yogabytedb调研
引自 https://ericfu.me/yugabyte-db-introduction/
系统架构
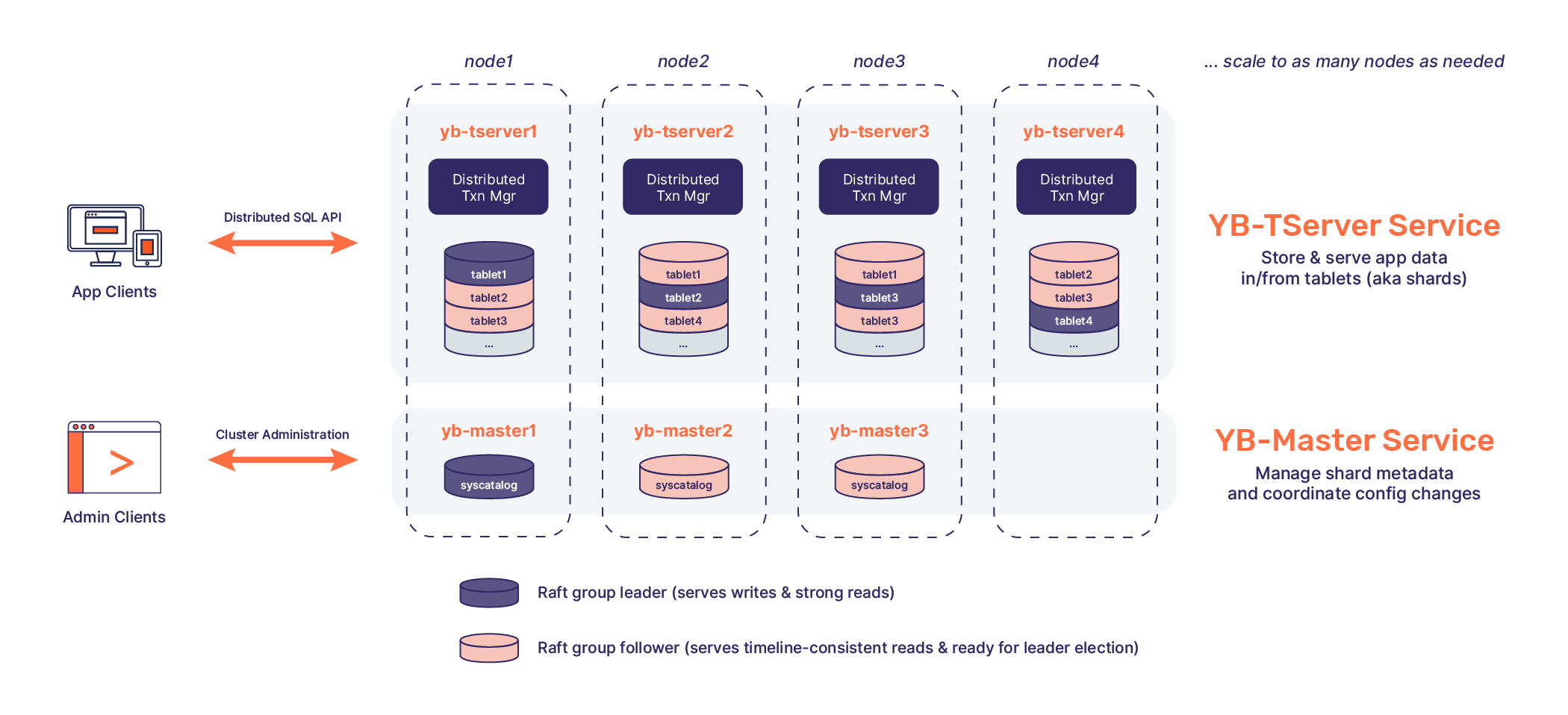
逻辑上,Yugabyte 采用两层架构:查询层和存储层。不过这个架构仅仅是逻辑上的,部署结构中,这两层都位于 TServer 进程中。这一点和 TiDB 不同。
Yugabyte 的查询层支持同时 SQL 和 CQL 两种 API,其中 CQL 是兼容 Cassandra 的一种方言语法,对应于文档数据库的存储模型;而 SQL API 是直接基于 PostgresQL 魔改的,能比较好地兼容 PG 语法,据官方说这样可以更方便地跟随 PG 新特性,有没有官方说的这么美好我们就不得而知了。
Yugabyte 的存储层才是重头戏。其中 TServer 负责存储 tablet,每个 tablet 对应一个 Raft Group,分布在三个不同的节点上,以此保证高可用性。Master 负责元数据管理,除了 tablet 的位置信息,还包括表结构等信息。Master 本身也依靠 Raft 实现高可用。
基于 Tablet 的分布式存储
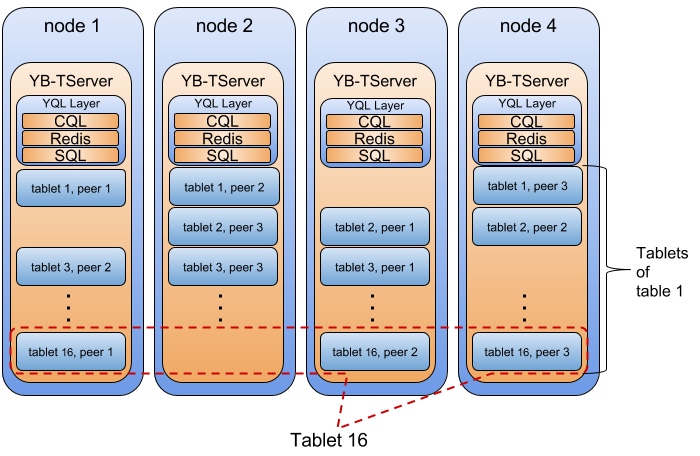
这一部分是 HBase/Spanner 精髓部分,Cockroach/TiDB 的做法几乎也是一模一样的。如下图所示,每张表被分成很多个 tablet,tablet 是数据分布的最小单元,通过在节点间搬运 tablet 以及 tablet 的分裂与合并,就可以实现几乎无上限的 scale out。每个 tablet 有多个副本,形成一个 Raft Group,通过 Raft 协议保证数据的高可用和持久性,Group Leader 负责处理所有的写入负载,其他 Follower 作为备份。
下图是一个例子:一张表被分成 16 个 tablet,tablet 的副本和 Raft Group leader 均匀分布在各个节点上,分别保证了数据的均衡和负载的均衡。
和其他产品一样,Master 节点会负责协调 tablet 的搬运、分裂等操作,保证集群的负载均衡。这些操作是直接基于 Raft Group 实现的。这里就不再展开了。
有趣的是,Yugabyte 采用哈希和范围结合的分区方式:可以只有哈希分区、也可以只有范围分区、也可以先按哈希再按范围分区。之所以这么设计,猜测也是因为 Cassandra 的影响。相比之下,TiDB 和 Cockroach 都只支持范围分区。
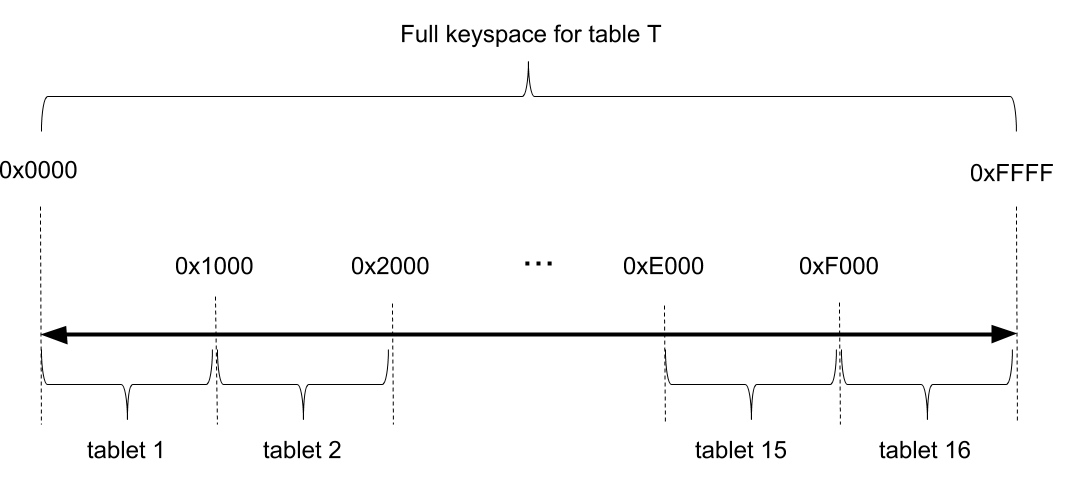
哈希分区的方式是将 key 哈希映射到 2 字节的空间中(即
0x0000到0xFFFF),这个空间又被划分成多个范围,比如下图的例子中被划分为 16 个范围,每个范围的 key 落在一个 tablet 中。理论上说最多可能有 64K 个 tablet,这对实际使用足够了。
哈希分区的好处是插入数据(尤其是从尾部 append 数据)时不会出现热点;坏处是对于小范围的范围扫描(例如
pk BETWEEN 1 AND 10)性能会比较吃亏。基于 RocksDB 的本地存储
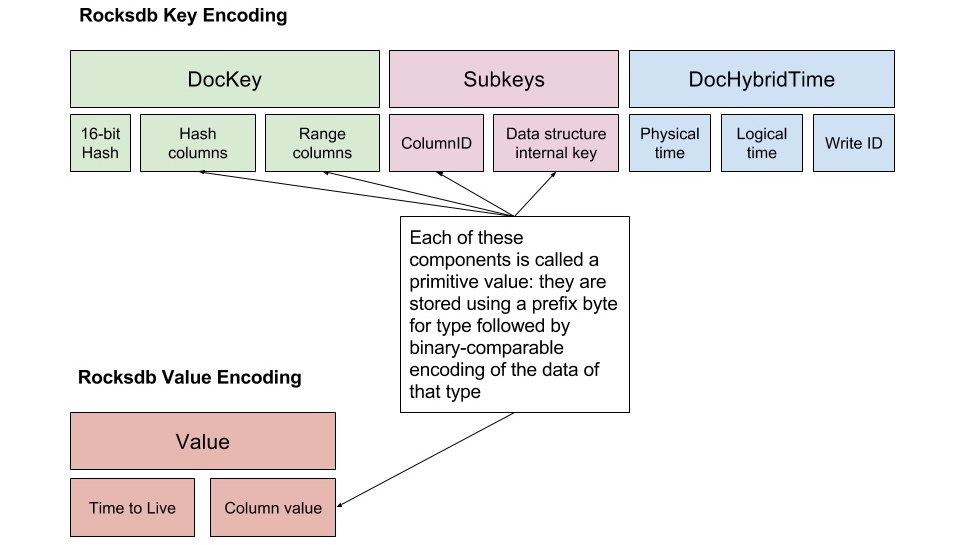
每个 TServer 节点上的本地存储称为 DocDB。和 TiDB/Cockroach 一样,Yugabyte 也用 RocksDB 来做本地存储。这一层需要将关系型 tuple 以及文档编码为 key-value 保存到 RocksDB 中,下图是对文档数据的编码方式,其中有不少是为了兼容 Cassandra 设计的,我们忽略这些,主要关注以下几个部分:
- key 中包含
- 16-bit hash:依靠这个值才能做到哈希分区
- 主键数据(对应图中 hash/range columns)
- column ID:因为每个 tuple 有多个列,每个列在这里需要用一个 key-value 来表示
- hybrid timestamp:用于 MVCC 的时间戳
- value 中包含
- column 的值
如果撇开文档模型,key-value 的设计很像 Cockroach:每个 cell (一行中的一列数据)对应一个 key-value。而 TiDB 是每个 tuple 打包成一个 key-value。个人比较偏好 TiDB 的做法。
分布式事务:2PC & MVCC
和 TiDB/Cockroach 一样,Yugabyte 也采用了 MVCC 结合 2PC 的事务实现。
时间戳
时间戳是分布式事务的关键选型之一。Yugabyte 和 Cockroach 一样选择的是 Hybrid Logical Clock (HLC)。
HLC 将时间戳分成物理(高位)和逻辑(低位)两部分,物理部分对应 UNIX 时间戳,逻辑部分对应 Lamport 时钟。在同一毫秒以内,物理时钟不变,而逻辑时钟就和 Lamport 时钟一样处理——每当发生信息交换(RPC)就需要更新时间戳,从而确保操作与操作之间能够形成一个偏序关系;当下一个毫秒到来时,逻辑时钟部分归零。
不难看出,HLC 的正确性其实是由 Logical Clock 来保证的:它相比 Logical Clock 只是在每个毫秒引入了一个额外的增量,显然这不会破坏 Logical Clock 的正确性。但是,物理部分的存在将原本无意义的时间戳赋予了物理意义,提高了实用性。
个人认为,HLC 是除了 TrueTime 以外最好的时间戳实现了,唯一的缺点是不能提供真正意义上的外部一致性,仅仅能保证相关事务之间的“外部一致性”。另一种方案是引入中心授时节点(TSO),也就是 TiDB 使用的方案。TSO 方案要求所有事务必须从 TSO 获取时间戳,实现相对简单,但引入了更多的网络 RPC,而且 TSO 过于关键——短时间的不可用也是极为危险的。
HLC 的实现中有一些很 tricky 的地方,比如文档中提到的 Safe timestamp assignment for a read request。对于同一事务中的多次 read,问题还要更复杂,有兴趣的读者可以看 Cockroach 团队的这篇博客 Living Without Atomic Clocks。
事务提交
毫不惊奇,Yugabyte 的分布式事务同样是基于 2PC 的。他的做法接近 Cockroach。事务提交过程中,他会在 DocDB 存储里面写入一些临时的记录(provisional records),包括以下三种类型:
- Primary provisional records:还未提交完成的数据,多了一个事务ID,也扮演锁的角色
- Transaction metadata:事务状态所在的 tablet ID。因为事务状态表很特殊,不是按照 hash key 分片的,所以需要在这里记录一下它的位置。
- Reverse Index:所有本事务中的 primary provisional records,便于恢复使用
事务的状态信息保存在另一个 tablet 上,包括三种可能的状态:Pending、Committed 或 Aborted。事务从 Pending 状态开始,终结于 Committed 或 Aborted。
事务状态就是 Commit Point 的那个“开关”,当事务状态切换到 Commited 的一瞬间,就意味着事务的成功提交。这是保证整个事务原子性的关键。
完整的提交流程如下图所示:
另外,Yugabyte 文档中提到它除了 Snapshot Isolation 还支持 Serializable 隔离级别,但是似乎没有看到他是如何规避 Write Skew 问题的。


参考
- Yugabyte DB
- Yugabyte DB Documents
- Living Without Atomic Clocks - Cockroach Labs
- https://ericfu.me/yugabyte-db-introduction/
