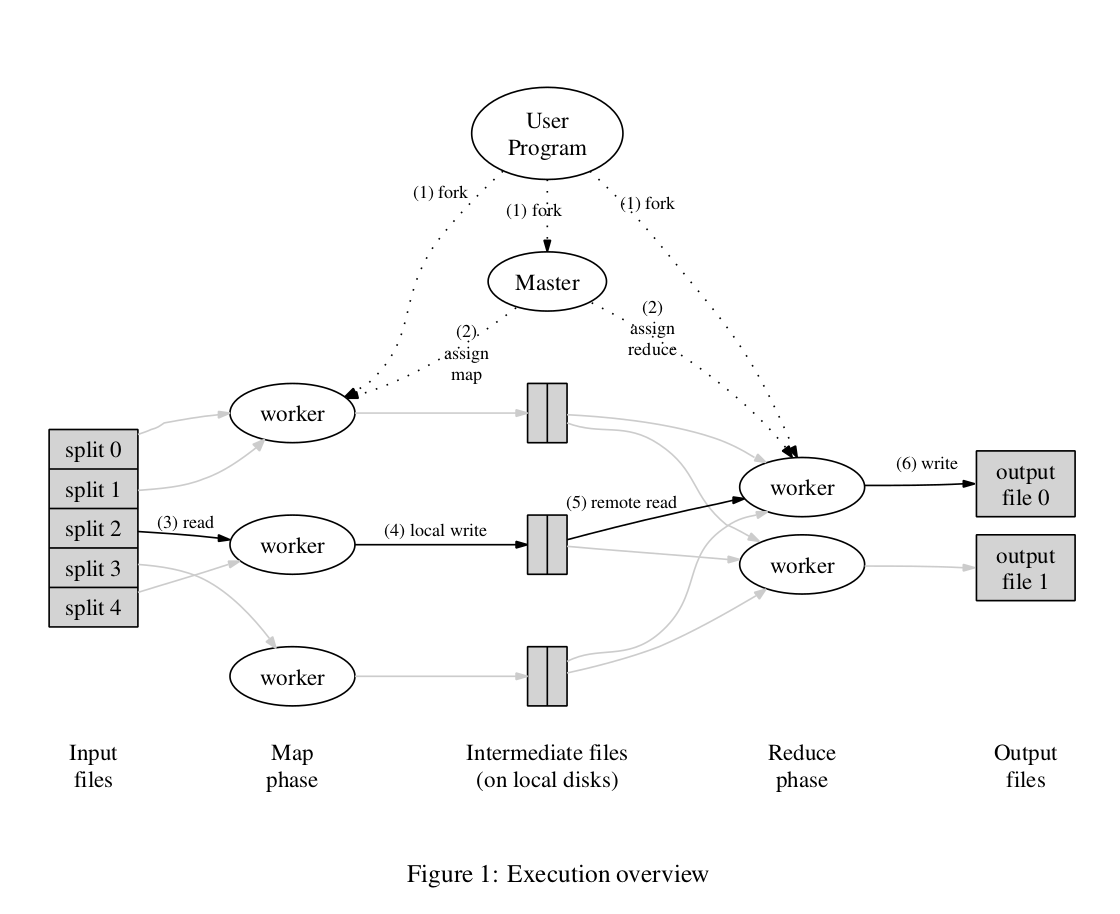
抄来的论文描述的基本逻辑
- 作为输入的文件会被分为
个 Split,每个 Split 的大小通常在 16~64 MB 之间(这个值是和业务相关的,这么小不合理)
- 如此,整个 MapReduce 计算包含
个 Reduce 任务。Master 结点会从空闲的 Worker 结点中进行选取并为其分配 Map 任务和 Reduce 任务
- 收到 Map 任务的 Worker 们(又称 Mapper)开始读入自己对应的 Split,将读入的内容解析为输入键值对并调用由用户定义的 Map 函数。由 Map 函数产生的中间结果键值对会被暂时存放在缓冲内存区中
- 在 Map 阶段进行的同时,Mapper 们周期性地将放置在缓冲区中的中间结果存入到自己的本地磁盘中,同时根据用户指定的 Partition 函数(默认为
)将产生的中间结果分为
- Mapper 上报的中间结果存放位置会被 Master 转发给 Reducer。当 Reducer 接收到这些信息后便会通过 RPC 读取存储在 Mapper 本地磁盘上属于对应 Partition 的中间结果。在读取完毕后,Reducer 会对读取到的数据进行排序以令拥有相同键的键值对能够连续分布
- 之后,Reducer 会为每个键收集与其关联的值的集合,并以之调用用户定义的 Reduce 函数。Reduce 函数的结果会被放入到对应的 Reduce Partition 结果文件
优化考虑 减少磁盘或者网络的IO
- 数据的局部性: MR框架会通过查询分布式文件系统(DFS),尽可能的将task调度到数据所的物理机、或者接近的网段上;这个能够有效减少需要传输的数据量。
- 任务的粒度: 一般而言,需要让M和R远远大于worker机器的数量,即让任务粒度足够小。这样一来可以实现更好的负载均衡。性能强的机器处理更多的task、性能差的处理得少一些;二来task重做的时候,发生重做的部分会更少些。经验上,最好将任务分割成处理64MB/128MB粒度的task为佳4
- Backup-task: 在现实中,可能出现一些任务执行不正常(比如调度到故障机器)上,执行极慢导致整个job都在等待这几个任务结束。因此解决的手段是对于一些任务(一般选择最后调度上去的那批、或者执行时间超出大多数其他任务平均时长许多的),重复的提交一个,然后master先收取第一个执行完成的结果。这能够有效的消除长尾问题。
- 分区hash可定制: MR框架提供了可定制的分区计算方法,使得业务可以根据需要,引入自身场景以方便编写任务。比如在建库的时候,可以以hostname来作为hash的key,让同hostname的网页都落入同一个reduce进行处理。
- 顺序保证: 在框架中,确保了每个分区内部,都是按照key的顺序进行处理的,这样就给全局排序这样的任务提供了实现的基础。
- Combiner: 在许多场景下(比如WordCount),可以在map端作一轮的合并,然后让reduce在map已经合并过的基础上进一步合并结果。因此,引入了Map端的Combiner的概念,以显著减少map-reduce之间需要走网络传输的数据量。
- 信息披露: 为方便用户,MR框架可以查看所有task的执行状态,并提供了Counter功能进行一些用户层面的统计计数。这样用户就能够从这些基础信息中,了解自己任务的执行情况,在外围做一些诸如监控、管理类的行为。
可用性保证
- Worker挂掉/慢 直接杀掉重做
- Reducer丢失数据 FS系统保证
说了半天都是别人的用法,现在流行的做法是用spark了,而且上面没有考虑的点很多。这里罗列一下
- 任务的粒度 引申出来的问题
- map分片多大合适?要充分利用机器(对象存储)的带宽,论文中哪个MB级别的粒度,太搞笑了。
- 任务的优先级?谁先谁后,机器的上传下载带宽有限,执行快慢也不同
- 任务的取消?任务执行的时间长度不同,但一批任务作为一个整体,有一个任务失败,整体就必然失败,所以取消要有。而且如果任务之间有传递链接关系,那取消任务能节省非常多的时间
- 任务的排队?作为一个系统,影响的环节非常的多。而这个系统又是多租户使用,比如一个导入系统,处理完数据要导入到不同的机器中,但机器的带宽有限,这又引入了排队的问题
- 资源问题
- 磁盘空间不够用,磁盘资源利用率上不去 –> 对象存储来存中间数据
- map实际上是一个分片的逻辑,map生成中间产物,那么,源头能不能生成文件的时候就按照分片来分好?省掉map
- map能不能流式写入?(如果一千个分片,你资源必然不够用,流式写入代价不可接受)
- 状态。上面的或者说spark,都是无状态。无状态当然很简单。引入状态,痛苦的东西就来了。
- 比如增量的map reduce,如何维护管理全量/增量数据?
- 引入对象存储又会引入新的问题。直接用分布式文件系统?这里的抉择可能影响整个map reduce系统的性能
- 增量的场景,可能遇到基线数据巨大而增量特别小且任务很多的情况,怎么解决?(业务用法不对!业务别这么用!业务要是这么听劝就好了)
- 状态的引入,MR期间发生了状态的变更,数据上线存在问题。旧的元数据和新的元数据要做好映射逻辑。不然对不上。这里不能细想,细想一堆问题
- 调度器重启,如何保证任务没有重复派发?要知道任务重复派发可能引起数据覆盖的问题,如果MR系统无法感知就有可能传播到集群才发现,集群要有可靠的回滚能力
- 分成两个阶段,任务数据的元数据,锁成一个事务来处理?
- 调度器重启,如何保证任务没有重复派发?要知道任务重复派发可能引起数据覆盖的问题,如果MR系统无法感知就有可能传播到集群才发现,集群要有可靠的回滚能力
- 比如增量的map reduce,如何维护管理全量/增量数据?
- 调度器以及元数据管理,维护,可用性保证。
- 调度器得多节点吧 ,能主备切换吧
- 调度器本身的元数据,管理每一次调度任务 ,需要很多很多指标信息,来判定任务质量
- 调度器的元数据得主备吧
- 调度器的任务数据本身 ,是否需要保证唯一?可不可能会发生重复调度的问题?如果发生了是否会有影响 ?
- 监控
- 长尾问题,任务执行非常久,上面说的backup task确实能解决,比重试能强点? 状态,真是个难题
