Architecture of a Database System 读书笔记
02 Jan 2017
|
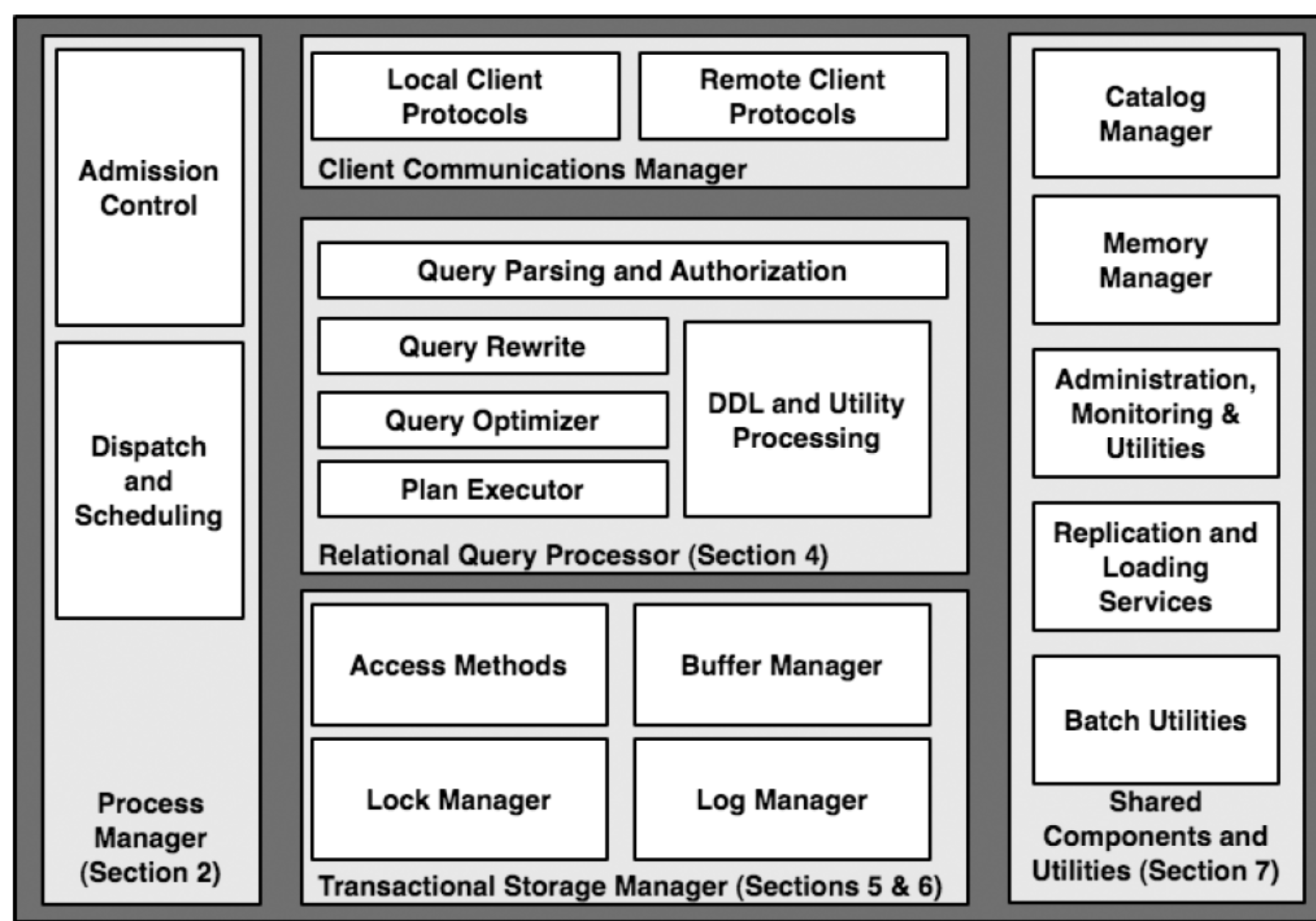
经典架构图
这个小册子主要是介绍涉及到的考察点。各种数据库的实现抉择各有不同
- 架构模型,多进程模式和多线程模式,都是worker池子
- 准入模式 避免页替换过于频繁,限制查询任务个数
- 控制链接个数
- 查询层控制该查询能否执行/推迟,如何控制?
- 确定查询所需磁盘IO
- 根据查询操作判定CPU负载
- 评估数据结构的内存占用 抖动的主要原因
并行架构 进程和内存的协调
- 无共享系统,也就是分布式架构
- 做好分区,不然查询引擎有计算压力
- 分布式事务必须要处理好,否则就是瓶颈
- 分布式死锁检查
- 2PC
- 单点故障处理
- 共享磁盘的多机系统
- 每个机器有自己的内存,所以说内存同步要做好,保证一致性,甚至锁管理上硬件
- NUMA 作者说NUMA, SMP机器没怎么推广,2020了,这种机器到处都是,容器技术遍地开花,有点落后了
关系查询处理器
-
规范化表名 语法检查
-
查询重写
- 视图重写?
- 常量表达式优化
- 谓词逻辑重写
- 语义优化 省掉连接
- 子查询平面化/启发式重写
-
查询优化器
- 拓展
- 计划空间
- 选择性估算
- 搜索算法
- 并发
- 自动调优 根据负载来what-if
- 拓展
-
查询执行器
- 迭代器模型,数据流模型的边
- 迭代器的任何一个子类都可以是其他子类迭代器的输入
class iterator { iterator &inputs[]; void init(); tuple get_next(); void close(); };- 迭代器: 连接了控制流和数据流,不用设计什么队列
- 迭代器只用tuple的描述符,而不是真实数据
- tuple保存在哪里?
- pin in buffer pool 引用计数 内存副本
- 长时间不淘汰反而是瓶颈,如何调整策略最高效?LRU?
- pin in buffer pool 引用计数 内存副本
- 修改看到了自己的更新,导致一个字段被更新多次
- 迭代器模型,数据流模型的边
-
数据仓库 ETL OLTP终点 OLAP
- 数据静态不常变动,位图索引 位图索引适应范围,字段取值简单,不变动,为每个row生成一个属性的bitmap串,多个属性取交集就定位到满足的rowid。
- 缺点,同一属性所有的row更新是相互关联的,因为要生成bitmap索引,非常重,如果是多列索引,更新bitmap索引竞争非常严重
- 加载数据要快
- mvcc历史版本
- 物化视图 加速
- ad-hoc以及雪花式模式查询优化
- 数据静态不常变动,位图索引 位图索引适应范围,字段取值简单,不变动,为每个row生成一个属性的bitmap串,多个属性取交集就定位到满足的rowid。
-
数据库扩展性
-
抽象数据类型
- 函数索引
CREATE INDEX idx1 ON t1 ((col1 + col2)); CREATE INDEX idx2 ON t1 ((col1 + col2), (col1 - col2), col1); -
结构化数据类型 ,xml json
-
全文检索
- 比文本搜索引擎要慢
-
存储管理
- 内存拷贝也会引起延迟??
- 缓存的管理机制,全盘扫会把缓存刷掉,LRU CLOCK表现糟糕
- 查询计划指定缓存替换策略
- LRU-2?
事务 并发控制和恢复
-
lock manager 提供2PL
- 死锁检测,启发式算法?
-
log manager
-
WAL
- 对于数据库页的每一次更新都会产生一个日志记录,在数据库页被刷新到磁盘之 前,该日志记录必须被刷新到日志系统中。
- 数据库日志记录必须按顺序刷新,即在日志记录 r 被刷新时,必须保证所有 r 之前 的日志记录都已经被刷新了。
- 如果一个事务提出提交请求,那么在提交返回成功之前,该提交日志记录必须被刷 新到日志设备上。
-
要求
- 日志顺序号(LSN)
- 支持物理逻辑redo。它是物理的,但在页内它可能是逻辑的。
- 使用脏页表来最大限度地减少恢复时不必要的重做。
- 使用模糊检查点机制,只记录脏页信息和相关的信息,甚至不要求将脏页写到磁盘。不在检查点时将脏页写入磁盘,而是连续地在后台刷新脏页面
-
数据结构
-
LSN 每个日志记录都有一个唯一标识该记录的日志顺序号(LSN, 由一个文件号以及在该文件中的偏移量组成。
-
每一页也维护一个叫页日志顺序号(PageLSN)的标识。每当一个更新操作发生在某页上时,该操作将其日志记录的LSN存储在该页的PageLSN域中。在恢复的撤销阶段,LSN值小于或等于PageLSN值的日志记录将不在该页上执行,因为它的动作已经在该页上了。
-
每个日志记录包含同一事务的前一日志记录的LSN,放在PrevLSN中,使得一个事务可以由后向前提取,而不必读整个日志。事务回滚中会产生一些特殊的redo-only的日志,称为补偿日志记录(Compensation Log Record, CLR)。CLR中还有额外的称为UndoNextLSN的字段,记录下一个需要undo的日志的LSN。
-
-
-
脏页表
- 包含一个在数据库缓冲区中已经更新的页的列表,为每一页保存其PageLSN和一个称为RecLSN的字段。RecLSN用于标识已经实施于该页的磁盘上的版本的日志记录。当某页首次被放入脏页表中,它的RecLSN值被设置为日志的当前末尾。 检查点日志记录
-
包含脏页表和活动事务的列表。
-
恢复算法
- 分析阶段:决定哪些事务要撤销,哪些页在崩溃时是脏的,以及重做阶段应从哪个LSN开始
- 找到最后的完整检查日志记录,将该记录读入脏页表。将redoLSN设为脏页表中页的RecLSN的最小值。
- 将undo-list初始设置为检查点日志记录中的事务列表,从检查点正向扫描,发现新的begin,就加入;发现end,就删去。也记录undo-list每一个事务的最后一个记录,在undo阶段使用。
- 一旦有更新页的记录,不在脏页表,也加入脏页表。
- redo阶段:从分析阶段决定的位置开始,执行重做,将DB恢复到发生崩溃前的状态
- 如果该页不在脏页表中,或者该更新日志记录的LSN小于脏页表中该页的RecLSN,跳过
- 否则从磁盘中调出该页,如果其PageLSN小于该日志记录的LSN,就重做。
- undo阶段:这一阶段回滚在发生崩溃时那些不完全的事务
- 对日志进行一遍反向扫描,对undo-list中的所有事务进行撤销。
- 用分析阶段所记录的每一个事务的最后一个LSN来快速定位。
- 每找到一个更新日志记录,就用它来执行一个undo。产生一个包含undo的CLR,并将该CLR的UndoNextLSN设置为该更新日志记录的PrevLSN。如果遇到一个CLR,它的UndoNextLSN已经指明需要Undo的LSN,且应该已经回滚
- 分析阶段:决定哪些事务要撤销,哪些页在崩溃时是脏的,以及重做阶段应从哪个LSN开始
-
-
io buffer pool
-
组织磁盘数据的访问方法
-
并发控制技术
- 2PL
- MVCC
- OCC
- 冲突较多,回滚灾难
-
索引和日志
- 联结锁(latch-coupling)方案(蟹行协议)?
- 右链接协议?
- next-key 锁定?
-
事务相互依赖
共享组件
- 内存分配器
- 磁盘抽象
- 备份
- 物理备份
- 日志备份
- 基于触发器,重放一份(干脆主从得了)
- 管理监控工具
- 统计信息
- 监控/调优
- 索引性能要好,不然重建索引代价太高
- 备份/导出
- 批量导入
ref
- 搜林子雨就能搜到中文版的pdf
- bitmap索引举例 https://www.cnblogs.com/lbser/p/3322630.html
- 函数索引 https://blog.csdn.net/horses/article/details/85059678
- log技术总结 http://mysql.taobao.org/monthly/2019/01/01/
