immer ,一个不可变数据结构的实现
11 Mar 2019
|
|
why
这篇文章是一个cppcon ppt的阅读记录,没法翻墙看视频有点遗憾。有机会再看视频吧。
在ppt中,作者分析了基于数据变动模型的缺点,变动的数据带来各种各样的引用,导致复杂的数据变化。不变的数据模型才是主流。作者不是想要在c++中实现Haskell数据结构模型,是做了个数据结构式的 git ,这就很有意思了。
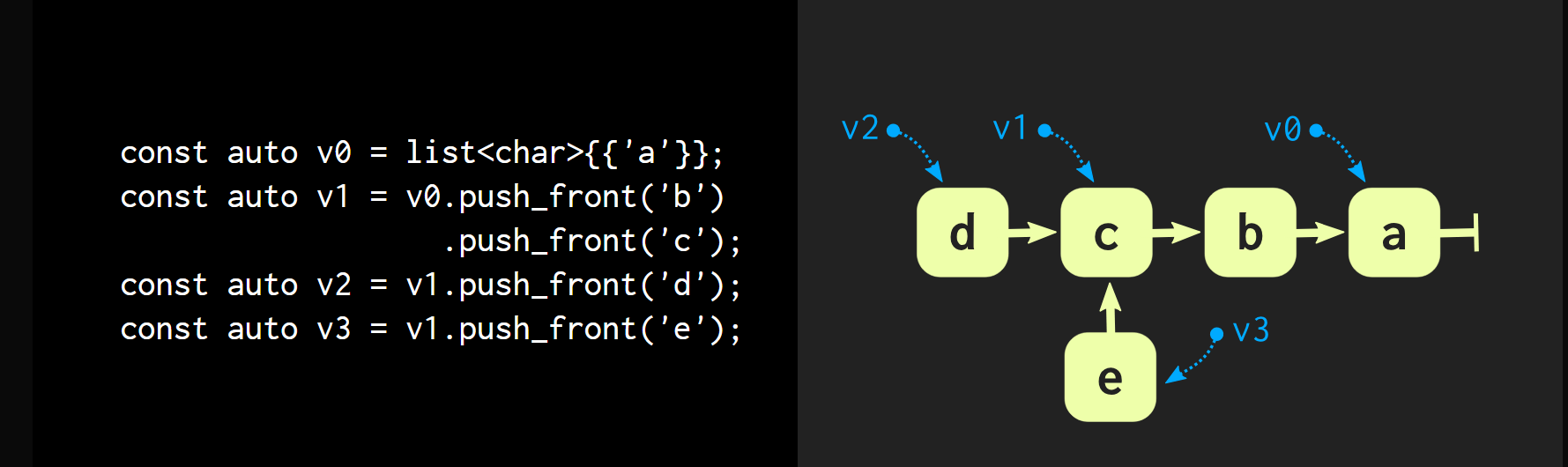
每个vector都算一个snapshot。
咱们先回想一下git是怎么实现的 ->object一个数组存起来,hash kv存起来,每个object有自己的ref链表,构成object链,也就是分支,每个ref到具体的object(对应commit)也就是快照,不可更改
imm 数组看起来很像了。怎么实现呢?
树 ,引用中有很多链接,是作者的思想来源
这个细节我后面单独开帖子分析吧,一时半会写不完感觉
后面的PPT是作者用immer这个库实现一个mvc模式的软件,一个编辑器
mvc的毛病

改进方案
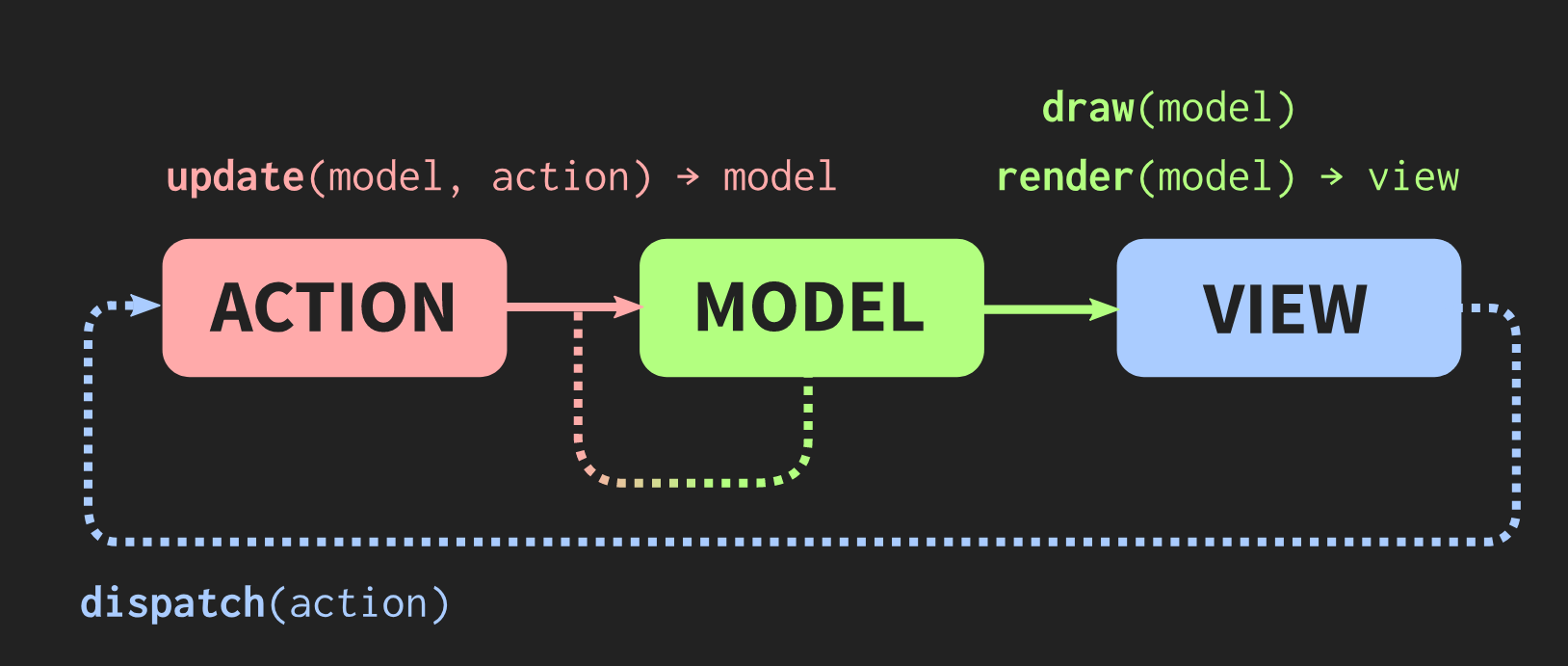
我感觉这个东西就是Immutable.js的思路?
reference
- ppt地址,https://sinusoid.es/talks/immer-cppcon17
- repo地址 https://github.com/arximboldi/immer
- 作者在ppt中列举了这几个链接
- purely functional data structure https://www.cs.cmu.edu/~rwh/theses/okasaki.pdf 这本书似乎没有中文版
- finger tree http://www.staff.city.ac.uk/~ross/papers/FingerTree.html
- Array Mapped Tries. 2000 https://infoscience.epfl.ch/record/64394/files/triesearches.pdf
- RRB-Trees: Efficient Immutable Vectors. 2011https://infoscience.epfl.ch/record/169879/files/RMTrees.pdf
- value identity and state https://www.infoq.com/presentations/Value-Identity-State-Rich-Hickey
和文章没什么关系的to review link
- cpp source https://www.includecpp.org/resources/
- 之前对编译期正则有所耳闻,看这个ppt的时候发现了这个talk,和网站。很牛逼的工作,提了提案 https://compile-time.re
