(转)数据库故障恢复机制的前世今生
转自这个链接 http://mysql.taobao.org/monthly/2019/01/01/
背景
在数据库系统发展的历史长河中,故障恢复问题始终伴随左右,也深刻影响着数据库结构的发展变化。通过故障恢复机制,可以实现数据库的两个至关重要的特性:Durability of Updates以及Failure Atomic,也就是我们常说的的ACID中的A和D。磁盘数据库由于其卓越的性价比一直以来都占据数据库应用的主流位置。然而,由于需要协调内存和磁盘两种截然不同的存储介质,在处理故障恢复问题时也增加了很多的复杂度。随着学术界及工程界的共同努力及硬件本身的变化,磁盘数据库的故障恢复机制也不断的迭代更新,尤其近些年来,随着NVM的浮现,围绕新硬件的研究也如雨后春笋出现。本文希望通过分析不同时间点的关键研究成果,来梳理数据库故障恢复问题的本质,其发展及优化方向,以及随着硬件变化而发生的变化。 文章将首先描述故障恢复问题本身;然后按照基本的时间顺序介绍传统数据库中故障恢复机制的演进及优化;之后思考新硬件带来的机遇与挑战;并引出围绕新硬件的两个不同方向的研究成果;最后进行总结。
问题
数据库系统运行过程中可能遇到的故障类型主要包括,Transaction Failure,Process Failure,System Failure以及Media Failure。其中Transaction Failure可能是主动回滚或者冲突后强制Abort;Process Failure指的是由于各种原因导致的进程退出,进程内存内容会丢失;System Failure来源于操作系统或硬件故障;而Media Failure则是存储介质的不可恢复损坏。数据库系统需要正确合理的处理这些故障,从而保证系统的正确性。为此需要提供两个特性:
- Durability of Updates:已经Commit的事务的修改,故障恢复后仍然存在;
- Failure Atomic:失败事务的所有修改都不可见。
因此,故障恢复的问题描述为:即使在出现故障的情况下,数据库依然能够通过提供Durability及Atomic特性,保证恢复后的数据库状态正确。然而,要解决这个问题并不是一个简单的事情,为了不显著牺牲数据库性能,长久以来人们对故障恢复机制进行了一系列的探索。
Shadow Paging
1981年,JIM GRAY等人在《The Recovery Manager of the System R Database Manager》中采用了一种非常直观的解决方式Shadow Paging[1]。System R的磁盘数据采用Page为最小的组织单位,一个File由多个Page组成,并通过称为Direcotry的元数据进行索引,每个Directory项纪录了当前文件的Page Table,指向其包含的所有Page。采用Shadow Paging的文件称为Shadow File,如下图中的File B所示,这种文件会包含两个Directory项,Current及Shadow。
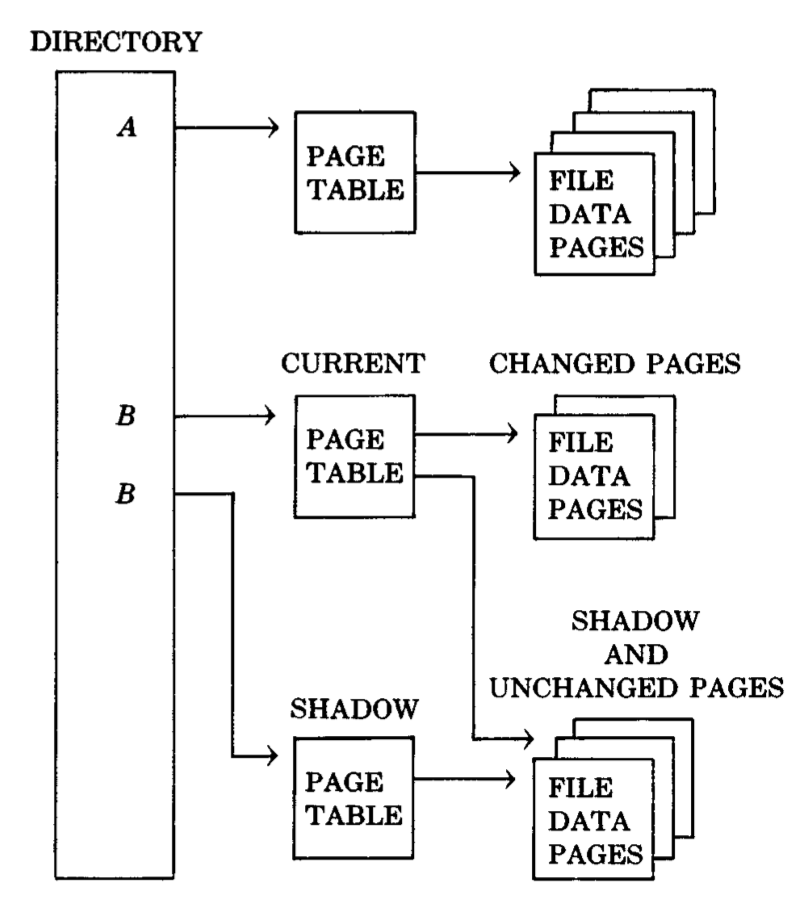
事务对文件进行修改时,会获得新的Page,并加入Current的Page Table,所有的修改都只发生在Current Directory;事务Commit时,Current指向的Page刷盘,并通过原子的操作将Current的Page Table合并到Shadow Directory中,之后再返回应用Commit成功;事务Abort时只需要简单的丢弃Current指向的Page;如果过程中发生故障,只需要恢复Shadow Directory,相当于对所有未提交事务的回滚操作。Shadow Paging很方便的实现了:
- Durability of Updates:事务完成Commit后,所有修改的Page已经落盘,合并到Shadow后,其所有的修改可以在故障后恢复出来。
- Failure Atomic:回滚的事务由于没有Commit,从未影响Shadow Directory,因此其所有修改不可见。
虽然Shadow Paging设计简单直观,但它的一些缺点导致其并没有成为主流,首先,不支持Page内并发,一个Commit操作会导致其Page上所有事务的修改被提交,因此一个Page内只能包含一个事务的修改;其次,不断修改Page的物理位置,导致很难将相关的页维护在一起,破坏局部性;另外,对大事务而言,Commit过程在关键路径上修改Shadow Directory的开销可能很大,同时这个操作还必须保证原子;最后,增加了垃圾回收的负担,包括对失败事务的Current Pages和提交事务的Old Pages的回收。
WAL
由于传统磁盘顺序访问性能远好于随机访问,采用Logging的故障恢复机制意图利用顺序写的Log来记录对数据库的操作,并在故障恢复后通过Log内容将数据库恢复到正确的状态。简单的说,每次修改数据内容前先顺序写对应的Log,同时为了保证恢复时可以从Log中看到最新的数据库状态,要求Log先于数据内容落盘,也就是常说的Write Ahead Log,WAL。除此之外,事务完成Commit前还需要在Log中记录对应的Commit标记,以供恢复时了解当前的事务状态,因此还需要关注Commit标记和事务中数据内容的落盘顺序。根据Log中记录的内容可以分为三类:Undo-Only,Redo-Only,Redo-Undo。
Undo-Only Logging
Undo-Only Logging的Log记录可以表示未<T, X, v>,事务T修改了X的值,X的旧值是v。事务提交时,需要通过强制Flush保证Commit标记落盘前,对应事务的所有数据落盘,即落盘顺序为Log记录->Data->Commit标记。恢复时可以根据Commit标记判断事务的状态,并通过Undo Log中记录的旧值将未提交事务的修改回滚。我们来审视一下Undo-Only对Durability及Atomic的保证:
- Durability of Updates:Data强制刷盘保证,已经Commit的事务由于其所有Data都已经在Commit标记之前落盘,因此会一直存在;
- Failure Atomic:Undo Log内容保证,失败事务的已刷盘的修改会在恢复阶段通过Undo日志回滚,不再可见。
然而Undo-Only依然有不能Page内并发的问题,如果两个事务的修改落到一个Page中,一个事务提交前需要的强制Flush操作,会导致同Page所有事务的Data落盘,可能会早于对应的Log项从而损害WAL。同时,也会导致关键路径上过于频繁的磁盘随机访问。
Redo-Only Logging
不同于Undo-Only,采用Redo-Only的Log中记录的是修改后的新值。对应地,Commit时需要保证,Log中的Commit标记在事务的任何数据之前落盘,即落盘顺序为Log记录->Commit标记->Data。恢复时同样根据Commit标记判断事务状态,并通过Redo Log中记录的新值将已经Commit,但数据没有落盘的事务修改重放。
- Durability of Updates:Redo Log内容保证,已提交事务的未刷盘的修改,利用Redo Log中的内容重放,之后可见;
- Failure Atomic:阻止Commit前Data落盘保证,失败事务的修改不会出现在磁盘上,自然不可见。
Redo-Only同样有不能Page内并发的问题,Page中的多个不同事务,只要有一个未提交就不能刷盘,这些数据全部都需要维护在内存中,造成较大的内存压力。
Redo-Undo Logging
可以看出的只有Undo或Redo的问题,主要来自于对Commit标记及Data落盘顺序的限制,而这种限制归根结底来源于Log信息中对新值或旧值的缺失。因此Redo-Undo采用同时记录新值和旧值的方式,来消除Commit和Data之间刷盘顺序的限制。
- Durability of Updates:Redo 内容保证,已提交事务的未刷盘的修改,利用Redo Log中的内容重放,之后可见;
- Failure Atomic:Undo内容保证,失败事务的已刷盘的修改会在恢复阶段通过Undo日志回滚,不再可见。
如此一来,同Page的不同事务提交就变得非常简单。同时可以将连续的数据攒着进行批量的刷盘已利用磁盘较高的顺序写性能。
Force and Steal
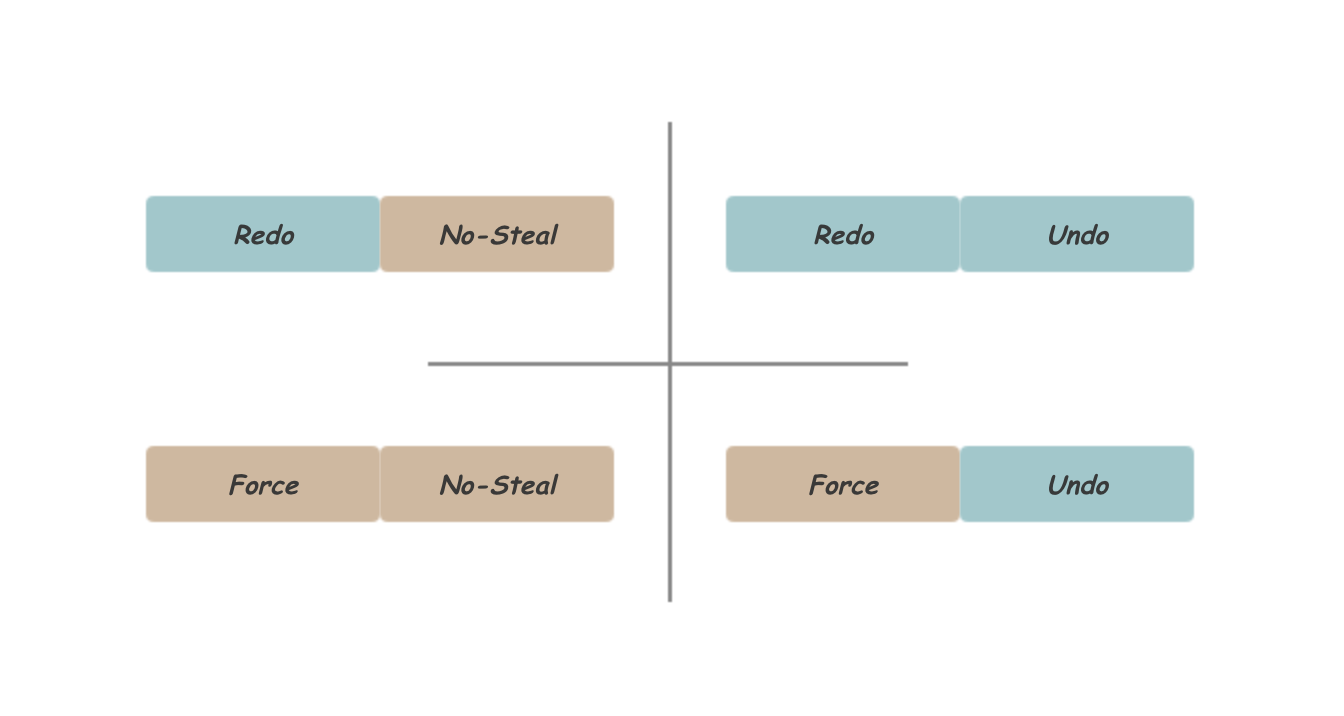
从上面看出,Redo和Undo内容分别可以保证Durability和Atomic两个特性,其中一种信息的缺失需要用严格的刷盘顺序来弥补。这里关注的刷盘顺序包含两个维度:
- Force or No-Force:Commit时是否需要强制刷盘,采用Force的方式由于所有的已提交事务的数据一定已经存在于磁盘,自然而然地保证了Durability;
- No-Steal or Steal,Commit前数据是否可以提前刷盘,采用No-Steal的方式由于保证事务提交前修改不会出现在磁盘上,自然而然地保证了Atomic。
总结一下,实现Durability可以通过记录Redo信息或要求Force刷盘顺序,实现Atomic需要记录Undo信息或要求No-Steal刷盘顺序,组合得到如下四种模式,如下图所示:
ARIES,一统江湖
1992年,IBM的研究员们发表了《ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging》[2],其中提出的ARIES逐步成为磁盘数据库实现故障恢复的标配,ARIES本质是一种Redo-Undo的WAL实现。 Normal过程:修改数据之前先追加Log记录,Log内容同时包括Redo和Undo信息,每个日志记录产生一个标记其在日志中位置的递增LSN(Log Sequence Number);数据Page中记录最后修改的日志项LSN,以此来判断Page中的内容的新旧程度,实现幂等。故障恢复阶段需要通过Log中的内容恢复数据库状态,为了减少恢复时需要处理的日志量,ARIES会在正常运行期间周期性的生成Checkpoint,Checkpoint中除了当前的日志LSN之外,还需要记录当前活跃事务的最新LSN,以及所有脏页,供恢复时决定重放Redo的开始位置。需要注意的是,由于生成Checkpoint时数据库还在正常提供服务(Fuzzy Checkpoint),其中记录的活跃事务及Dirty Page信息并不一定准确,因此需要Recovery阶段通过Log内容进行修正。
Recover过程:故障恢复包含三个阶段:Analysis,Redo和Undo。Analysis阶段的任务主要是利用Checkpoint及Log中的信息确认后续Redo和Undo阶段的操作范围,通过Log修正Checkpoint中记录的Dirty Page集合信息,并用其中涉及最小的LSN位置作为下一步Redo的开始位置RedoLSN。同时修正Checkpoint中记录的活跃事务集合(未提交事务),作为Undo过程的回滚对象;Redo阶段从Analysis获得的RedoLSN出发,重放所有的Log中的Redo内容,注意这里也包含了未Commit事务;最后Undo阶段对所有未提交事务利用Undo信息进行回滚,通过Log的PrevLSN可以顺序找到事务所有需要回滚的修改。
除此之外,ARIES还包含了许多优化设计,例如通过特殊的日志记录类型CLRs避免嵌套Recovery带来的日志膨胀,支持细粒度锁,并发Recovery等。[3]认为,ARIES有两个主要的设计目标:
- Feature:提供丰富灵活的实现事务的接口:包括提供灵活的存储方式、提供细粒度的锁、支持基于Savepoint的事务部分回滚、通过Logical Undo以获得更高的并发、通过Page-Oriented Redo实现简单的可并发的Recovery过程。
- Performance:充分利用内存和磁盘介质特性,获得极致的性能:采用No-Force避免大量同步的磁盘随机写、采用Steal及时重用宝贵的内存资源、基于Page来简化恢复和缓存管理。
NVM带来的机遇与挑战
从Shadow Paging到WAL,再到ARIES,一直围绕着两个主题:减少同步写以及尽量用顺序写代替随机写。而这些正是由于磁盘性能远小于内存,且磁盘顺序访问远好于随机访问。然而随着NVM磁盘的出现以及对其成为主流的预期,使得我们必须要重新审视我们所做的一切。相对于传统的HDD及SSD,NVM最大的优势在于:
- 接近内存的高性能
- 顺序访问和随机访问差距不大
- 按字节寻址而不是Block
在这种情况下,再来看ARIES的实现:
- No-force and Steal:同时维护Redo, Undo和数据造成的三倍写放大,来换取磁盘顺序写的性能,但在NVM上这种取舍变得很不划算;
- Pages:为了迁就磁盘基于Block的访问接口,采用Page的存储管理方式,而内存本身是按字节寻址的,因此,这种适配也带来很大的复杂度。在同样按字节寻址的NVM上可以消除。
近年来,众多的研究尝试为NVM量身定制更合理的故障恢复机制,我们这里介绍其中两种比较有代表性的研究成果,MARS希望充分利用NVM并发及内部带宽的优势,将更多的任务交给硬件实现;而WBL则尝试重构当前的Log方式。
MARS
发表在2013年的SOSP上的《“From ARIES to MARS: Transaction support for next-generation, solid-state drives.” 》提出了一种尽量保留ARIES特性,但更适合NVM的故障恢复算法MARS[3]。MARS取消了Undo Log,保留的Redo Log也不同于传统的Append-Only,而是可以随机访问的。如下图所示,每个事务会占有一个唯一的TID,对应的Metadata中记录了Log和Data的位置
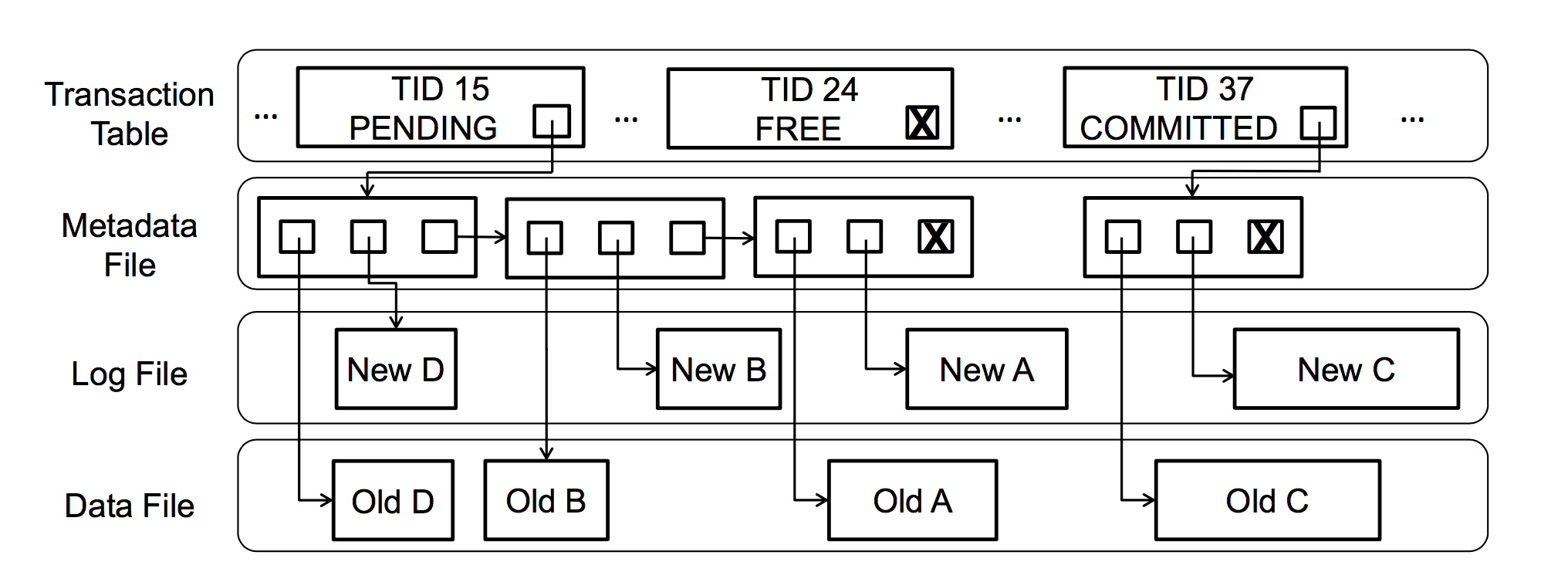
正常访问时,所有的数据修改都在对应的Redo Log中进行,不影响真实数据,由于没有Undo Log,需要采用No-Steal的方式,阻止Commit前的数据写回;Commit时会先设置事务状态为COMMITTED,之后利用NVM的内部带宽将Redo中的所有内容并发拷贝回Metadata中记录的数据位置。如果在COMMITED标记设置后发生故障,恢复时可以根据Redo Log中的内容重放。其本质是一种Redo加No-Steal的实现方式:
- Durability of Updates: Redo实现,故障后重放Redo;
- Failure Atomic:未Commit事务的修改只存在于Redo Log,重启后会被直接丢弃。
可以看出,MARS的Redo虽然称之为Log,但其实已经不同于传统意义上的顺序写文件,允许随机访问,更像是一种临时的存储空间,类似于Shadow的东西。之所以在Commit时进行数据拷贝而不是像Shadow Paging一样的元信息修改,笔者认为是为了保持数据的局部性,并且得益于硬件优异的内部带宽。
WBL
不同于MARS保留Redo信息的思路,2016年VLDB上的《 “Write Behind Logging” 》只保留了Undo信息。笔者认为这篇论文中关于WBL的介绍里,用大量笔墨介绍了算法上的优化部分,为了抓住其本质,这里先介绍最基本的WBL算法:WBL去掉了传统的Append Only的Redo和Undo日志,但仍然需要保留Undo信息用来回滚未提交事务。事务Commit前需要将其所有的修改强制刷盘,之后在Log中记录Commit标记,也就是这里说的Write Behind Log。恢复过程中通过分析Commit标记将为提交的事务通过Undo信息回滚。可以看出WBL算法本身非常简单,在这个基础上,WBL做了如下优化:
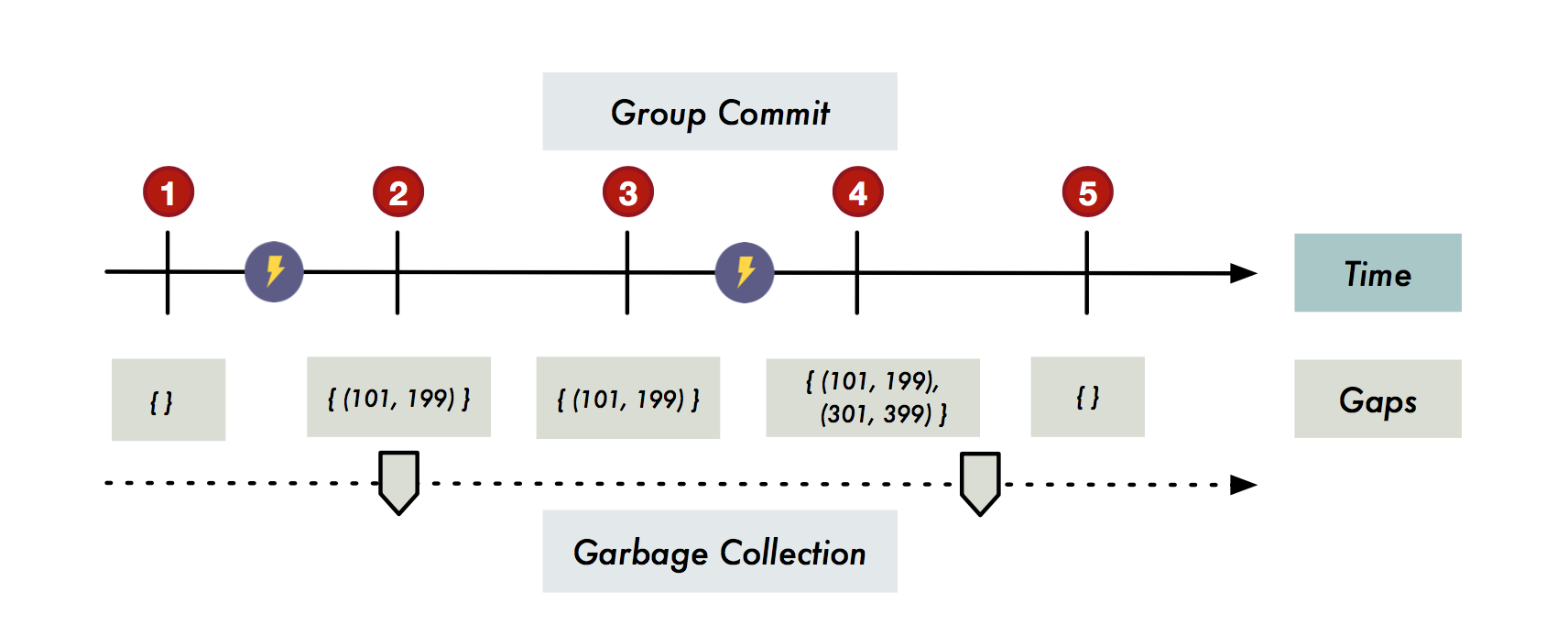
- Group Commit:周期性的检查内存中的修改,同样在所有修改刷盘之后再写Log,Log项中记录Commit并落盘的最新事务TimeStamp cp,保证早于cp的所有事务修改都已经落盘;同时记录当前分配出去的最大TimeStamp cd;也就是说此时所有有修改但未提交的事务Timestamp都落在cp和cd之间。Reovery的时候只需对这部分数据进行回滚;
- 针对多版本数据库,多版本信息已经起到了undo的作用,因此不需要再额外记录undo信息;
- 延迟回滚:Recovery后不急于对未提交事务进行回滚,而是直接提供服务,一组(cp, cd)称为一个gap,每一次故障恢复都可能引入新的gap,通过对比事务Timestamp和gap集合,来判断数据的可见性,需要依靠后台垃圾回收线程真正的进行回滚和对gap的清理,如下图所示;
- 可以看出,WBL本质并没有什么新颖,是一个Force加Undo的实现方式,其正确性保证如下:
- Durability of Updates:Commit事务的数据刷盘后才进行Commit,因此Commit事务的数据一定在Recovery后存在
- Failure Atomic:通过记录的Undo信息或多版本时的历史版本信息,在Recovery后依靠后台垃圾回收线程进行回滚。
总结
数据库故障恢复问题本质是要在容忍故障发生的情况下保证数据库的正确性,而这种正确性需要通过提供Durability of Updates和Failure Atomic来保证。其中Duribility of Update要保证Commit事务数据在恢复后存在,可以通过Force机制或者通过Redo信息回放来保证;对应的,Failure Atomic需要保证未Commit事务的修改再恢复后消失,可以通过No-Steal机制或者通过Undo信息回滚来保证。根据保证Durability和Atomic的不同方式,对本文提到的算法进行分类,如下:
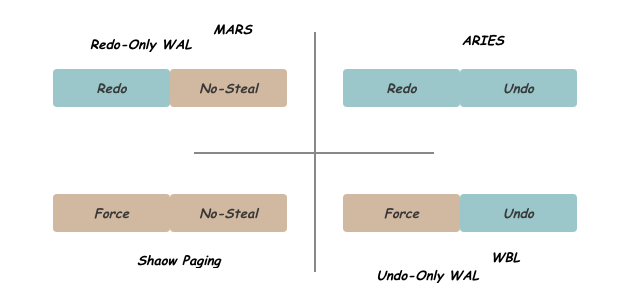
- Shadow Paging可以看做是采用了Force加No-Steal的方式,没有Log信息,在Commit时,通过原子的修改Directory元信息完成数据的持久化更新,但由于其对Page内并发的限制等问题,没有成为主流;
- Logging的实现方式增加了Redo或Undo日志,记录恢复需要的信息,从而放松Force或No-Steal机制对刷盘顺序的限制,从而尽量用磁盘顺序写代替随机写获得较好的性能。ARIES算法是在这一方向上的集大成者,其对上层应用提供了丰富灵活的接口,采用了No-Force加Steal机制,将传统磁盘上的性能发挥到极致,从而成为传统磁盘数据故障恢复问题的标准解决方案;
- 随着NVM设备的逐步出现,其接近内存的性能、同样优异的顺序访问和随机访问表现,以及基于字节的寻址方式,促使人们开始重新审视数据库故障恢复的实现。其核心思路在于充分利用NVM硬件特性,减少Log机制导致的写放大以及设计较复杂的问题;
- MARS作为其中的佼佼者之一,在NVM上维护可以随机访问的Redo日志,同时采用Force加Steal的缓存策略,充分利用NVM优异的随机写性能和内部带宽。
- WBL从另一个方向进行改造,保留Undo信息,采用No-Force加No-Steal的缓存策略,并通过Group Commit及延迟回滚等优化,减少日志信息,缩短恢复时间。
本文介绍了磁盘数据库一路走来的核心发展思路,但距离真正的实现还有巨大的距离和众多的设计细节,如对Logical Log或Physical Log的选择、并发Recovery、Fuzzy Checkpoing、Nested Top Actions等,之后会用单独的文章以InnoDB为例来深入探究其设计和实现细节。
参考
- [1] Gray, Jim, et al. “The recovery manager of the System R database manager.” ACM Computing Surveys (CSUR) 13.2 (1981): 223-242.
- [2] Mohan, C., et al. “ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging.” ACM Transactions on Database Systems (TODS) 17.1 (1992): 94-162.
- [3] Coburn, Joel, et al. “From ARIES to MARS: Transaction support for next-generation, solid-state drives.” Proceedings of the twenty-fourth ACM symposium on operating systems principles. ACM, 2013.
- [4] Arulraj, Joy, Matthew Perron, and Andrew Pavlo. “Write-behind logging.” Proceedings of the VLDB Endowment 10.4 (2016): 337-348.
- [5] Garcia-Molina, Hector. Database systems: the complete book. Pearson Education India, 2008.
- [6] Zheng, Wenting, et al. “Fast Databases with Fast Durability and Recovery Through Multicore Parallelism.” OSDI. Vol. 14. 2014.
- [7] Hellerstein, Joseph M., and Michael Stonebraker, eds. Readings in database systems. MIT Press, 2005.
- [8] http://catkang.github.io/2018/08/31/isolation-level.html
- [9] http://catkang.github.io/2018/09/19/concurrency-control.html
- [10] https://www.classle.net/#!/classle/book/shadow-paging-recovery-technique
